






 本文深入解析TextRank算法,一种基于图的排序算法,广泛应用于文本处理,包括关键词提取和摘要生成。TextRank借鉴PageRank原理,通过构建词图或句图,运用迭代方式确定文本中词汇或句子的重要性,实现文本摘要和关键词的高效提取。
本文深入解析TextRank算法,一种基于图的排序算法,广泛应用于文本处理,包括关键词提取和摘要生成。TextRank借鉴PageRank原理,通过构建词图或句图,运用迭代方式确定文本中词汇或句子的重要性,实现文本摘要和关键词的高效提取。
One: TextRank(extract keywords and extract abstract)
-
TextRank 算法是一种用于文本的基于图的排序算法,用来提取文本关键词与摘要。其基本思想来源于谷歌的 PageRank算法, 通过把文本分割成若干组成单元(单词、句子)并建立图模型, 利用投票机制对文本中的重要成分进行排序, 仅利用单篇文档本身的信息即可实现关键词提取、文摘。下面先介绍PageRank*算法。*
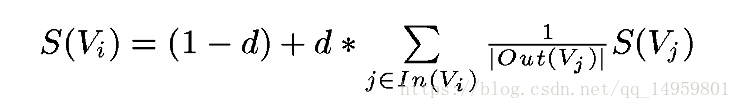
-
S(Vi)表示网页i的重要性即PR值,d是阻尼系数(确保当一个网页没有链接指向它时,也有一定PR值),经验一般设置为0.85,In(Vi)是包含指向网页i的链接的网页集合。Out(Vj)是网页j中指向其他网页的链接的集合,S(Vj)代表网页j的PR值。所以对于一个网页,它的重要性取决于到它的每个链接页面的重要性之和,每个链接到该网页的页面的PR值S(Vj)同时还需要对其他的页面贡献评分,所以除以了|Out(Vj)|。另外,网页的重要性不单单由链接网页决定,还包含一定的概率要不要接受其他网页的重要性评价,这也就是d的作用。
-
初始时,可以将各个网页的重要性值设置为1,PageRank经过多次迭代最终得到结果。公式左边代表迭代后的网页PR值,等号右边的是迭代前的PR值。
-
TextRank提取关键词:
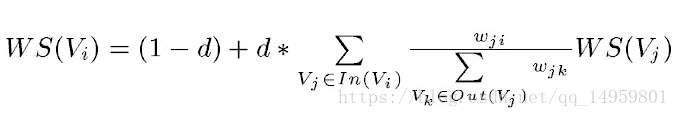
该公式跟PageRank基本相似,其中多了一个重要参数Wji,用来代表两个节点间的重要程度。算法流程如下:将给定的文本分割成句子,T=[S1,S2,…,Sm],然后对每个句子进行分词,得到Si=[pi1,pi2,…,pin],构建词图。设定窗口大小为k,[p1,p2,…,pk][p2,p3,…,pk+1]等都是一个个的窗口,在一个窗口中如果两个单词同时出现,则认为对应单词节点间存在一个边。根据这个思想和公式迭代传播词图中的各节点权重,直至收敛。最后对节点权重进行排序,从而得到最重要的几个单词作为候选关键词。若提取出来的若干关键词在文本中相邻,则构成一个关键短语。 -
TextRank生成摘要:
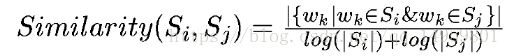
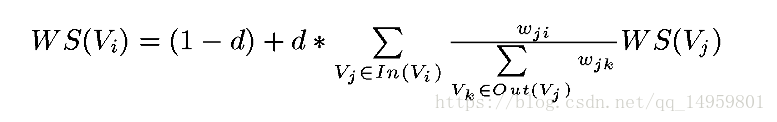
- 将文本中的每个句子看做一个节点,如果两个句子有相似性,则认为两个句子对应的节点之间存在一条无向有权边。句子相似度的计算式子如上所示,Si、Sj两个句子,Wk代表句子中的单词,那么分子代表同时出现在两个句子中的单词的个数,分母是对句子中单词个数求对数之和。分母使用对数可以抵消长句子在相似度计算上的优势(长句子包含相同单词的可能性更高)。根据以上相似度公式循环迭代计算得到任意两个节点之间的相似度,构建节点连接图,最后计算PR值,经排序选出PR值最高的的节点对应的句子作为摘要。
-
核心代码(参考 pytextrank 1.1.0)
在这里插入代码片
- 代码实现参考:
https://pypi.org/project/pytextrank/
https://github.com/SciEvan/TextRank4ZH
https://github.com/summanlp/textrank
参考:

















 1590
1590

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









