




 本文详细介绍了Spark中的行动算子,包括reduce、collect、count、countByKey等常见算子的功能及使用方法,深入解析了takeOrdered、aggregate和fold等算子的内部实现,同时对比了collect.foreach与foreach的区别。
本文详细介绍了Spark中的行动算子,包括reduce、collect、count、countByKey等常见算子的功能及使用方法,深入解析了takeOrdered、aggregate和fold等算子的内部实现,同时对比了collect.foreach与foreach的区别。
Spark Action行动算子
行动算子是触发了整个作业的执行。因为转换算子都是懒加载,并不会立即执行,k行动算子执行后,才会触发计算
1.reduce():聚合
1)函数签名: def reduce(f:(T,T) => T): T
2)功能说明:对RDD中的元素进行聚合
- f函数聚集RDD中的所有元素,先聚合分区内数据,再聚合分区间数据。
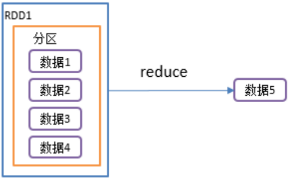
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
val reduceResult: Int = rdd.reduce(_+_)
println(reduceResult) //10
2.collect():以数组的形式返回数据集
1)函数签名: def collect(): Array[T]
2)功能说明:在驱动程序中,以数组Array的形式返回数据集的所有元素。
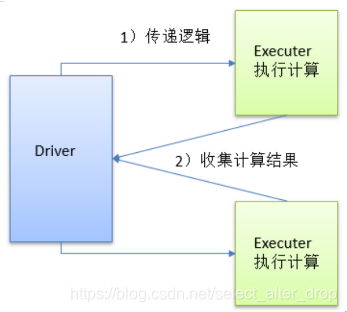
注意:所有的数据都会被拉取到Driver端,谨慎使用
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
//收集数据到Driver
rdd.collect().foreach(println)
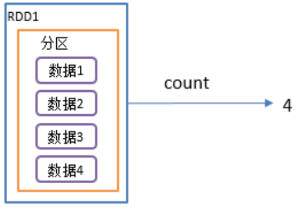
3.count():返回RDD中元素个数
1)函数签名: def count(): Long
2)功能说明:返回RDD中元素的个数.
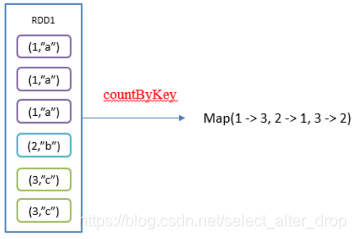
4.countByKey():统计每种key的个数
1)函数签名: def countByKey(): Map[K, Long]
2)功能说明:统计每种key的个数.
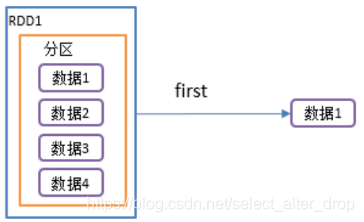
5.first():返回RDD中的第一个元素
1)函数签名: def first(): T
2)功能说明:返回RDD中的第一个元素
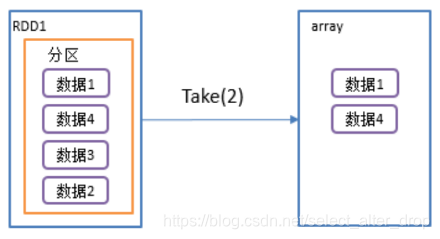
6.take():返回由RDD前n个元素组成的数组
1)函数签名: def take(num: Int): Array[T]
2)功能说明:返回一个由RDD的前n个元素组成的数组。
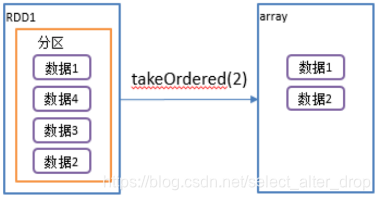
7.takeOrdered():返回该RDD排序后,前n个元素组成的数组
1)函数签名:
def takeOrdered(num: Int)(implicit ord: Ordering[T]): Array[T]
2)功能说明:返回该RDD排序后的前n个元素组成的数组
3)源码分析:
- 如果num值为0,返回空数组
- 创建一个新的RDD:mapRDD
- 如果分区为0,返回空数组
- 否则,将 RDD的整体数据聚合为一个数组,并排序(代码如下)
def takeOrdered(num: Int)(implicit ord: Ordering[T]): Array[T] = withScope {
......
if (mapRDDs.partitions.length == 0) {
Array.empty
} else {
mapRDDs.reduce { (queue1, queue2) =>
queue1 ++= queue2
queue1
}.toArray.sorted(ord)
}
}
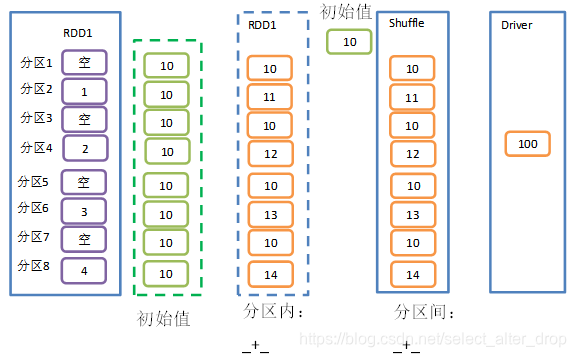
8.aggregate()
1)函数签名:
def aggregate[U: ClassTag](zeroValue: U)(seqOp: (U, T) => U, combOp: (U, U) => U): U
2)功能说明:
- aggregate函数将每个分区里面的元素通过分区内逻辑和初始值进行聚合。
- 然后用分区间逻辑和初始值(zeroValue)进行操作。
- 注意,分区间逻辑再次使用初始值 aggregateByKey是有区别的
- aggregateByKey 处理kv类型的RDD,并且在进行分区间聚合的时候,初始值不参与运算
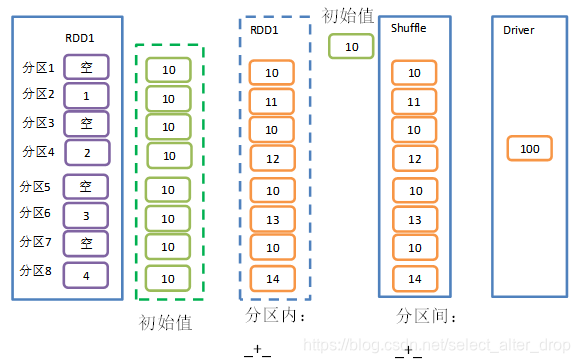
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4),8)
//将该RDD所有元素相加得到结果
//val result: Int = rdd.aggregate(0)(_ + _, _ + _) //结果:10
val result: Int = rdd.aggregate(10)(_ + _, _ + _) //结果:100
9.fold():aggregate的简化版
1)函数签名: def fold(zeroValue: T)(op: (T, T) => T): T
2)功能说明:折叠操作,aggregate的简化操作, 即分区内逻辑和分区间逻斜相同
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4))
//将该RDD所有元素相加得到结果
val foldResult: Int = rdd.fold(0)(_+_)
println(foldResult) //10
10.save相关的算子
- saveAsTextFile
- saveAsObjectFile
- saveAsSequenceFile(只针对KV类型RDD)
1)saveAsTextFile(path):保存成Text文件
功能说明:将数据集的元素以textfile的形式保存到HDFS文件系统或者其他支持的文件系统,对于每个元素,Spark将会调用toString方法,将它装换为文件中的文本
2)saveAsSequenceFile(path) :保存成Sequencefile文件
功能说明:将数据集中的元素以Hadoop Sequencefile的格式保存到指定的目录下,可以使HDFS或者其他Hadoop支持的文件系统。
注意:只有kv类型RDD有该操作,单值的没有
3)saveAsObjectFile(path) 序列化成对象保存到文件
功能说明:用于将RDD中的元素序列化成对象,存储到文件中
11.foreach():遍历RDD中每一个元素
1)函数签名: def foreach(f: T => Unit): Unit
2)功能说明:遍历RDD中的每一个元素,并依次应用f函数
注意:collect.foreach和foreach的区别
*collect.foreach和foreach
1)collect.foreach
- 将每一个Excutor中的数据收集到Driver,形成一个新的
数组Array .foreach不是一个算子,是集合的方法,是对数组中的元素进行遍历
2)foreach:
- 对RDD中的元素进行遍历
- 其本身就是一个行动算子
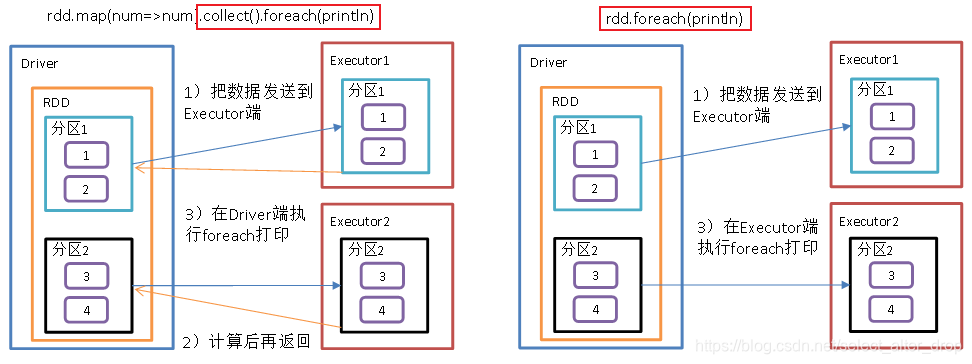
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
//1.收集后打印
//rdd.map(num => num).collect().foreach(println)
val res: Array[Int] = rdd.map(num => num).collect()
res.foreach(println)
println("****************")
//2.分布式打印
rdd.foreach(println)

















 2073
2073

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









