




 本文介绍了Python中的自然语言处理库NLTK的基础使用,包括查看文本内容、频率分布、词汇搭配等操作,并探讨了自然语言处理的难点与应用,如词义消歧、指代消解和语义角色标注等。
本文介绍了Python中的自然语言处理库NLTK的基础使用,包括查看文本内容、频率分布、词汇搭配等操作,并探讨了自然语言处理的难点与应用,如词义消歧、指代消解和语义角色标注等。
第一章节:语言处理与Python
目录
2、查看某个文本中某个词的上下文 text1.concordance("happy")
3、查看和给定词拥有类似上下文的词 text1.similar("happy")
4、找出两个词共同的上下文 text1.common_contexts(["happy","named"])
5、为给定的单词绘制频率分布图 text1.dispersion_plot(["happy","old","sad","mad"])
6、产生和给定文本具有类似风格的随机文本 text1.generate()
10、计算每个词平均使用次数 len(text1)/len(set(text1))
11、计算某个词出现次数与百分比 text1.count("happy") 100*text1.count("happy")/len(text1)
12、链表相加与相乘、添加元素 sent1+sent2 sent1*2 sent1.append("hhh")
13、列表索引、切片 text1[20] sent[1:3]
14、修改列表元素、替换列表片段 sent[0]="first" sent[1:2]=["aa","bb","cc"]
17、链表与字符串的互换 ' '.join(["I","love","money"]) 'I love money'.split()
18、建立频率分布字典 fdist=FreqDist(text1)
20、查看频率最前的20个词语的累积比例 fdist1.plot(20,cumulative=True)
21、找出文本中只出现过一次的词 fdist1.hapaxes()
22、找出文本中词长大于15的词并排序 sorted([x for x in set(text1) if len(x)>15])
sorted([x for x in set(text1) if len(x)>7 and fdist1[x]>7])
24、获取列表中的词语搭配与找到频繁出现的前20个词语搭配 bigrams(["I","love","my","country"]) text1.collocations()
25、创建关于字长的频率分布字典 fdist1=FreqDist([len(w) for w in text1])
26、查看字典中的键值对应,并用列表形式展现 fdist.items()
27、查看字典中拥有最大值的键、查看某个键对应的值、查看某个键的频率百分比 fdist.max() fdist[3] fdist.freq(3)
28、增加fdist内样本 fdist["hhh"]+=200000
32、测试s是否以t开头、结尾、是否包含t "happy".startswith("h") "happy".endswith("h") "h" in "happy"
33、测试s中是否所有均为小写、大写字母,如果是返回TRUE,否则返回FALSE string.islower() string.isupper()
34、将字母全部变成小写、大写 string1.lower() string2.upper()
35、判断s中是否全部都为字母、字母或数字、数字 string3.isalpha() string3.isalnum() string3.isdigit()
36、判断首字母是否为大写 string4.istitle()
NLTK入门
安装nltk并获取所需要的数据,数据在book里(nltk_data的一部分)。
>>>import nltk
>>>nltk.download()python3版本在这里会报错。
解决方案:
1、手动下载nltk.data(链接评论区自取)
2、修改弹出程序的Server index
- 点击file,change server index
- 原有的Server index 换成 “http://www.nltk.org/nltk_data
3、查看Download Directory并将下载的nltk_data解压到该路径
4、点击all packages查看是否为installed,若是则安装成功。
安装成功后即可引用nltk.book
>>>from nltk.book import *
*** Introductory Examples for the NLTK Book ***
Loading text1, ..., text9 and sent1, ..., sent9
Type the name of the text or sentence to view it.
Type: 'texts()' or 'sents()' to list the materials.
text1: Moby Dick by Herman Melville 1851
text2: Sense and Sensibility by Jane Austen 1811
text3: The Book of Genesis
text4: Inaugural Address Corpus
text5: Chat Corpus
text6: Monty Python and the Holy Grail
text7: Wall Street Journal
text8: Personals Corpus
text9: The Man Who Was Thursday by G . K . Chesterton 1908
>>>变量名必须以字母开头,可以包含数字和下划线,大小写敏感
函数合集
1、查看book中text的名称 text1
>>> text1
<Text: Moby Dick by Herman Melville 1851>
>>> text2
<Text: Sense and Sensibility by Jane Austen 1811>
>>>2、查看某个文本中某个词的上下文 text1.concordance("happy")
>>> text1.concordance("happy")
Displaying 8 of 8 matches:
, was called a Cape - Cod - man . A happy - go - lucky ; neither craven nor va
rivers ; through sun and shade ; by happy hearts or broken ; through all the w
most sea - terms , this one is very happy and significant . For the whale is i
ng by way of getting a living . Oh ! happy that the world is such an excellent
e says , Monsieur , that he ' s very happy to have been of any service to us ."
irst love ; we marry and think to be happy for aye , when pop comes Libra , or
, a desperate burglar slid into his happy home , and robbed them all of everyt
rous thing in his soul . That glad , happy air , that winsome sky , did at last
>>>3、查看和给定词拥有类似上下文的词 text1.similar("happy")
>>> text1.similar("happy")
old queer named far ancient well how clear god country taken fat ocean
learned man first white interesting convenient island可用于探索单词的属性,为adj. ?v. ?n.?也可以观察单词可能有的含义与褒贬性。
4、找出两个词共同的上下文 text1.common_contexts(["happy","named"])
>>> text1.common_contexts(["happy","named"])
be_for
>>> text1.common_contexts(["happy","clear"])
very_and5、为给定的单词绘制频率分布图 text1.dispersion_plot(["happy","old","sad","mad"])
>>> text1.dispersion_plot(["happy","old","sad","mad"])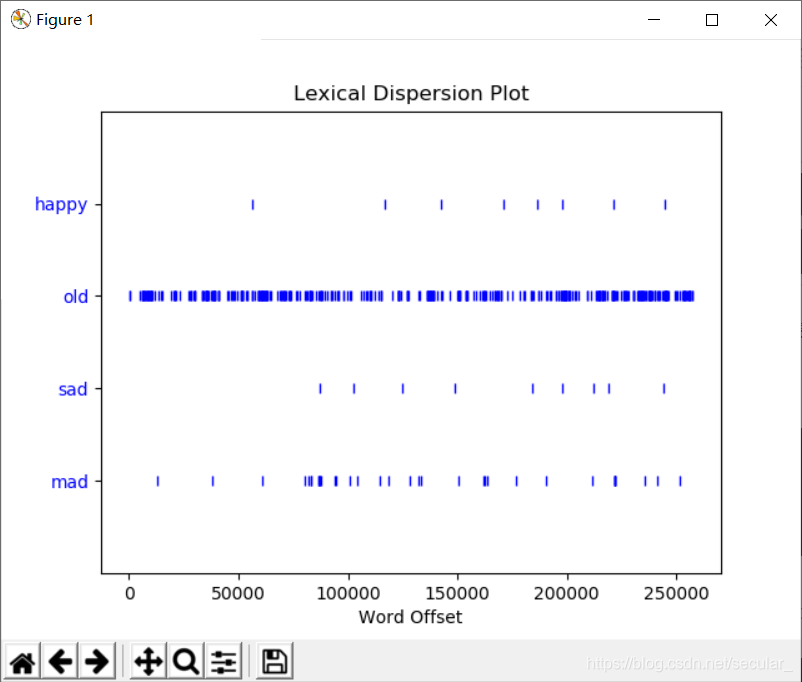
6、产生和给定文本具有类似风格的随机文本 text1.generate()
>>> text1.generate()
Building ngram index...
long , from one to the top - mast , and no coffin and went out a sea
captain -- this peaking of the whales . , so as to preserve all his
might had in former years abounding with them , they toil with their
lances , strange tales of Southern whaling . at once the bravest
Indians he was , after in vain strove to pierce the profundity . ?
then ?" a levelled flame of pale , And give no chance , watch him ;
though the line , it is to be gainsaid . have been
'long , from one to the top - mast , and no coffin and went out a sea\ncaptain -- this peaking of the whales . , so as to preserve all his\nmight had in former years abounding with them , they toil with their\nlances , strange tales of Southern whaling . at once the bravest\nIndians he was , after in vain strove to pierce the profundity . ?\nthen ?" a levelled flame of pale , And give no chance , watch him ;\nthough the line , it is to be gainsaid . have been'7、获取长度 len(text1)
>>> len(text1)
2608198、获取词汇表 set(text1)
>>> set(text1)
{'mountaineers', 'fertility', 'iciness', 'infuriated', 'Hosea', 'Moreover', 'against', 'tallest', 'sinecure', 'unfavourable', 'markest', 'possessions', 'thickness', 'Africa', 'variously', 'elephant', 'attached', 'serene', 'sketches', 'label', 'romantic', 'spat', 'required', 'forebodings', 'AFRICA', 'discriminating', 'heedfulness', 'thoughtfulness', 'infliction', 'permanently', 'GREEK', 'ADDITIONAL', 'adieux', 'forbade', 'proves', 'Bess', 'weep', 'exciting', 'coincidings', 'Giver', 'staving', 'remotest', 'overgrowing', ...}9、对词汇表进行排序 sorted(set(text1))
>>> sorted(set(sent7))
[',', '.', '29', '61', 'Nov.', 'Pierre', 'Vinken', 'a', 'as', 'board', 'director', 'join', 'nonexecutive', 'old', 'the', 'will', 'years']其中sorted()排序是以各种标点符号开始,后接数字,再接字母,大写字母在小写字母前,a在z前。
10、计算每个词平均使用次数 len(text1)/len(set(text1))
>>> len(text1)/len(set(text1))
13.50204483097789611、计算某个词出现次数与百分比 text1.count("happy") 100*text1.count("happy")/len(text1)
>>> text1.count("happy")
8
>>> 100*text1.count("happy")/len(text1)
0.003067261204130067412、链表相加与相乘、添加元素 sent1+sent2 sent1*2 sent1.append("hhh")
>>> sent1
['Call', 'me', 'Ishmael', '.']
>>> sent2
['The', 'family', 'of', 'Dashwood', 'had', 'long', 'been', 'settled', 'in', 'Sussex', '.']
>>> sent1+sent2
['Call', 'me', 'Ishmael', '.', 'The', 'family', 'of', 'Dashwood', 'had', 'long', 'been', 'settled', 'in', 'Sussex', '.']
>>> sent1*2
['Call', 'me', 'Ishmael', '.', 'Call', 'me', 'Ishmael', '.']
>>> sent1.append("hhh")
>>> sent1
['Call', 'me', 'Ishmael', '.', 'hhh'] 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1313
1313



 到【灌水乐园】发言
到【灌水乐园】发言







