




 本文介绍了DataBricks的背景、注册流程、基本使用和与S3的连接。DataBricks是Spark的商业化云服务,提供Notebooks进行数据交互。用户通过注册并创建Notebook与Cluster连接进行数据处理。同时,文章简述了如何在S3上进行只读操作并与DataBricks建立连接。
本文介绍了DataBricks的背景、注册流程、基本使用和与S3的连接。DataBricks是Spark的商业化云服务,提供Notebooks进行数据交互。用户通过注册并创建Notebook与Cluster连接进行数据处理。同时,文章简述了如何在S3上进行只读操作并与DataBricks建立连接。
背景
由于Amazon Cloud需要注册自己的信用卡才能使用,因此课程中使用DataBrick作为替代来学习spark的使用。
DataBrick介绍
Databricks,是属于 Spark 的商业化公司,由美国伯克利大学 AMP 实验室的 Spark 大数据处理系统多位创始人联合创立。Databricks 致力于提供基于 Spark 的云服务,可用于数据集成,数据管道等任务。
Databricks 公司云解决方案的由三部分组成:Databricks 平台、Spark 和 Databricks 工作区。该产品背后的理念是提供处理数据的单独空间,不受托管环境和 Hadoop 集群管理的影响,整个过程在云中完成。该产品有几个核心概念:由 Notebooks 提供一种与数据交互并构建图形的方法,当用户了解了显示数据的方式时,就可以开始构建主控面板以监视某些类型的数据。最后,用户可以通过该平台的任务启动器来规划 Apache Spark 的运行时间。
DataBrick用户注册流程
注册网址 https://databricks.com/try-databricks
https://databricks.com/try-databricks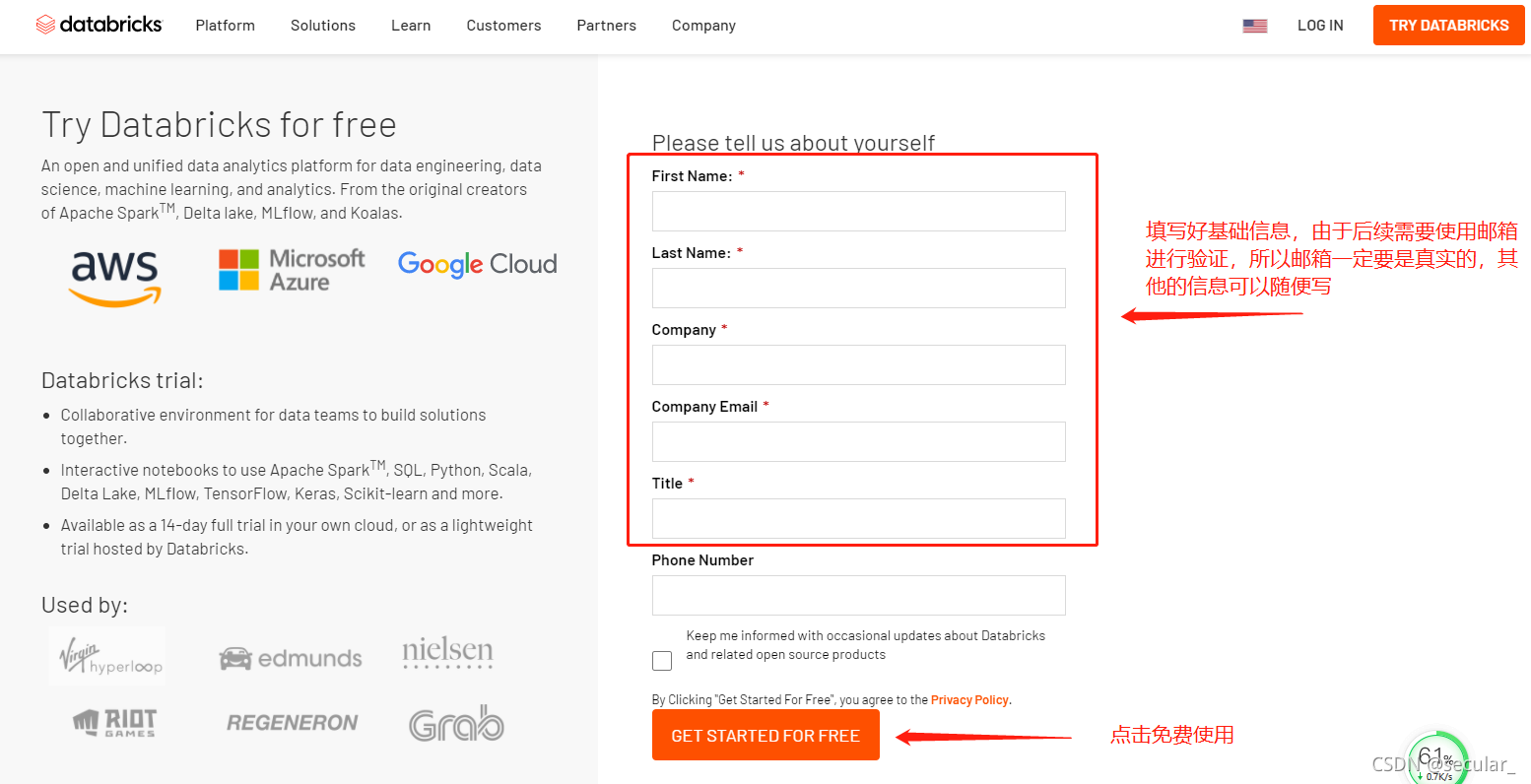
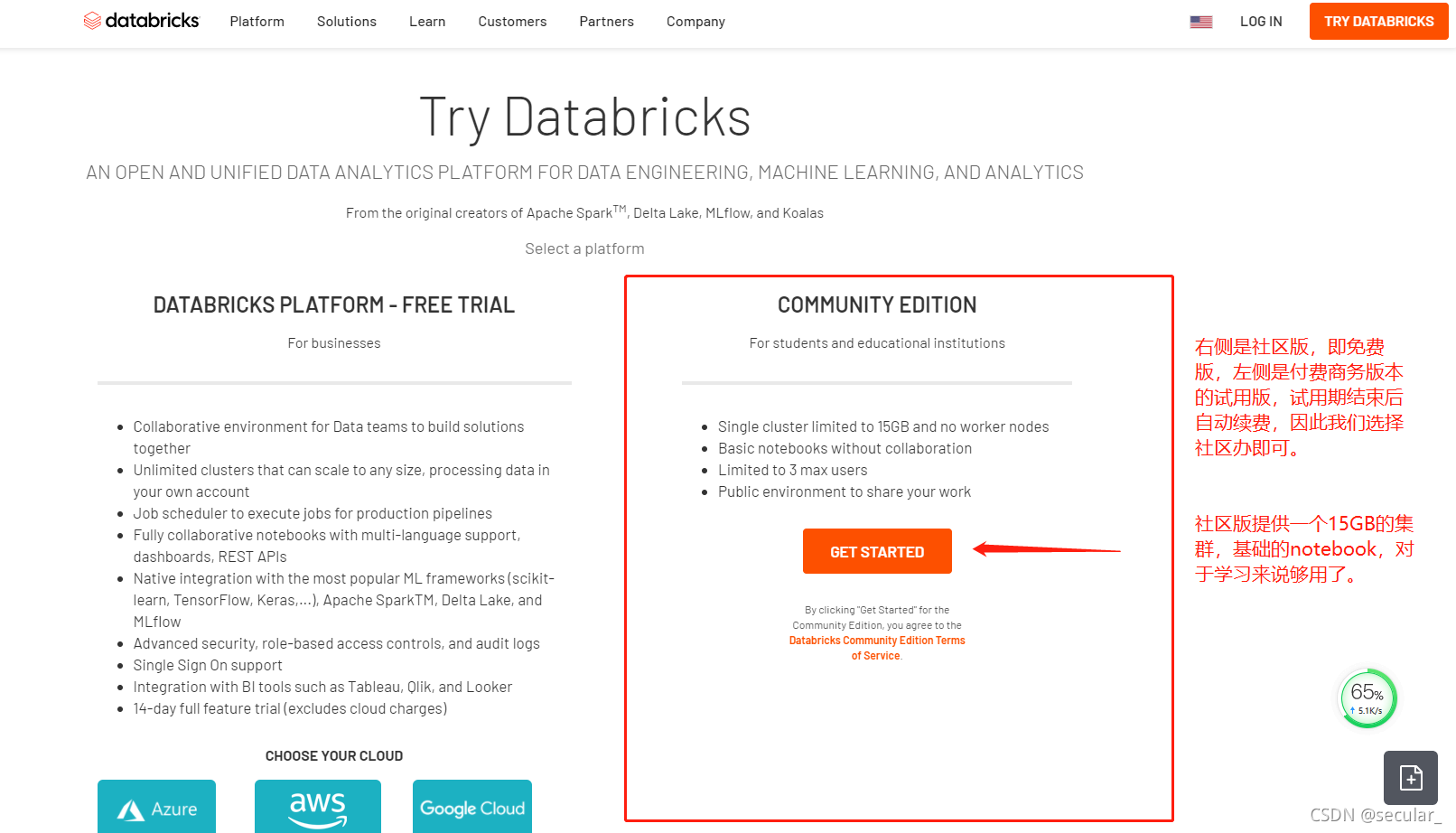
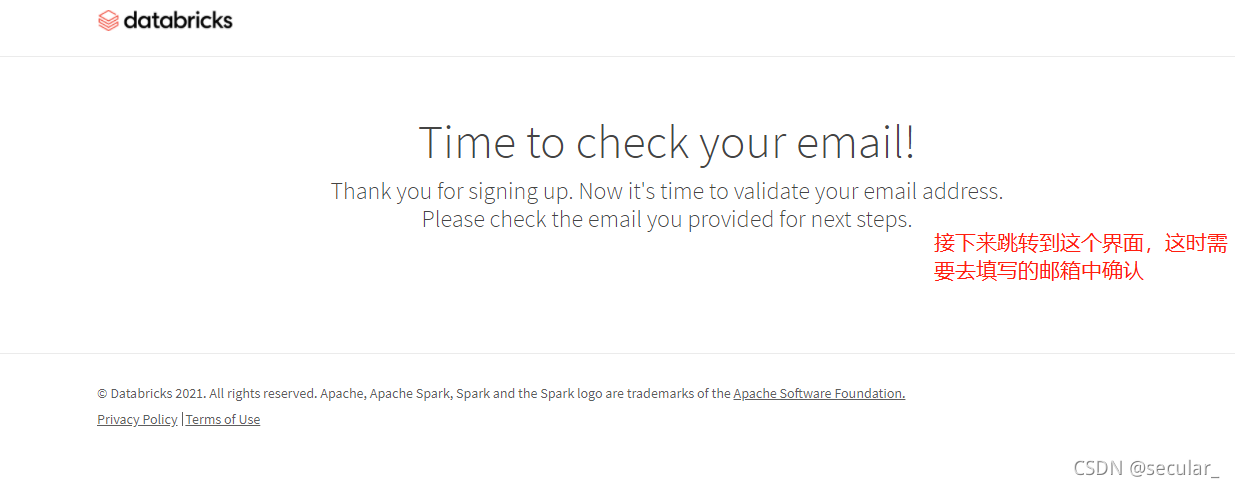

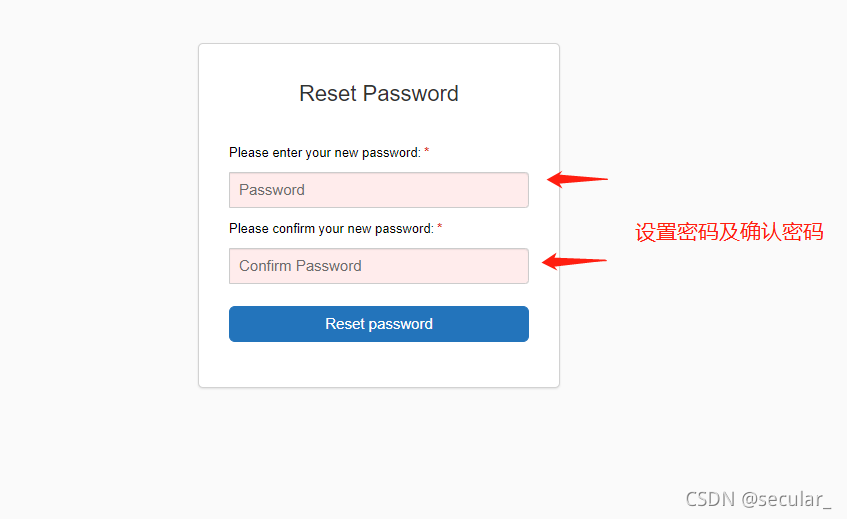
设置好密码以后就会进入使用界面了(注册成功以后登录网址:Databricks - Sign In)
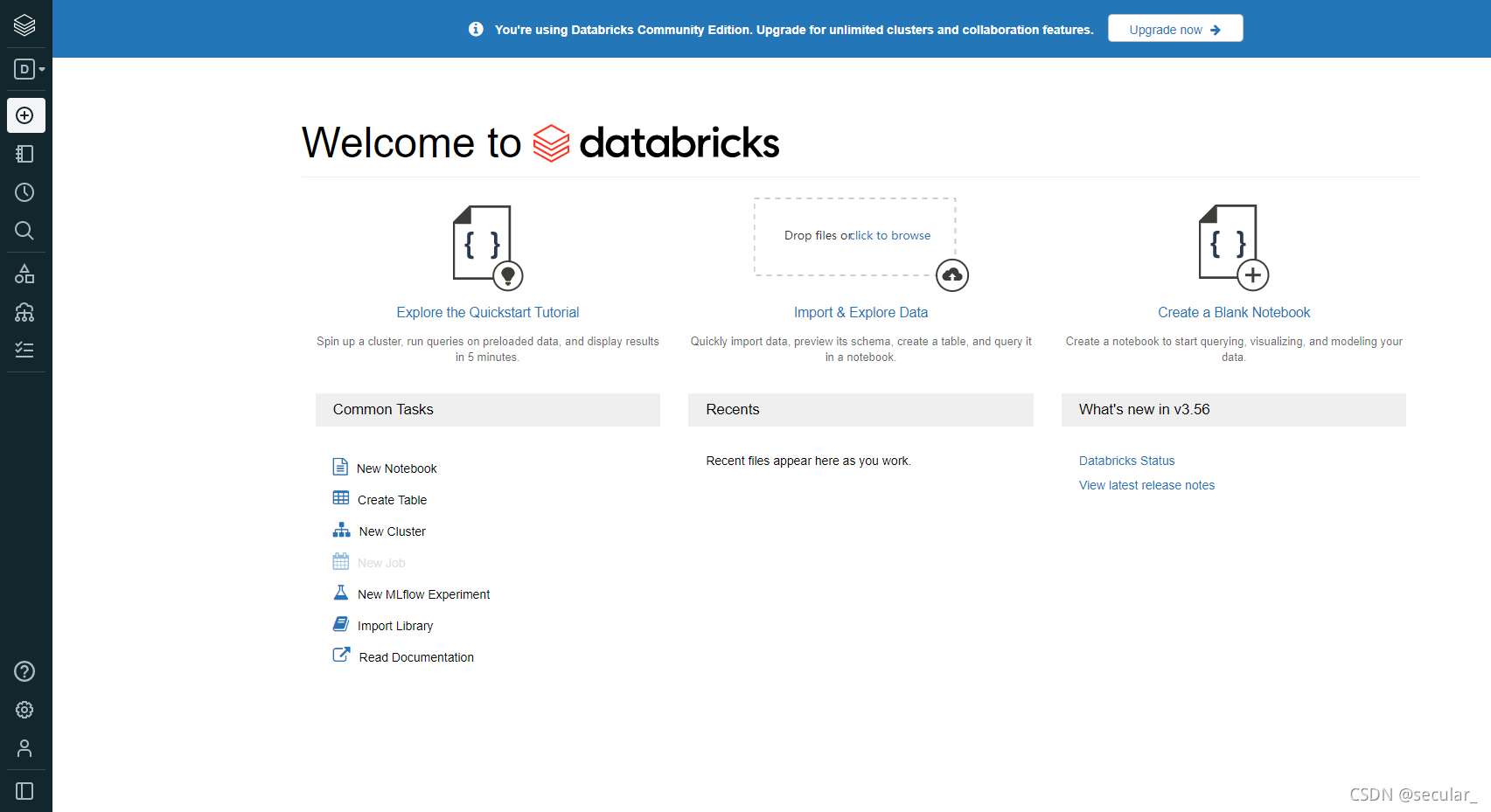
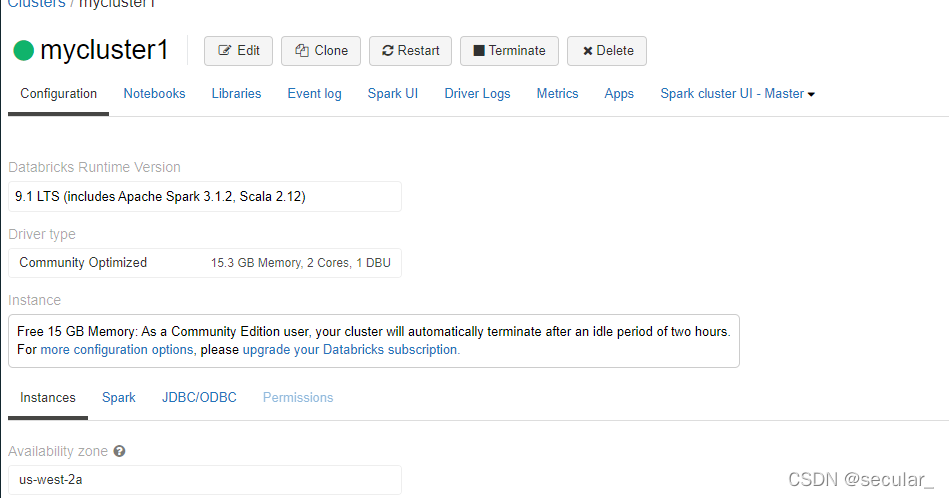
DataBrick基本使用
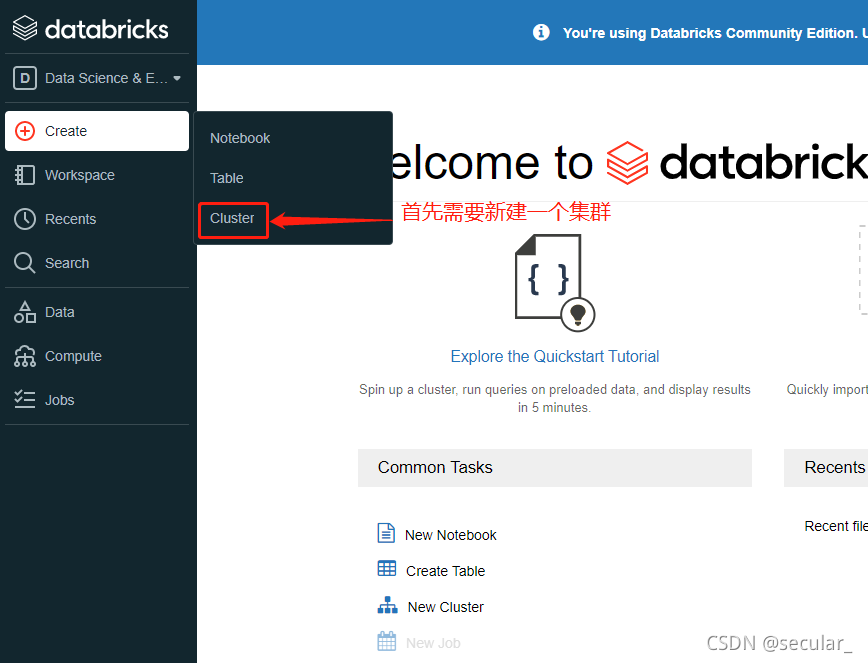
一个cluster相当于一个virtual machine
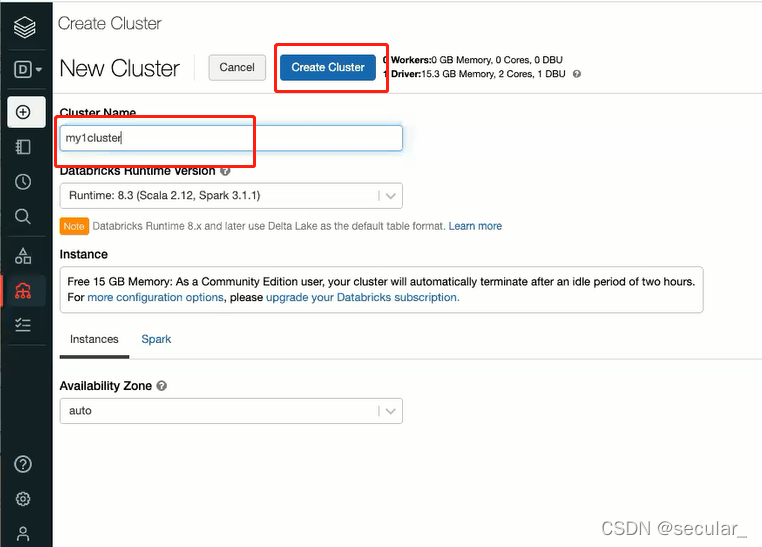
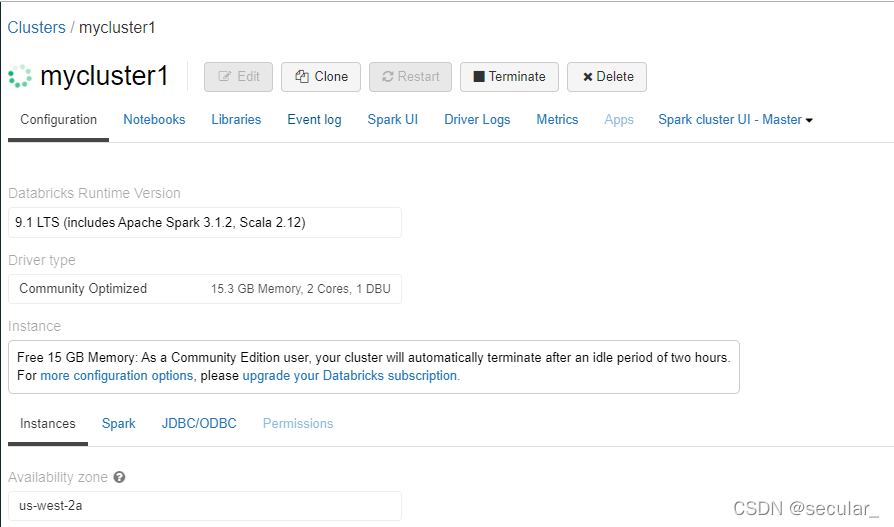
绿色环表示在准备中,准备好了以后就能使用了
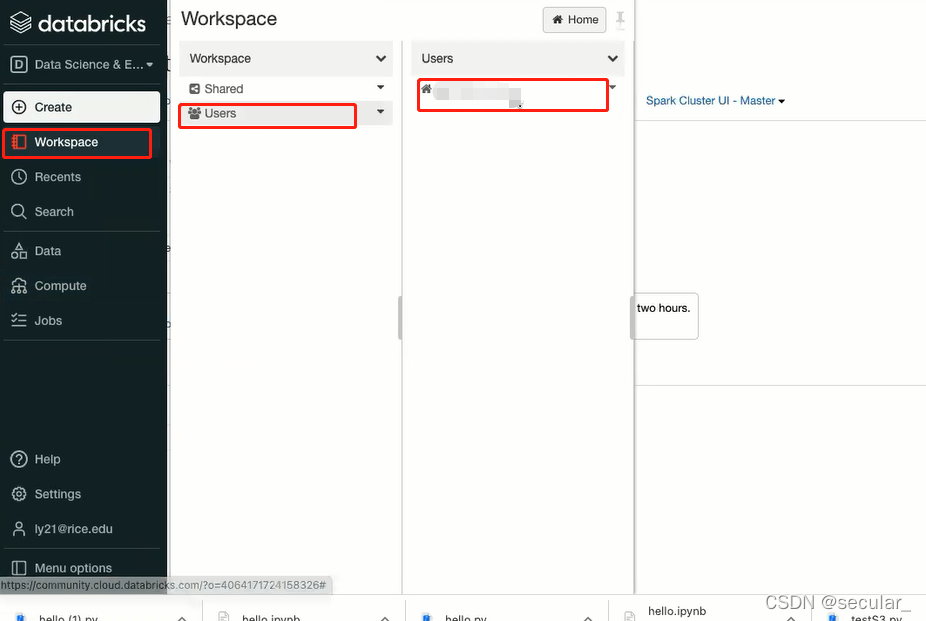
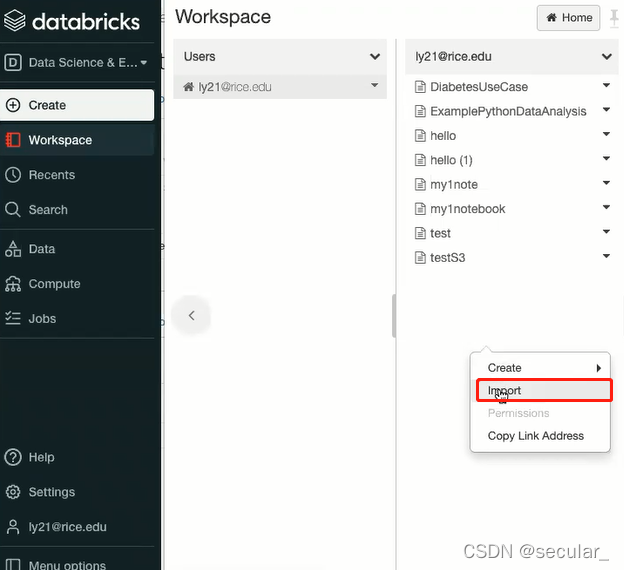
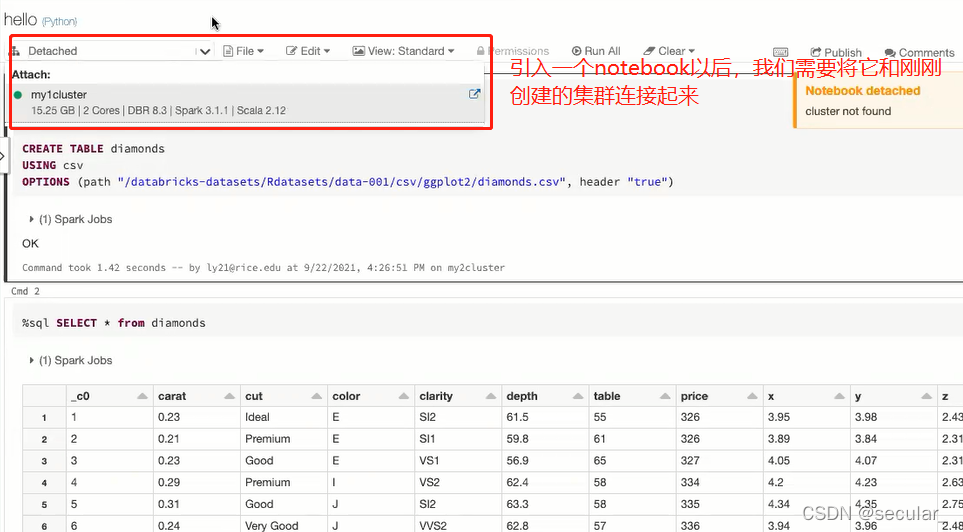
我们需要在我们的workspace里面新建一个notebook,相当于一个interface,用来和集群交互。我们可以通过import方式引入一个已经建好的notebook,
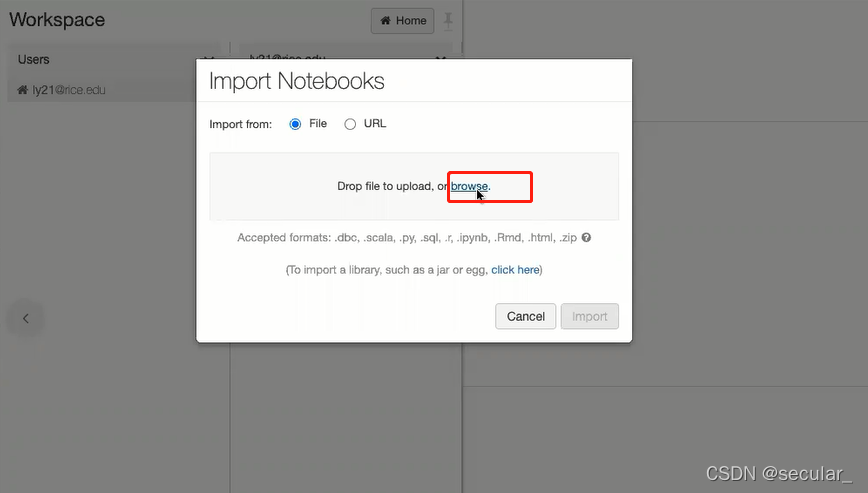
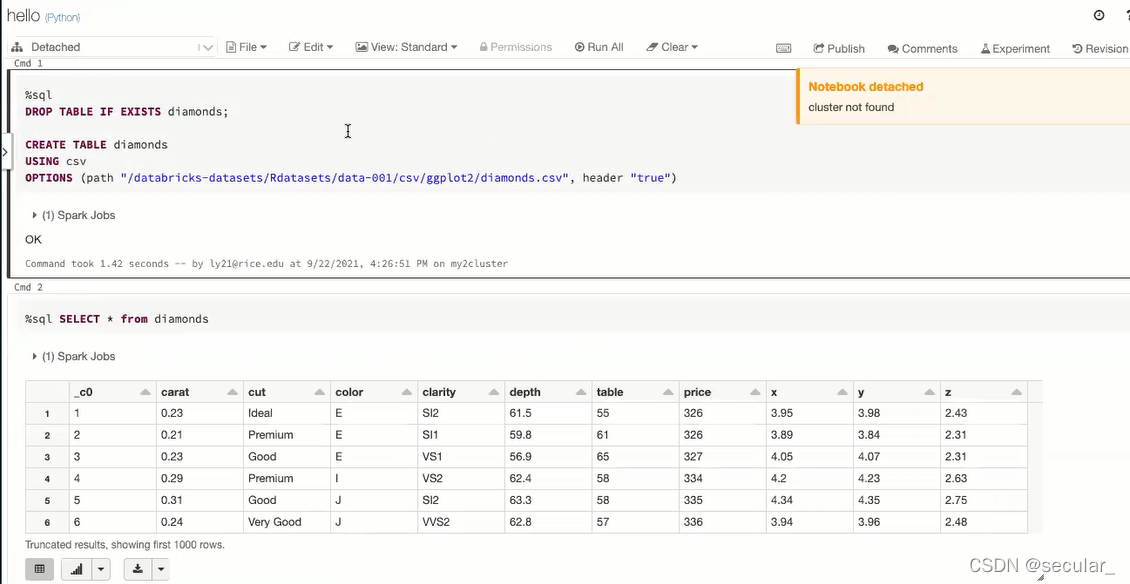
选择集群,点击该集群,使得这个notebook和集群连接。否则代码是跑不起来的
剩下的操作就和在jupyter notebook上差不多。
DataBrick上的编程
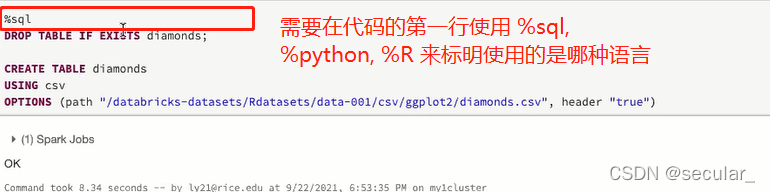
在DataBrick上可以使用三种语言:sql / python / R [除此之外还能使用%fs 来表明使用file system]

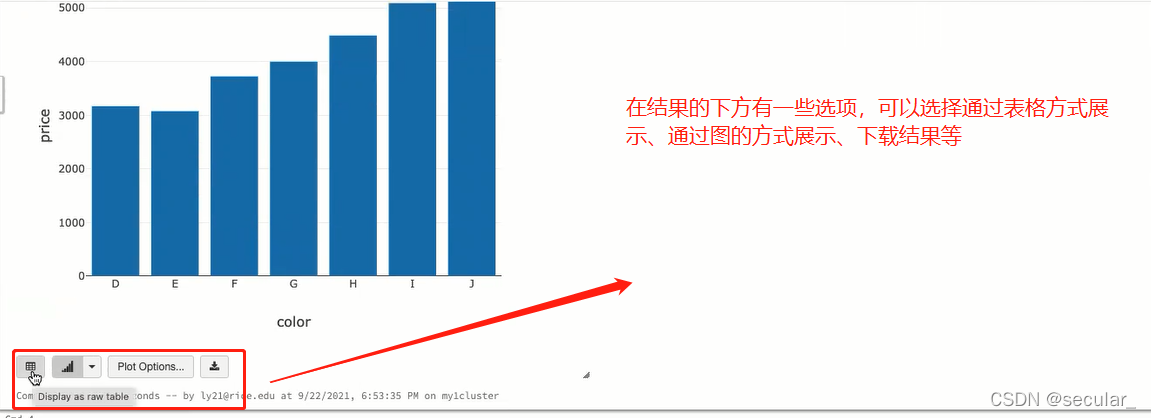
S3基本使用
AWS S3使用需要信用卡,这里只展示下大概使用方式。后续会需要连接S3。
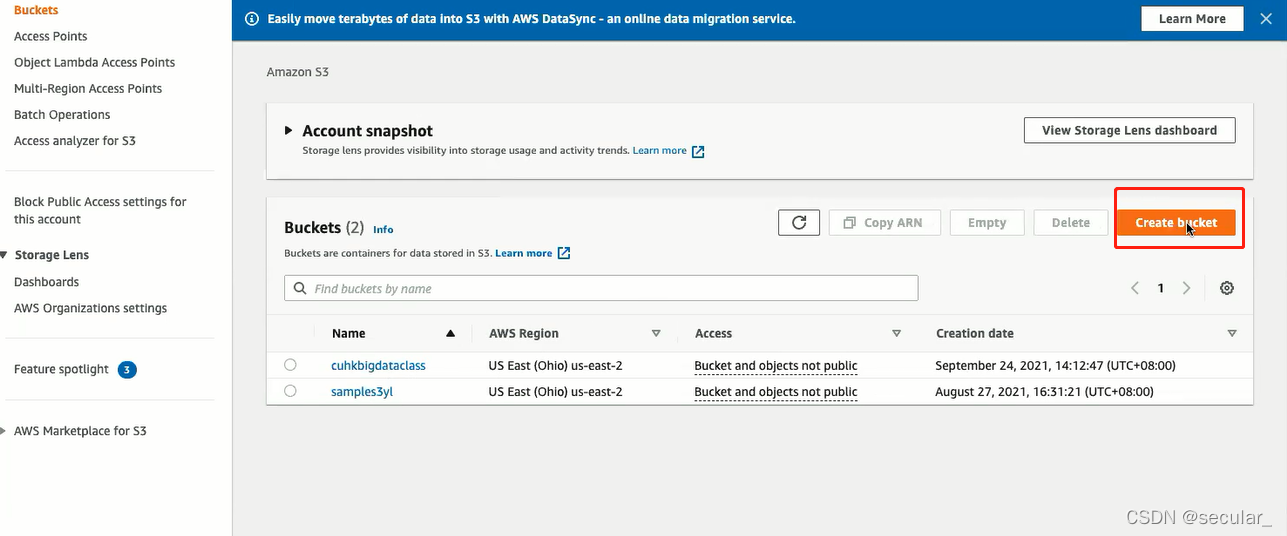
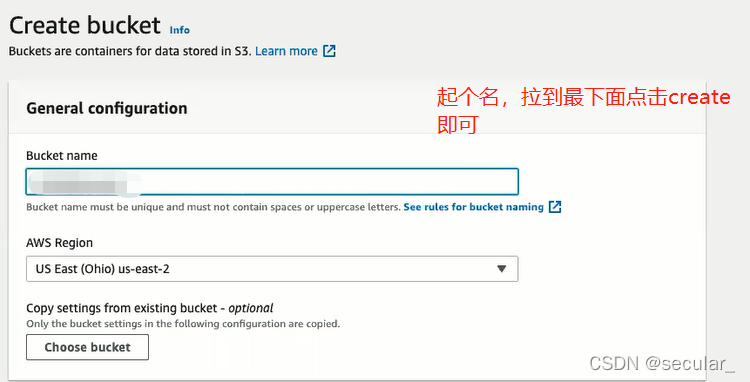
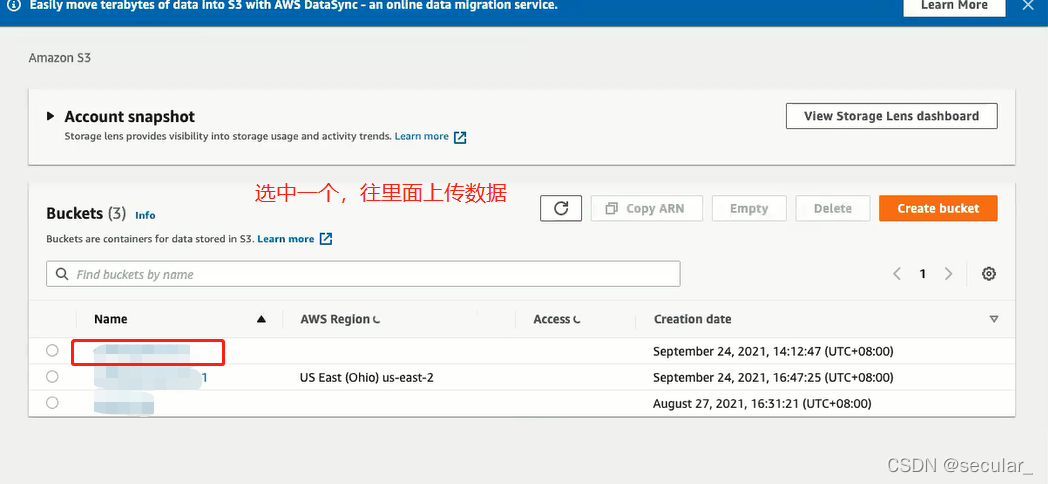
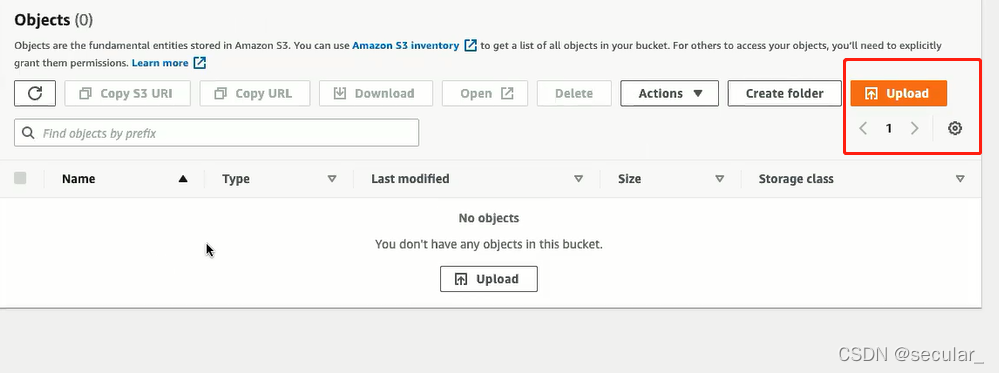
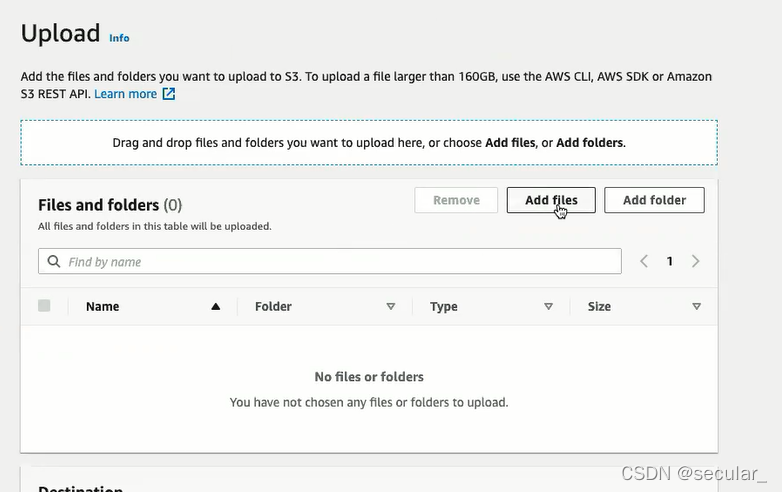
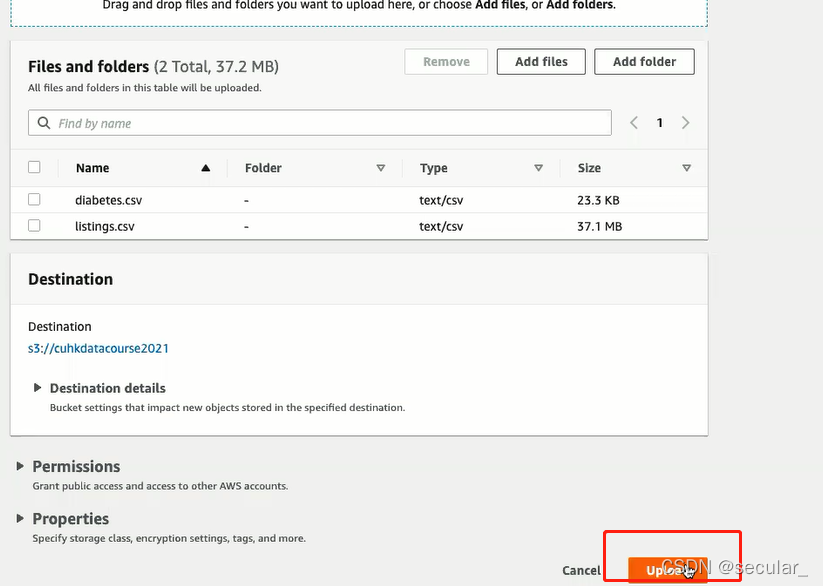
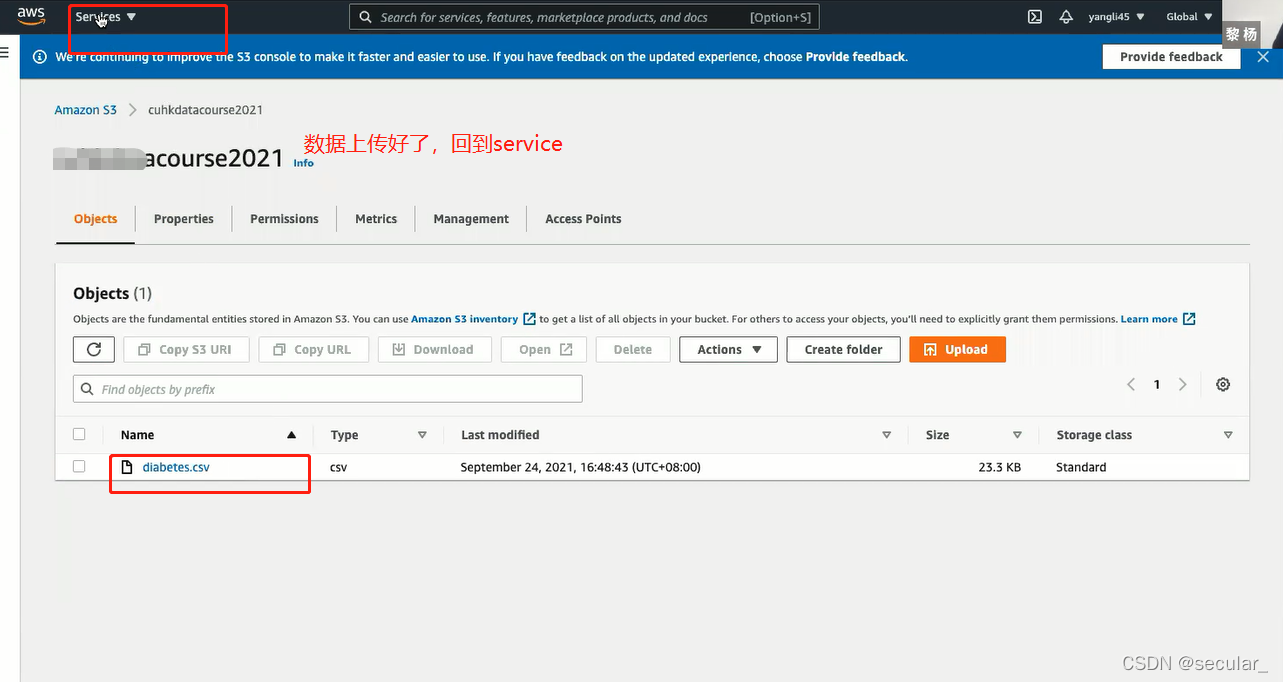
S3相当于一个仓库,现在需要将databricks 和S3连接起来,这需要AWS的IAM(identity access management)
databrick和S3连接
choose IAM service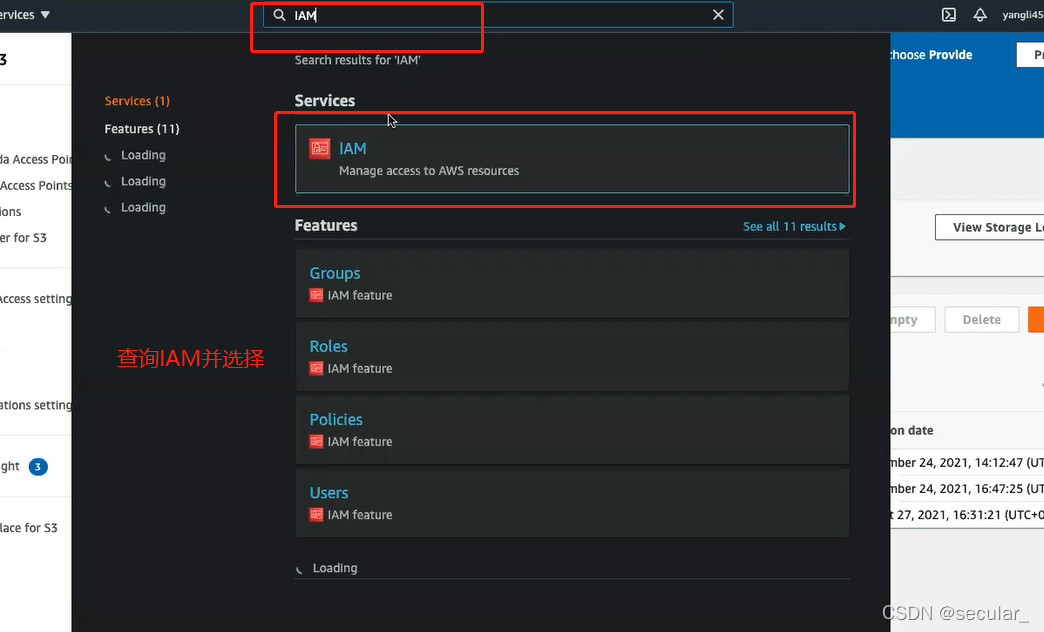
create a user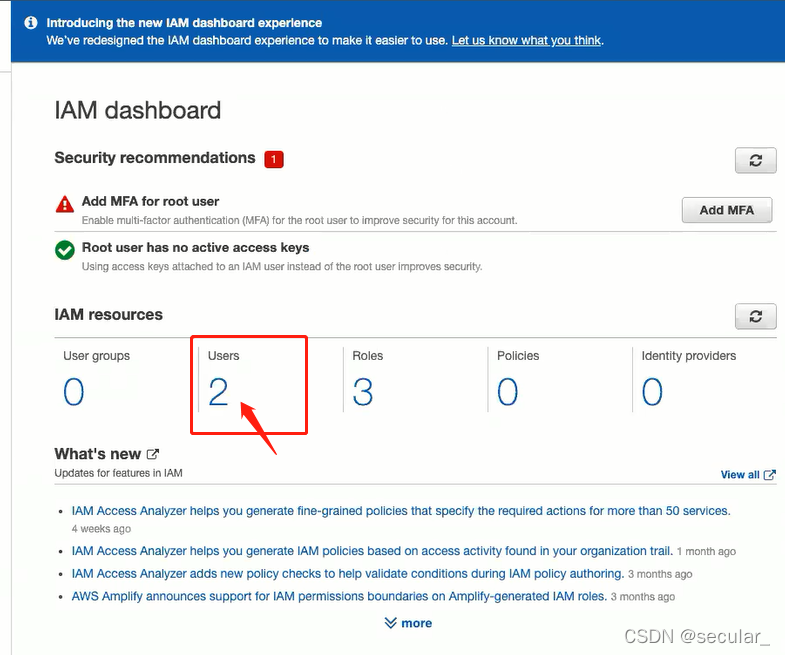
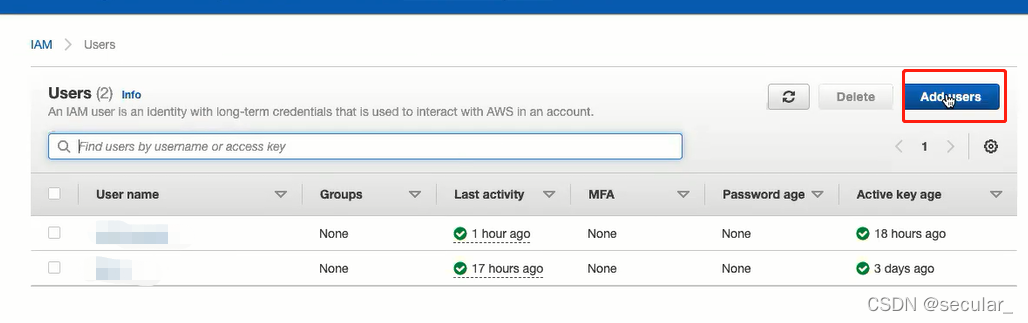 type user name
type user name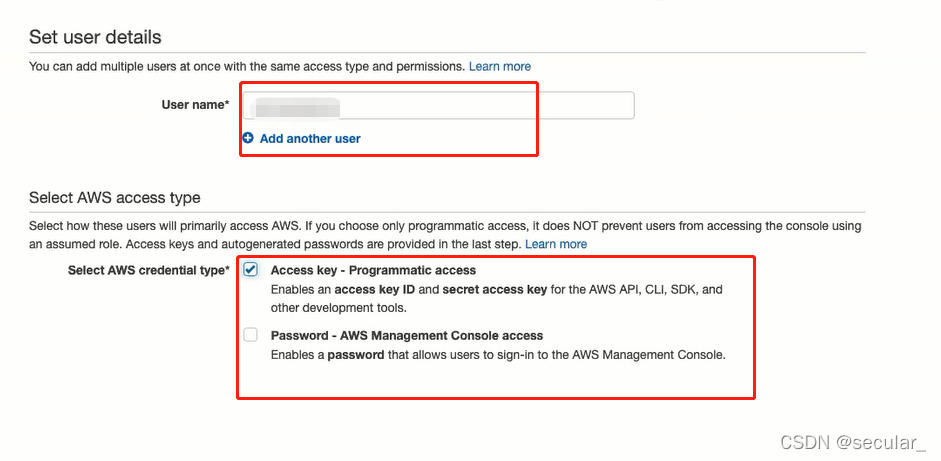
attach policy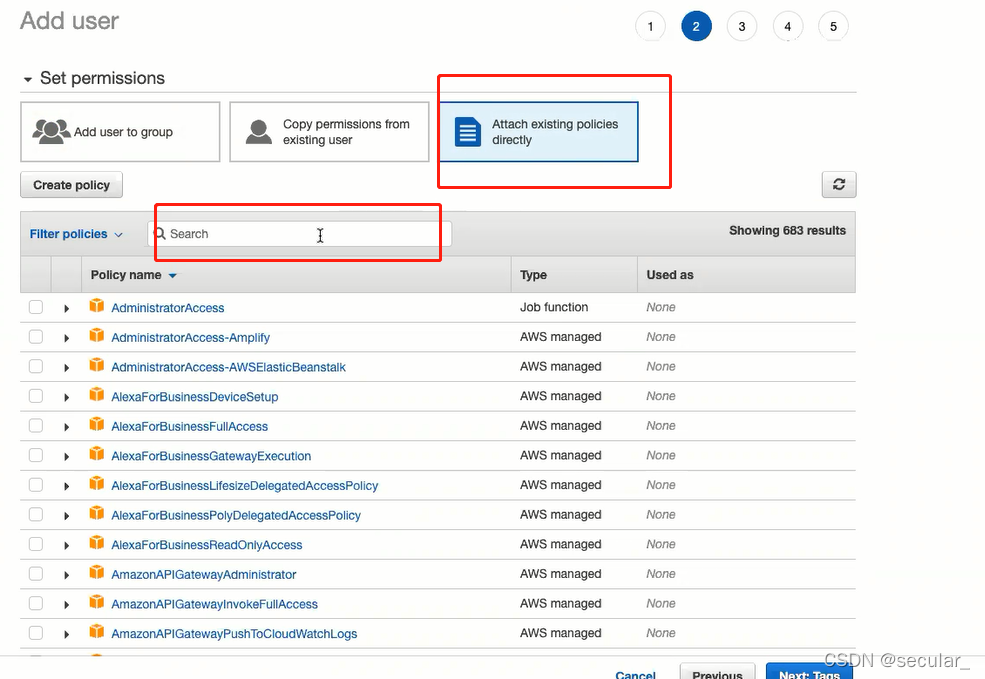
filter readonly access
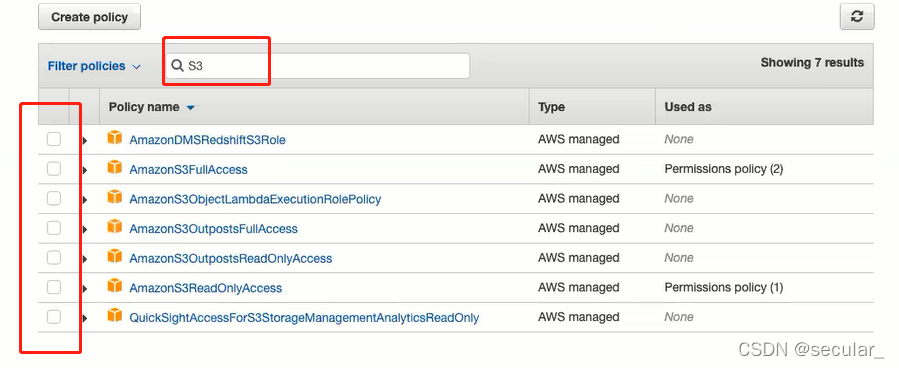 FullAccess:允许用户增删改查 Readonly:只能读数据
FullAccess:允许用户增删改查 Readonly:只能读数据
skip
skip
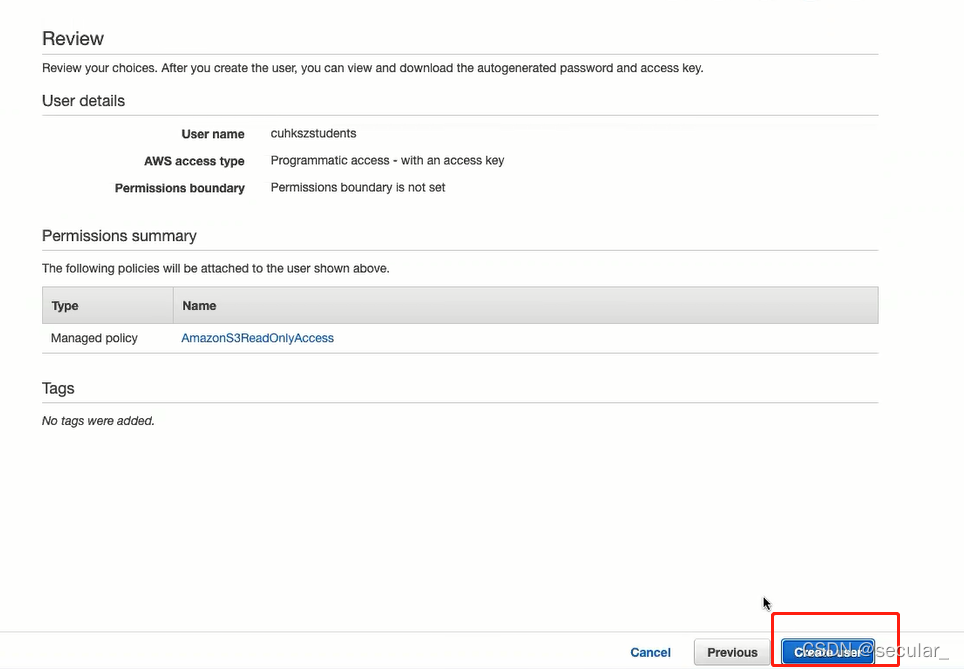 download the csv(最重要的一步) csv里有user ID 和 secret key
download the csv(最重要的一步) csv里有user ID 和 secret key
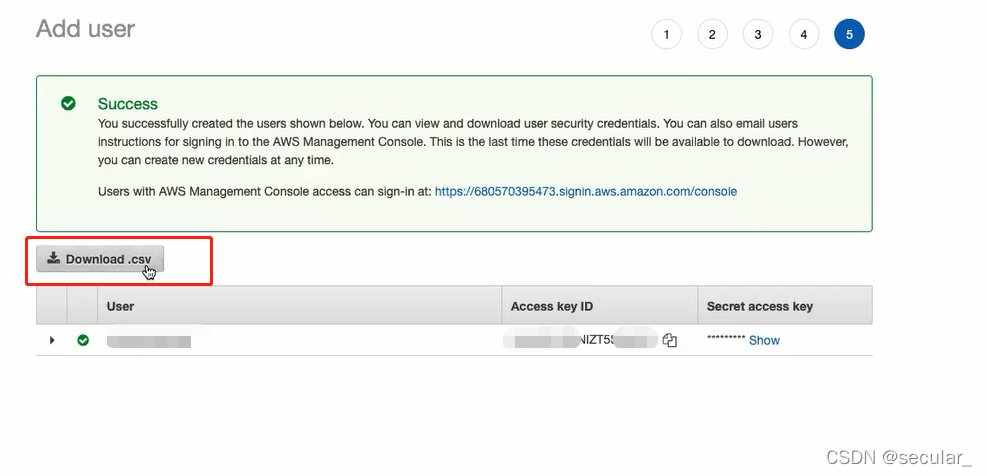
下载的csv如图

现在回到databrick的workspace,找到要连接S3的notebook
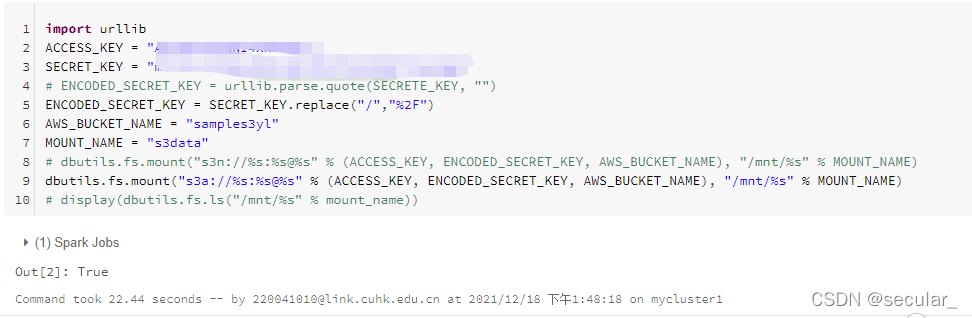
通过python代码来完成连接(需要将刚刚的access key和secret key输入进去)
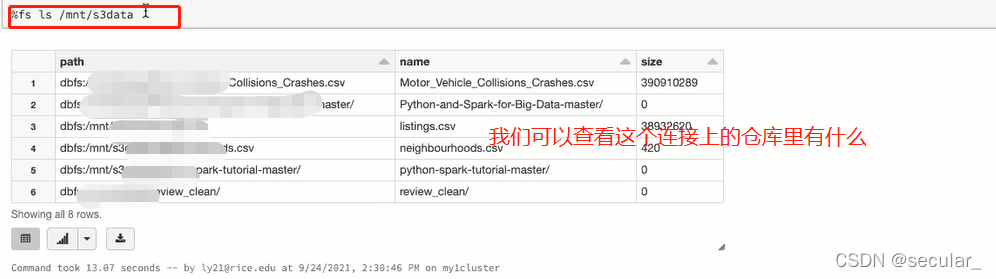
可以通过这条命令查看databricks里的文件目录
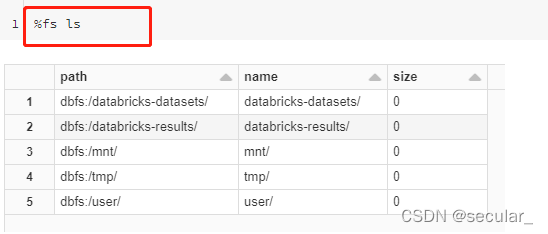
由于我们只有readonly权限,所以是不能在S3里写数据,但是可以在databrick上面写。
也可以在databrick里引入数据
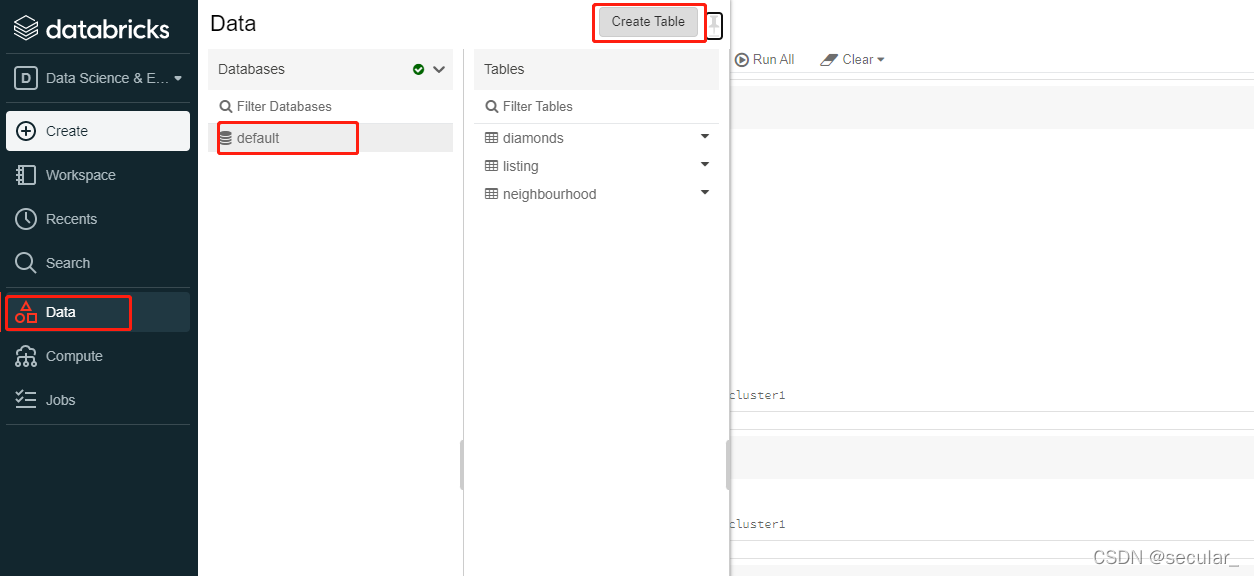
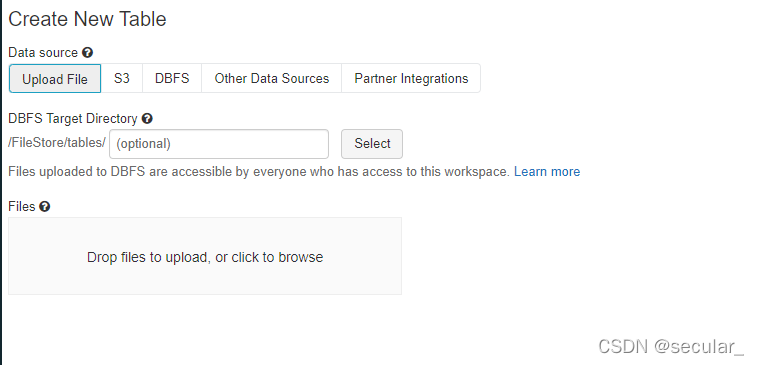
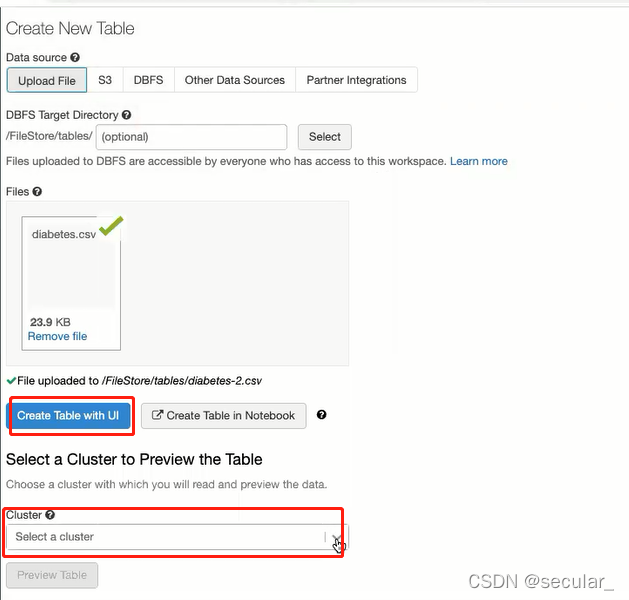
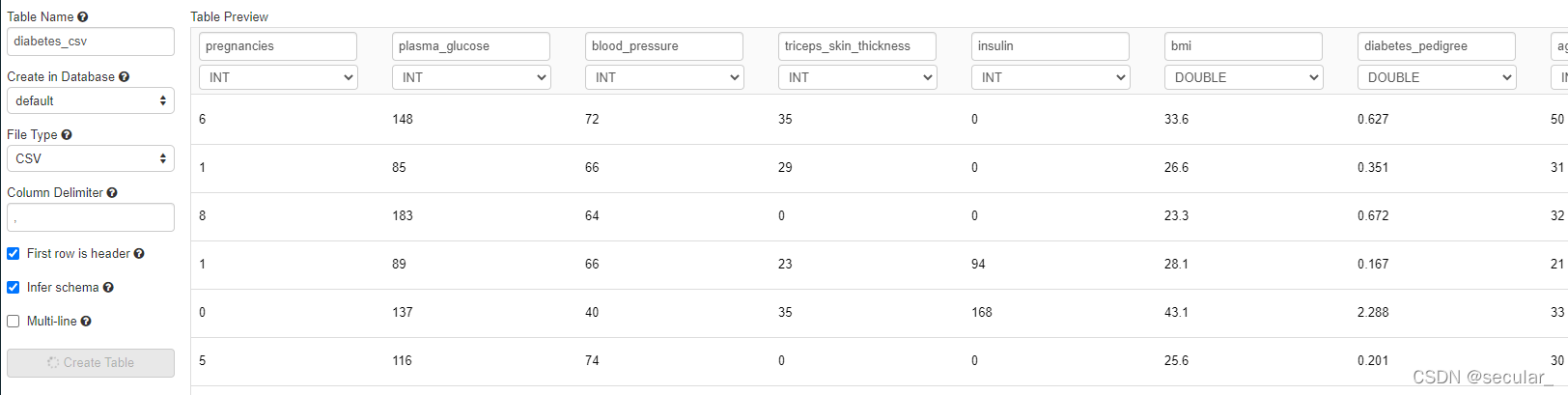
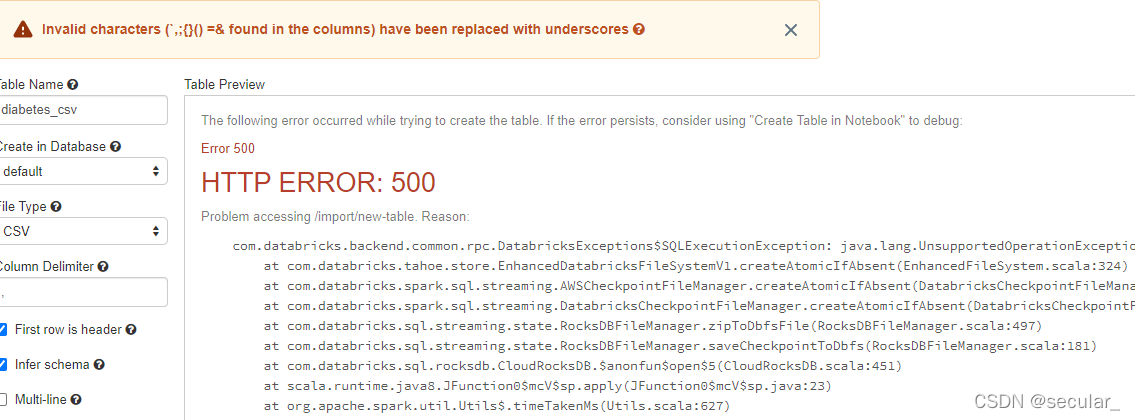
有可能会报错,但无所谓。回到data找到这个表就行 [报错是因为在无法在当前的系统上查看该表,但是表已经在databricks里了,通过ls可以看到]
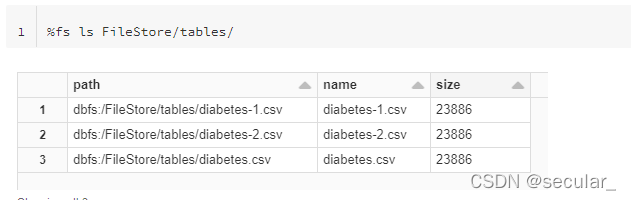
每次通过这种方式上传的table都会在FileStore/tables/里面

















 1346
1346

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









