



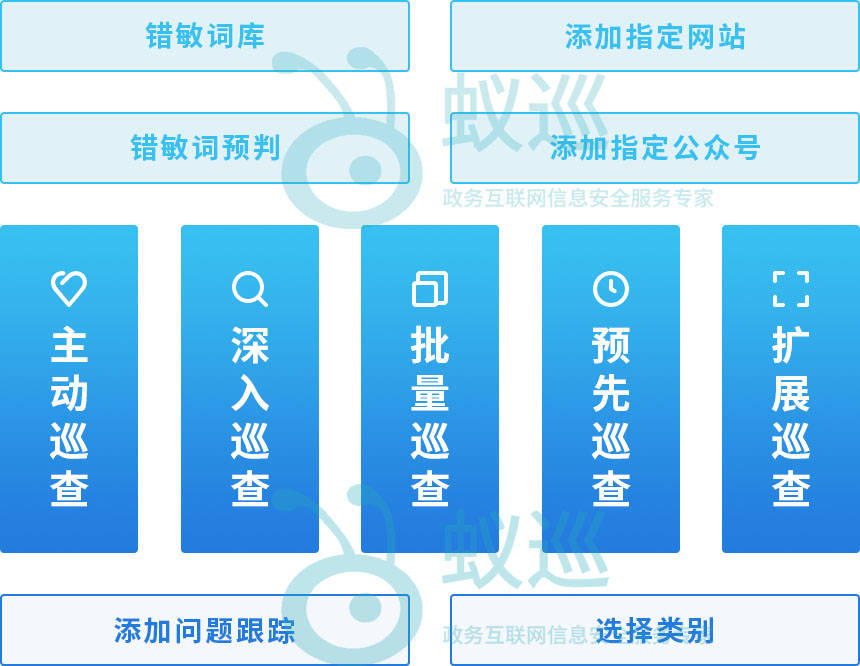
检测和过滤网站及新媒体内容中的“限制词”(包括违禁词、敏感词、广告极限词等),通常采用“词库匹配 + 语义分析 + 流程控制”相结合的技术手段。具体的实施方案主要分为以下三个层面:

限制词检测与过滤的核心方法
1. 建立精准且动态的“核心词库”
这是检测的基础。词库不能一成不变,必须分类管理并实时更新。
- 基础匹配: 包含政治敏感词、涉黄涉暴词、违禁品词汇。
- 法律合规: 包含《新广告法》禁止的极限词(如“第一”、“顶级”)、《数据安全法》相关的隐私信息格式。
- 行业特征: 根据所属行业添加特定的违规词(如医疗行业的虚假承诺词)。
2. 发布前置过滤(API 接口集成)
- 原理: 将检测引擎的 API 接口集成到网站的内容管理系统(CMS)、新媒体编辑工具或评论发布框中。
- 流程: 当编辑人员点击“保存”或“发布”时,系统后台自动将文本发送至检测接口。
- 动作:
- 高危词: 直接拦截,禁止发布。
- 疑似词: 弹出提示,标红高亮,要求人工修改或复核。
3. 发布后全站巡检(爬虫扫描)
- 原理: 针对历史存量数据,或为了防止前置过滤被绕过,利用网络爬虫技术对网站全站页面、新媒体历史文章进行周期性抓取。
- 动作: 将抓取的内容与词库比对,生成“违规内容清单”,定位到具体的 URL 和段落,供运维人员进行清理或下架。
4. 智能语义分析(AI 辅助)
- 解决痛点: 简单的关键词匹配容易被“谐音”、“拆字”、“拼音”或“变体”绕过。
- 技术应用: 利用 NLP(自然语言处理)技术,识别变体词、隐晦表达以及图片中的文字(OCR 技术),提高过滤的精准度,减少漏判。


















 774
774

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









