





今天的大型语言模型(LLMs)在许多用例中都取得了前所未有的成果。然而,由于基础模型的通用性,应用程序开发者通常需要定制和调整这些模型,以便专门针对其用例开展工作。
完全微调需要大量数据和计算基础设施,从而更新模型权重。此方法需要在GPU显存上托管和运行模型的多个实例,以便在单个设备上提供多个用例。
示例用例包括多语言翻译助手,用户需要同时获得多种语言的结果。这可能会给设备上的 AI 带来挑战,因为内存限制。
在设备显存上同时托管多个LLM几乎是不可能的,尤其是在考虑运行合适的延迟和吞吐量要求以与用户进行交互时另一方面,用户通常在任何给定时间运行多个应用和任务,在应用之间共享系统资源。
低秩适配(LoRA)等高效的参数微调技术可帮助开发者将自定义适配器连接到单个 LLM,以服务于多个用例。这需要尽可能减少额外的内存,同时仍可提供特定于任务的 AI 功能。该技术使开发者能够轻松扩展可在设备上服务的用例和应用程序的数量。
NVIDIA RTX AI 工具包的一部分 NVIDIA TensorRT-LLM 现已提供 Multi-LoRA 支持。这项新功能使 NVIDIA RTX AI PC 和工作站能够在推理期间处理各种用例。
LoRA 简介
LoRA 是一种热门的参数高效微调技术,可以调节少量参数。其他参数称为 LoRA 适配器,表示网络密集层中变化的低秩分解。
只有这些低级别的附加适配器是自定义的,而在此过程中,模型的剩余参数会被冻结。经过训练后,这些适配器将在推理期间通过合并到基础模型进行部署,从而在推理延迟和吞吐量方面尽可能减少,甚至不增加任何开销。
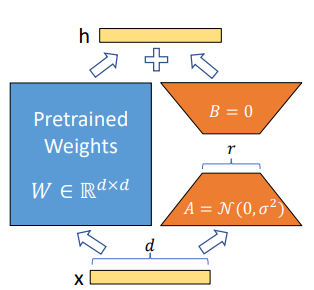
图 1. A 和 B 中的参数表示可训练的参数,以展示 LoRA 技术(来源:LoRA:大型语言模型的低阶适应)
图 1 展示了有关 LoRA 技术的更多详细信息。
- 在自定义期间,预训练模型的权重 (W) 将被冻结。
- 我们不会更新 W,而是注入两个较小的可训练矩阵(A 和 B)来学习特定于任务的信息。矩阵乘法 B*A 会形成一个与 W 具有相同维度的矩阵,因此可以将其添加到 W (= W + BA) 中。
A 和 B 矩阵的秩是 8、16 等较小的值。此秩 (r) 参数可在训练时自定义。更大的秩值使模型能够捕获与下游任务相关的更多细微差别,通过更新模型中的所有参数来接近完
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









