







 本文讨论了Linux内核如何使用数据类型以确保跨架构的兼容性。重点介绍了标准C类型、指定大小的数据项、接口特定类型以及其他移植性问题,如时间间隔、页大小、字节顺序、数据对齐和指针与错误值。内核通过自定义类型和特定接口隐藏架构差异,同时强调了在处理时间间隔、页大小和字节顺序时的注意事项。
本文讨论了Linux内核如何使用数据类型以确保跨架构的兼容性。重点介绍了标准C类型、指定大小的数据项、接口特定类型以及其他移植性问题,如时间间隔、页大小、字节顺序、数据对齐和指针与错误值。内核通过自定义类型和特定接口隐藏架构差异,同时强调了在处理时间间隔、页大小和字节顺序时的注意事项。
为什么要单独讲kernel的数据结构?
kernel是一个支持很多平台很多架构的OS,不同的架构上,很多的数据结构都是不同的,如何保证kernel能兼容多个架构,这就得益于kernel良好的数据结构设计。
kernel中各种各样的数据结构,主要三类:
1, int等标准的C类型
2, 表明大小或者长度的类型,如u32等
3, kernel自己的结构体,如pid_t等
后面会讲应该如何使用这样的数据结构。
11.1. Use of Standard C Types
尽管developer可以尽情使用像int,long这类标准的数据类型,但是要注意类型冲突或者潜在的bug。这类数据类型,在不同的架构上占用的memory是不一样的:
arch Size: char short int long ptr long-long u8 u16 u32 u64
i386 1 2 4 4 4 8 1 2 4 8
alpha 1 2 4 8 8 8 1 2 4 8
armv4l 1 2 4 4 4 8 1 2 4 8
ia64 1 2 4 8 8 8 1 2 4 8
m68k 1 2 4 4 4 8 1 2 4 8
mips 1 2 4 4 4 8 1 2 4 8
ppc 1 2 4 4 4 8 1 2 4 8
sparc 1 2 4 4 4 8 1 2 4 8
sparc64 1 2 4 4 4 8 1 2 4 8
x86_64 1 2 4 8 8 8 1 2 4 8
可以看出long类型和指针占用的内存是一样大的,所以在kernel中大量使用unsigned long来表示地址。之所以不直接使用指针,是为了防止随意通过指针访问memory,因为kernel推荐使用各种各样的interface来访问。
11.2. Assigning an Explicit Size to Data Items
有些场景下,需要明确指定变量的size,比如:
#include <asm/types.h>
u8; /* unsigned byte (8 bits) */
u16; /* unsigned word (16 bits) */
u32; /* unsigned 32-bit value */
u64; /* unsigned 64-bit value */
如果user space需要使用这样的类型,需要使用带两个下划线的版本,如__u8,__u32等。
11.3. Interface-Specific Types
有些接口返回的数据类型,不是标准的C数据类型,而是kernel通过typedef自己定义的数据结构,比如进程ID pid_t。使用这种自定义的类型,好处在于可以隐藏架构不同导致的数据差异,对driver developer而言,无论什么架构,使用的数据类型都是pid_t,kernel则隐藏了每个架构的实现。
然而后面kernel的code使用interface specific 数据类型的越来越少了,许多code直接使用相应的数据类型,而不是类似于pid_t的数据类型。因为这种数据类型有其弊端,比如size_t可能对应unsigned int,或者unsigned long,那么你打印的时候按照什么数据类型打印。通常情况下,把它按照最大的数据类型转换,再打印就可以,比如size_t转换为unsigned long来打印。
11.4. Other Portability Issues
code中可能存在一些预定义的常量,导致存在某些移植性的问题,比如一些预定义的宏。
11.4.1. Time Intervals
计算时间间隔,不要假设当前的HZ是1000,就用1000直接计算,而应该使用HZ来计算。比如要计算0.5s,应该是HZ/2,而不是直接使用jiffies 500.
11.4.2. Page Size
虽然x86或者其他的架构上PAGE_SIZE是4KB,但是不能直接使用4KB,而应该使用PAGE_SIZE和PAGE_SHIFT。这里有一个例子,如果你需要分16KB的memory,如何分配呢?
#include <asm/page.h>
int order = get_order(16*1024);
buf = get_free_pages(GFP_KERNEL, order);
应该使用get_order来计算order,再使用order调用get_free_pages来分page。
11.4.3. Byte Order
不同架构上可能使用不同的字节序,但是device driver在实现时,尽量不对字节序做任何假设,也不应该依赖于字节序。但是在某些特定的情况下,可能需要依赖于字节序。
在需要依赖于字节序的地方,可以通过宏来check:__BIG_ENDIAN和__LITTLE_ENDIAN。但是如果这样的宏太多,会比较麻烦,所以kernel提供了这样的函数直接来实现:
u32 cpu_to_le32 (u32);
u32 le32_to_cpu (u32);
使用上面的两个宏,会把数据转换为小尾端的u32出来,无论你是大尾端还是小尾端。
11.4.4. Data Alignment
为了提高performance,编译器可能会对数据结构进行padding,而不同的架构上,可能对其的结构并不一样。为了减少这种问题,driver可以自己对数据结构进行padding。比如kernel的一个例子:
struct {
u16 id;
u64 lun;
u16 reserved1;
u32 reserved2;
} _ _attribute_ _ ((packed)) scsi;
11.4.5. Pointers and Error Values
很多interface如果fail了,会直接返回NULL;但是有时候caller需要直到发生了哪种错误,这就需要interface返回一些error code,而不是NULL,caller通过一些方法检查这些error code,就能知道发生了什么事。
//返回error ptr (通过error生成)
void *ERR_PTR(long error);
//判断是否返回了error ptr
long IS_ERR(const void *ptr);
//如果需要从error ptr解析error code
long PTR_ERR(const void *ptr);
11.5. Linked Lists
kernel实现了一套自己的双向链表,通过这个双向链表可以让device driver很方便的实现自己的双向链表结构,在使用的时候,如果需要互斥的访问链表资源,那driver就得自己做保护。
#include <linux/list.h>
struct list_head {
struct list_head *next, *prev;
};
struct todo_struct {
struct list_head list;
int priority; /* driver specific */
/* ... add other driver-specific fields */
};
需要使用双向链表的数据结构来说,只需要把struct list_head包含进自己的数据结构即可。
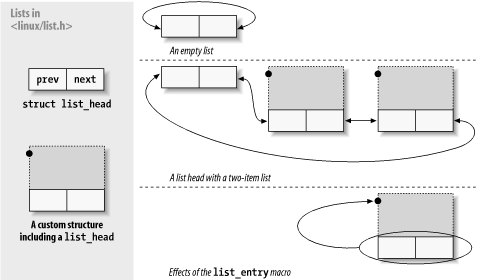
上图就是双向链表的组织形式。使用之前要初始化:
//运行时初始化
struct list_head todo_list;
INIT_LIST_HEAD(&todo_list);
//编译时初始化
LIST_HEAD(todo_list);
//把new添加到head后面,head不一定是链表头,可以是链表中的任何节点
list_add(struct list_head *new, struct list_head *head);
//把new添加到head前面,也就是链表的尾巴。相当于把双向链表作为FIFO使用
list_add_tail(struct list_head *new, struct list_head *head);
//将entry从双向链表中删除,如果还会放入别的list,就使用list_del_init。
list_del(struct list_head *entry);
list_del_init(struct list_head *entry);
//把entry从当前链表移动到head链表头部,如果放入尾部,用list_move_tail。
list_move(struct list_head *entry, struct list_head *head);
list_move_tail(struct list_head *entry, struct list_head *head);
//判断链表是否为空
list_empty(struct list_head *head);
//把list这个链表,插入到head后面
list_splice(struct list_head *list, struct list_head *head);
//通过ptr获取包含struct list_head的大的数据结构地址
list_entry(struct list_head *ptr, type_of_struct, field_name);
//sample code:
struct todo_struct *todo_ptr =
list_entry(listptr, struct todo_struct, list);
通常需要loop这个双向链表,kernel已经提供了函数,这里有个例子:
void todo_add_entry(struct todo_struct *new)
{
struct list_head *ptr;
struct todo_struct *entry;
list_for_each(ptr, &todo_list) {
entry = list_entry(ptr, struct todo_struct, list);
if (entry->priority < new->priority) {
list_add_tail(&new->list, ptr);
return;
}
}
list_add_tail(&new->list, &todo_struct)
}
除了list_for_each,kernel还提供了别的loop用的函数:
//普通的loop,需要注意loop的过程中对链表的修改
list_for_each(struct list_head *cursor, struct list_head *list)
//逆向loop
list_for_each_prev(struct list_head *cursor, struct list_head *list)
//如果loop的过程中,需要从链表中删除node,就使用这个函数
list_for_each_safe(struct list_head *cursor, struct list_head *next, struct list_head *list)
//获取大结构体的指针
list_for_each_entry(type *cursor, struct list_head *list, member)
list_for_each_entry_safe(type *cursor, type *next, struct list_head *list, member)

















 723
723

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









