









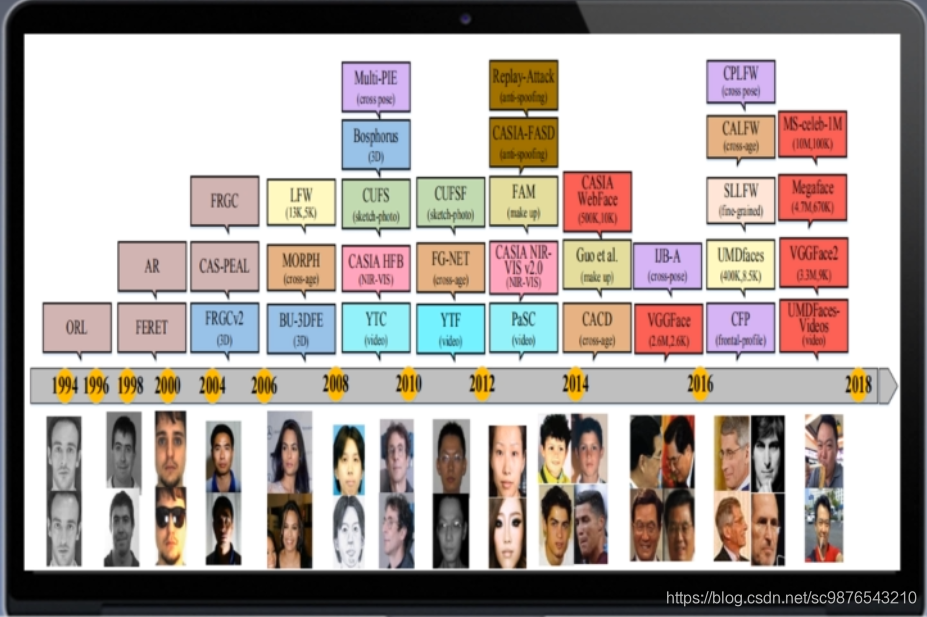
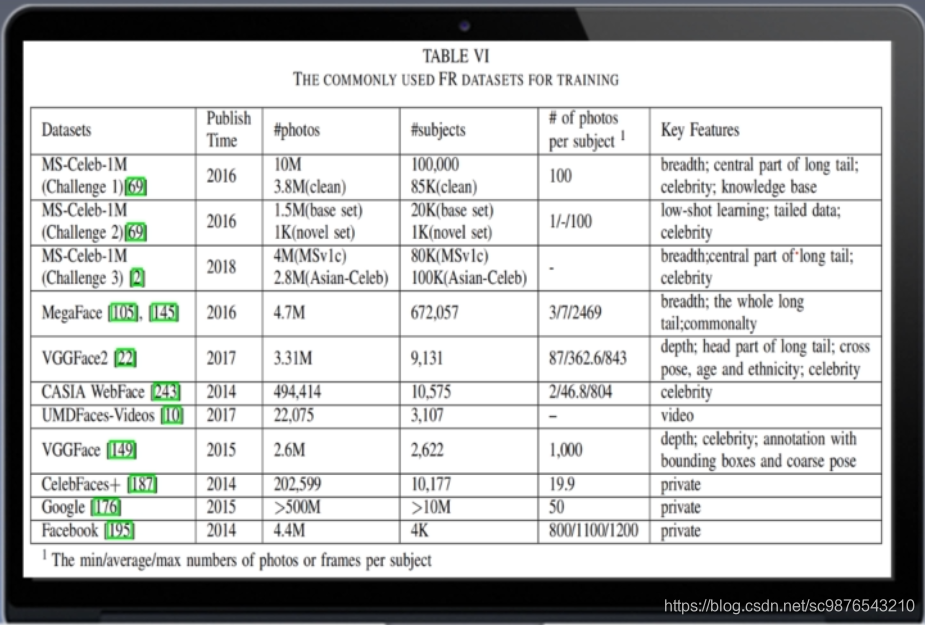
一:人脸识别常用数据集及其发展
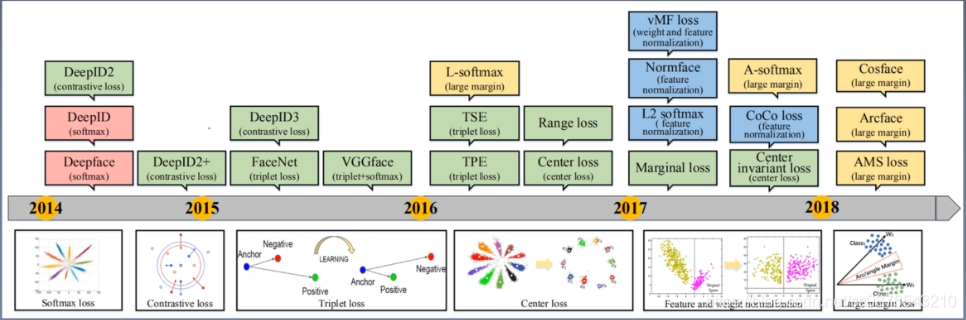
一:人脸识别常用方法
1、主流路线
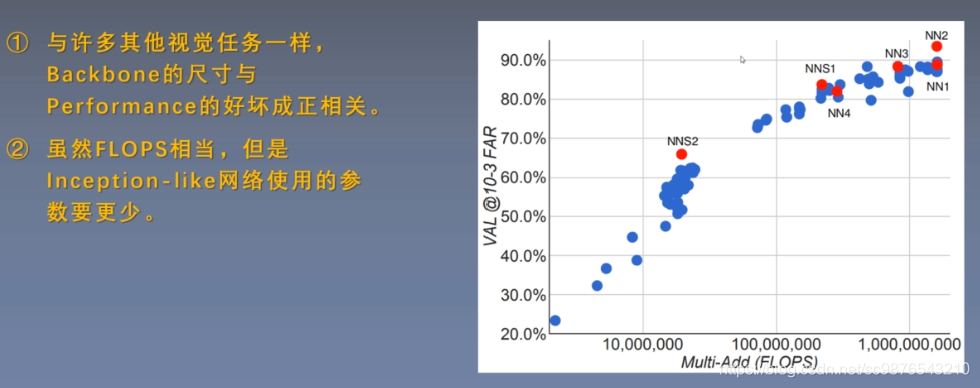
1:比较的方法(相同离得近,不同离得远)
2:朴素的分类网络(逐渐发展为改变softmax)


2、Triplet loss的缺点

三:Facenet
1、什么是Facenet
谷歌人脸识别算法,发表于 CVPR 2015,利用人脸在不同角度等姿态的照片下有高内聚性,不同人脸 有低耦合性,提出使用 cnn + triplet mining 方法,在LFW数据集上准确度达到 99.63%。
通过 CNN 将人脸映射到欧式空间的特征向量上,实质上:不同图片人脸特征的距离较大;通过相同个体的人脸的距离,总是小于不同个体的人脸这一先验知识训练网络。
测试时只需要计算人脸特征EMBEDDING,然后计算距离使用阈值即可判定两张人脸照片是否属于相同的个体。

2、主干网络介绍
facenet的主干网络起到提取特征的作用,原版的facenet以Inception-ResNetV1为主干特征提取网络。
本文一共提供了两个网络作为主干特征提取网络,分别是mobilenetv1和Inception-ResNetV1(当时更为先进的网络还没有出来),二者都起到特征提取的作用,为了方便理解,本博文中会使用mobilenetv1作为主干特征提取网络。
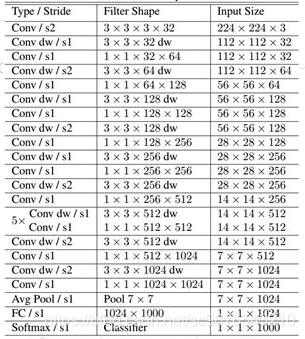
MobilenetV1模型是Google针对手机等嵌入式设备提出的一种轻量级的深层神经网络,其使用的核心思想便是depthwise separable convolution(深度可分离卷积块),其结构如下所示。
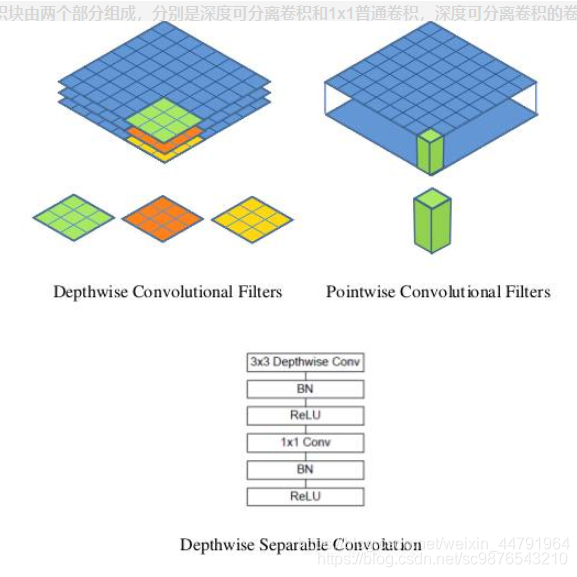
深度可分离卷积块由两个部分组成,分别是深度可分离卷积和1x1普通卷积,深度可分离卷积的卷积核大小一般是3x3的,我们可以把它当作是特征提取,1x1的普通卷积可以完成通道数的调整。
MobileNet的结构如下,其中Conv dw就是分层卷积,在其之后都会接一个1x1的卷积进行通道处理。
3、构建分类器(用于辅助Triplet Loss的收敛)
仅仅只是用Triplet Loss会使得整个网络难以收敛,本文结合Cross-Entropy Loss和Triplet Loss作为总体loss。
Triplet Loss用于进行不同人的人脸特征向量欧几里得距离的扩张,同一个人的不同状态的人脸特征向量欧几里得距离的缩小。
Cross-Entropy Loss用于人脸分类,具体作用是辅助Triplet Loss收敛。
想要利用Cross-Entropy Loss进行训练需要构建分类器,因此我们在原网络的最后增加一个全连接层用于分类。
在进行网络的训练的时候,可使用分类器辅助训练,在预测的时候,分类器是不需要的,其结构如下。
class Facenet(nn.Module):
def __init__(self, backbone="mobilenet", dropout_keep_prob=0.5, embedding_size=128, num_classes=None, mode="train"):
super(Facenet, self).__init__()
if backbone == "mobilenet":
self.backbone = mobilenet()
flat_shape = 1024
elif backbone == "inception_resnetv1":
self.backbone = inception_resnet()
flat_shape = 1792
else:
raise ValueError('Unsupported backbone - `{}`, Use mobilenet, inception_resnetv1.'.format(backbone))
self.avg = nn.AdaptiveAvgPool2d((1,1))
self.Dropout = nn.Dropout(1 - dropout_keep_prob)
self.Bottleneck = nn.Linear(flat_shape, embedding_size,bias=False)
self.last_bn = nn.BatchNorm1d(embedding_size, eps=0.001, momentum=0.1, affine=True)
if mode == "train":
self.classifier = nn.Linear(embedding_size, num_classes)
def forward(self, x):
x = self.backbone(x)
x = self.avg(x)
x = x.view(x.size(0), -1)
x = self.Dropout(x)
x = self.Bottleneck(x)
x = self.last_bn(x)
x = F.normalize(x, p=2, dim=1)
return x
def forward_feature(self, x):
x = self.backbone(x)
x = self.avg(x)
x = x.view(x.size(0), -1)
x = self.Dropout(x)
x = self.Bottleneck(x)
before_normalize = self.last_bn(x)
x = F.normalize(before_normalize, p=2, dim=1)
return before_normalize, x
def forward_classifier(self, x):
x = self.classifier(x)
return x
3、Triplet Loss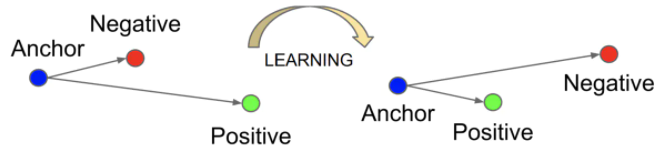
Triplet Loss的输入是一个三元组
a:anchor,基准图片获得的128维人脸特征向量
p:positive,与基准图片属于同一张人脸的图片获得的128维人脸特征向量
n:negative,与基准图片不属于同一张人脸的图片获得的128维人脸特征向量
我们可以将anchor和positive求欧几里得距离,并使其尽量小。
我们可以将negative和positive求欧几里得距离,并使其尽量大。
我们所使用的公式为。
Loss=max(d(a,p)−d(a,n)+margin,0)
d(a,p)就是anchor和positive的欧几里得距离。我们希望,同一个人的不同状态的人脸特征向量欧几里得距离小。
d(a,n)就是negative和positive的欧几里得距离。我们希望不同人的人脸特征向量欧几里得距离大
margin是一个常数。
#####triplet_loss代码如下################
def triplet_loss(alpha = 0.2):
def _triplet_loss(y_pred,Batch_size):
anchor, positive, negative = y_pred[:int(Batch_size)], y_pred[int(Batch_size):int(2*Batch_size)], y_pred[int(2*Batch_size):]
pos_dist = torch.sqrt(torch.sum(torch.pow(anchor - positive,2), axis=-1))
neg_dist = torch.sqrt(torch.sum(torch.pow(anchor - negative,2), axis=-1))
#neg_dist - pos_dist < alpha,不同图片差距过大没有意义(太容易识别),故设置alpha值
keep_all = (neg_dist - pos_dist < alpha).cpu().numpy().flatten()
hard_triplets = np.where(keep_all == 1)
pos_dist = pos_dist[hard_triplets].cuda()
neg_dist = neg_dist[hard_triplets].cuda()
basic_loss = pos_dist - neg_dist + alpha
#该批次中满足neg_dist - pos_dist < alpha的平均损失
loss = torch.sum(basic_loss)/torch.max(torch.tensor(1),torch.tensor(len(hard_triplets[0])))
return loss
return _triplet_loss
本文参考:https://blog.youkuaiyun.com/weixin_44791964/article/details/108220265,在此特别感谢该博主的无私贡献

















 561
561

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









