



随着数据的不断写入,MemStore中存储的数据会越来越多,系统为了将使用的内存保持在一个合理的水平,会将MemStore中的数据写入文件形成HFile。flush阶段是Hbase的非常核心阶段,需要重点关注几个问题:
- MemStore Flush的触发时机。即在哪些情况下Hbase会触发flush操作
- MemStore Flush的整体流程。
- HFile的构建流程。HFile构建是MemStore Flush整体流程中最重要的一部分,这部分会涉及HFile文件格式的构建、布隆过滤器的构建、HFile索引的构建等
- Flush HFile文件过多之后影响读延时的解决方法。
MemStore Flush
触发时机
HBase会在以下几种情况下触发flush操作:
- MemStore级别限制:当Region中任意一个MemStore的大小到达了上限(hbase.hregion.memstore.flush.size,默认为128M),会触发MemStore刷新。
- Region级别限制:当Region中所有MemStore的大小总和达到了上限(hbase.hregion.memstore.block.multiplier * hbase.hregion.memstore.flush.size),会触发MemStore刷新。
- RegionServer级别限制:当RegionServer中MemStore的大小总和超过低水平阀值hbase.regionserver.global.memstore.sze.lower.limit*hbase.regionserver.global.memstore.size,RegionServer开始强制执行flush,先flush MemStore最大的Region,再flush次大的,依次执行。如果此时写入吞吐量依然很高,导致总MemStore大小超过高水位阀值hbase.regionserver.global.memstore.size,RegionServer会阻塞更新并强制执行flush,直到总MemStore大小下降到低水平阀值。
- 当一个RegionServer中HLog数量达到上限时,系统会选择最早的HLog对应的一个或者多个Region进行Flush。
- Hbase定期刷新MemStore:默认周期是1个小时,确保MemStore不会长时间没有持久化。为避免所有MemStore在同一时间都进行flush而导致的问题,定期的flush操作有一定时间的随机延时。
- 手动执行flush:用户可以通过shell命令flush 'tablebname' 或者flush 'regionname'分别对一个表活着一个Region进行flush。
当满足以上触发条件时,HRegion会调用requestFlush()触发flush行为,flush发生在每一处Region可能发生变化的地方,包括Region有新数据写入,客户端调用put/batchMutate等接口。触发入口的核心代码在如下HRegion#batchMutate中:
kotlin
代码解读
复制代码
/** * Perform a batch of mutations. * <p/> * Operations in a batch are stored with highest durability specified of for all operations in a * batch, except for {@link Durability#SKIP_WAL}. * <p/> * This function is called from {@link #batchReplay(WALSplitUtil.MutationReplay[], long)} with * {@link ReplayBatchOperation} instance and {@link #batchMutate(Mutation[])} with * {@link MutationBatchOperation} instance as an argument. As the processing of replay batch and * mutation batch is very similar, lot of code is shared by providing generic methods in base * class {@link BatchOperation}. The logic for this method and * {@link #doMiniBatchMutate(BatchOperation)} is implemented using methods in base class which are * overridden by derived classes to implement special behavior. * @param batchOp contains the list of mutations * @return an array of OperationStatus which internally contains the OperationStatusCode and the * exceptionMessage if any. * @throws IOException if an IO problem is encountered */ private OperationStatus[] batchMutate(BatchOperation<?> batchOp) throws IOException { boolean initialized = false; batchOp.startRegionOperation(); try { while (!batchOp.isDone()) { if (!batchOp.isInReplay()) { checkReadOnly(); } // check 资源 checkResources(); if (!initialized) { this.writeRequestsCount.add(batchOp.size()); // validate and prepare batch for write, for MutationBatchOperation it also calls CP // prePut()/preDelete()/preIncrement()/preAppend() hooks batchOp.checkAndPrepare(); initialized = true; } // 写入数据 doMiniBatchMutate(batchOp); // 写完之后再判断是否满足触发条件,如果满足则往阻塞队列塞一个Flush请求 requestFlushIfNeeded(); } } finally { if (rsServices != null && rsServices.getMetrics() != null) { rsServices.getMetrics().updateWriteQueryMeter(this.htableDescriptor.getTableName(), batchOp.size()); } batchOp.closeRegionOperation(); } return batchOp.retCodeDetails; }
处理流程
为了减少flush过程对读写的影响,HBase采用了类似两阶段提交的方式,将整个flush过程分为三个阶段:
- prepare阶段:遍历当前Region中的所有MemStore,将MemStore中当前数据集CellSkipListSet(内部采用ConcurrentSkipListMap)做一个快照snapshot,然后再新建一个CellSkipListSet接收新的数据写入。prepare阶段需要添加updateLock对写请求阻塞,结束之后会释放该锁。因为此阶段没有任何费时操作,因此持锁时间很短。
- flush阶段:遍历所有MemStore,将prepare阶段生成的snapshot持久化为临时文件,临时文件会统一放到目录.tmp下。这个过程因为涉及磁盘IO操作,因此相对比较耗时。
- commit阶段:遍历所有的MemStore,将flush阶段生成的临时文件移到指定的ColumnFamily目录下,针对HFile生成对应的Storefile和Reader,把storefile添加到Store的storefile列表中,最后再清空prepare阶段生成的snapshot。
HBase中flush请求的处理流程简化如下图中所示:
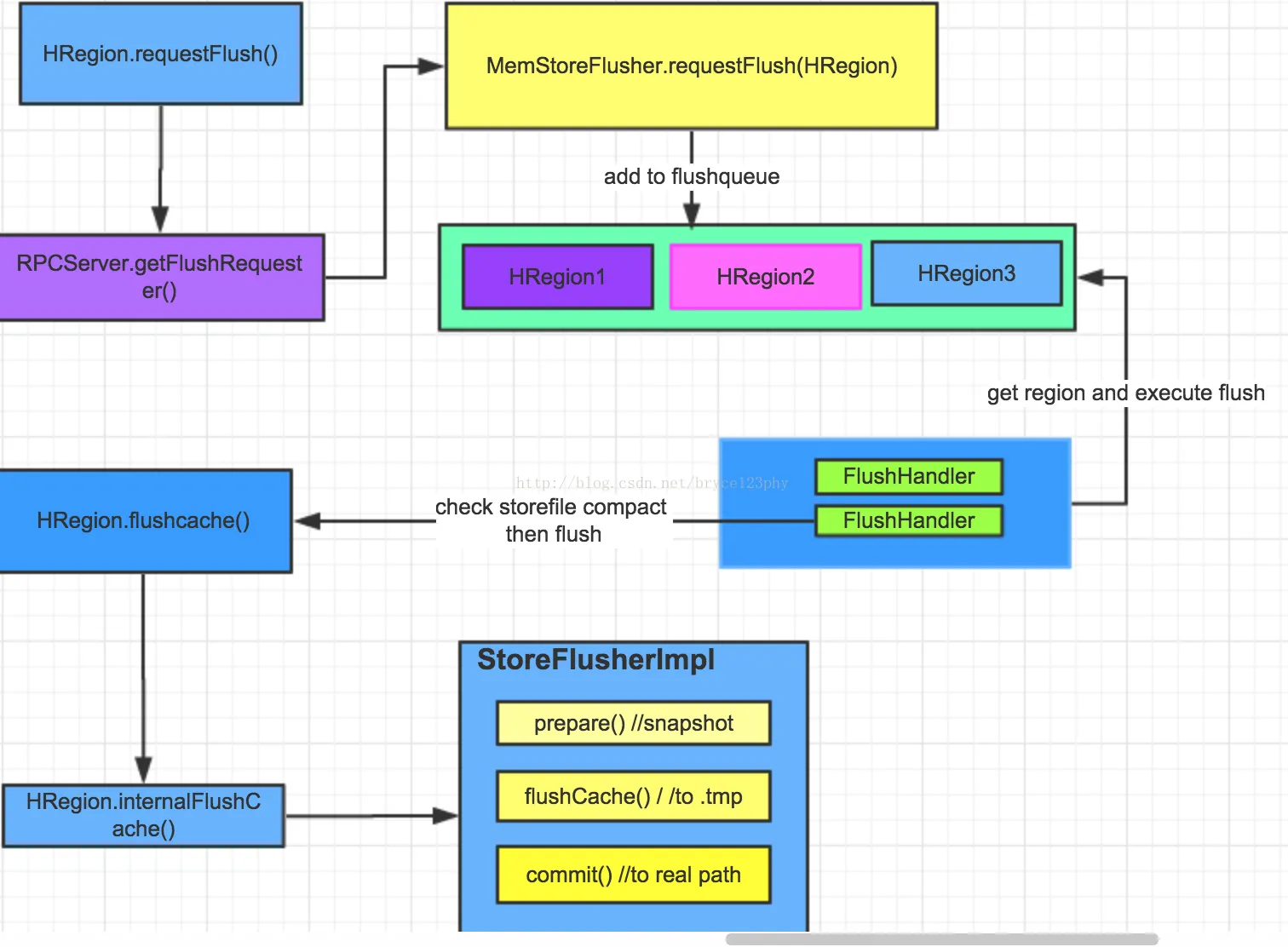
HRegion中requestFlush()的源码如下所示:
kotlin
代码解读
复制代码
private void requestFlush0(FlushLifeCycleTracker tracker) { boolean shouldFlush = false; // 检查下状态,避免重复请求 synchronized (writestate) { if (!this.writestate.isFlushRequested()) { shouldFlush = true; writestate.flushRequested = true; } } if (shouldFlush) { // Make request outside of synchronize block; HBASE-818. this.rsServices.getFlushRequester().requestFlush(this, tracker); if (LOG.isDebugEnabled()) { LOG.debug("Flush requested on " + this.getRegionInfo().getEncodedName()); } } else { tracker.notExecuted("Flush already requested on " + this); } }
主要是这句代码:
kotlin
代码解读
复制代码
this.rsServices.getFlushRequester().requestFlush(this, tracker);
其中rsServices向RegionServer发起一个RPC请求,getFlushRequest()是RegionServer中的成员变量coreFusher定义的方法,该变量是MemStoreFlusher类型,用于管理该RegionServer上的各种flush请求,它里面定义的几个关键变量如下:
java
代码解读
复制代码
// These two data members go together. Any entry in the one must have // a corresponding entry in the other. private final BlockingQueue<FlushQueueEntry> flushQueue = new DelayQueue<>(); protected final Map<Region, FlushRegionEntry> regionsInQueue = new HashMap<>(); // 原子bool private AtomicBoolean wakeupPending = new AtomicBoolean(); private final long threadWakeFrequency; // HRegionServer实例 private final HRegionServer server; private final ReentrantReadWriteLock lock = new ReentrantReadWriteLock(); private final Object blockSignal = new Object(); // HRegion 一个阻塞更新的等待时间 private long blockingWaitTime; private final LongAdder updatesBlockedMsHighWater = new LongAdder(); private final FlushHandler[] flushHandlers; private List<FlushRequestListener> flushRequestListeners = new ArrayList<>(1);
下面随着讲解HBase的flush流程来讲解上述几个变量的作用,我们先看下requestFlush(),它将待flush的region放入待处理队列,这里包含了两个队列,flushQueue是一个无界阻塞队列,属于flush的工作队列,而regionsInQueue则用于保存位于flush队列的region的信息。
java
代码解读
复制代码
@Override public boolean requestFlush(HRegion r, List<byte[]> families, FlushLifeCycleTracker tracker) { synchronized (regionsInQueue) { FlushRegionEntry existFqe = regionsInQueue.get(r); if (existFqe != null) { // if a delayed one exists and not reach the time to execute, just remove it if (existFqe.isDelay() && existFqe.whenToExpire > EnvironmentEdgeManager.currentTime()) { LOG.info("Remove the existing delayed flush entry for {}, " + "because we need to flush it immediately", r); this.regionsInQueue.remove(r); this.flushQueue.remove(existFqe); r.decrementFlushesQueuedCount(); } else { tracker.notExecuted("Flush already requested on " + r); return false; } } // This entry has no delay so it will be added at the top of the flush // queue. It'll come out near immediately. FlushRegionEntry fqe = new FlushRegionEntry(r, families, tracker); this.regionsInQueue.put(r, fqe); this.flushQueue.add(fqe); r.incrementFlushesQueuedCount(); return true; } }
至此flush任务已经放入了工作队列,等到flush线程的处理。MemStoreFlusher的flush工作线程定义在了flushHander中,初始化代码如下:
kotlin
代码解读
复制代码
public MemStoreFlusher(final Configuration conf, final HRegionServer server) { super(); this.conf = conf; this.server = server; this.threadWakeFrequency = conf.getLong(HConstants.THREAD_WAKE_FREQUENCY, 10 * 1000); this.blockingWaitTime = conf.getInt("hbase.hstore.blockingWaitTime", 90000); // 用于flush的线程数 int handlerCount = conf.getInt("hbase.hstore.flusher.count", 2); if (server != null) { if (handlerCount < 1) { LOG.warn( "hbase.hstore.flusher.count was configed to {} which is less than 1, " + "corrected to 1", handlerCount); handlerCount = 1; } LOG.info("globalMemStoreLimit=" + TraditionalBinaryPrefix .long2String(this.server.getRegionServerAccounting().getGlobalMemStoreLimit(), "", 1) + ", globalMemStoreLimitLowMark=" + TraditionalBinaryPrefix.long2String( this.server.getRegionServerAccounting().getGlobalMemStoreLimitLowMark(), "", 1) + ", Offheap=" + (this.server.getRegionServerAccounting().isOffheap())); } this.flushHandlers = new FlushHandler[handlerCount]; }
后面我们看下这些flushHandlers都做了什么,看看它的run方法,里面的主要逻辑都写在下面:
scss
代码解读
复制代码
@Override public void run() { while (!server.isStopped()) { FlushQueueEntry fqe = null; try { wakeupPending.set(false); // 从flushQueue队列中获取一个Region fqe = flushQueue.poll(threadWakeFrequency, TimeUnit.MILLISECONDS); if (fqe == null || fqe == WAKEUPFLUSH_INSTANCE) { FlushType type = isAboveLowWaterMark(); if (type != FlushType.NORMAL) { LOG.debug("Flush thread woke up because memory above low water=" + TraditionalBinaryPrefix.long2String( server.getRegionServerAccounting().getGlobalMemStoreLimitLowMark(), "", 1)); // For offheap memstore, even if the lower water mark was breached due to heap // overhead // we still select the regions based on the region's memstore data size. // TODO : If we want to decide based on heap over head it can be done without tracking // it per region. if (!flushOneForGlobalPressure(type)) { // Wasn't able to flush any region, but we're above low water mark // This is unlikely to happen, but might happen when closing the // entire server - another thread is flushing regions. We'll just // sleep a little bit to avoid spinning, and then pretend that // we flushed one, so anyone blocked will check again Thread.sleep(1000); wakeUpIfBlocking(); } // Enqueue another one of these tokens so we'll wake up again wakeupFlushThread(); } continue; } FlushRegionEntry fre = (FlushRegionEntry) fqe; // 发起flush操作 if (!flushRegion(fre)) { break; } ... } }
所有检查通过后,开始真正的flush实现,一层层进入调用的方法,最终实现在下面的代码:
java
代码解读
复制代码
protected FlushResultImpl internalFlushcache(WAL wal, long myseqid, Collection<HStore> storesToFlush, MonitoredTask status, boolean writeFlushWalMarker, FlushLifeCycleTracker tracker) throws IOException { // 准备Region下所有MemStore的快照 PrepareFlushResult result = internalPrepareFlushCache(wal, myseqid, storesToFlush, status, writeFlushWalMarker, tracker); if (result.result == null) { // Flush 到临时目录且提交移动到CF目录下 return internalFlushCacheAndCommit(wal, status, result, storesToFlush); } else { return result.result; // early exit due to failure from prepare stage } }
其中
- internalPrepareFlushCache进行flush前的准备工作,包括生成一次MVCC的事务ID,准备flush时所需要的缓存和中间数据结构,以及生成当前MemStore的一个快照。
- internalFlushCacheAndCommit则执行了具体的flush行为,包括首先将数据写入临时的tmp文件,提交一次更新事务(commit),最后将文件移入HDFS中的正确目录下。
这里有几个关键点,一,该方法是被updatesLock().writeLock保护起来的,updatesLock与上文中提到的lock一样,都是ReentrantReadWriteLock,这里为啥还要加锁呢,前面讲过所加的锁是对region整体行为而言的,如split、move、merge等宏观行为,而这里的updatesLock数数据的更新请求,快照生成期间加入updatesLock是为了保证数据一致性,快照生成后立刻释放了锁,保证了用户请求与快照flush到磁盘同时进行,提高了系统并发的吞吐量。
HFile构建流程
HFile生成流程参考另一篇
HBase Compaction
但随着Flush次数的不断增多,HFile的文件数量也会不断增多,那么这样会带来什么影响呢?在HBaseCon 2013大会上,Hontonworks的名为《Compaction Improvements in Apache HBase》的主题演讲中,提到了他们测试过的随着HFile的数量的不断增多对读取时延性带来的影响:
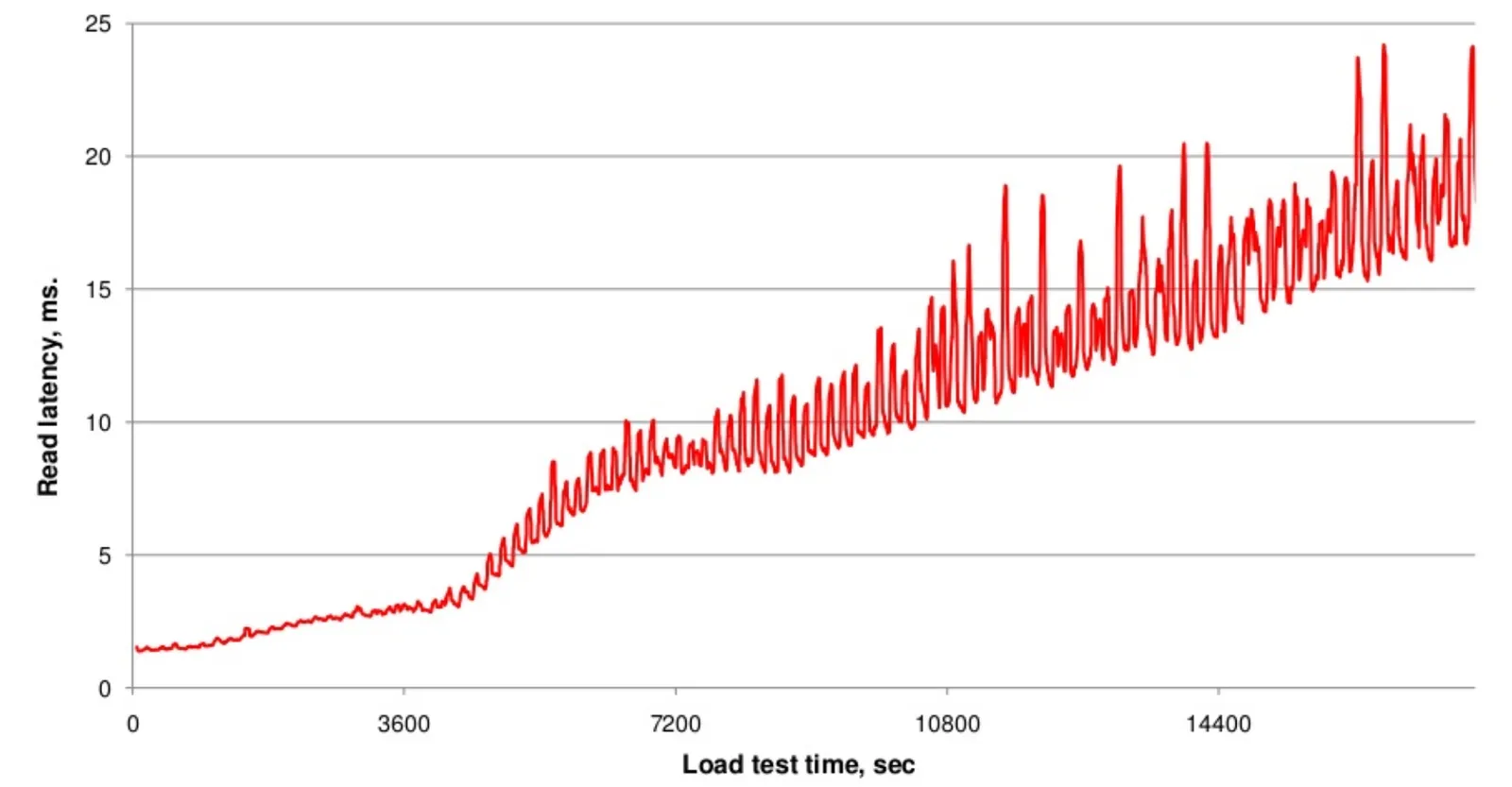
这里结合HBase的读流程如下图,可以帮助我们简单的理解这其中的原因:
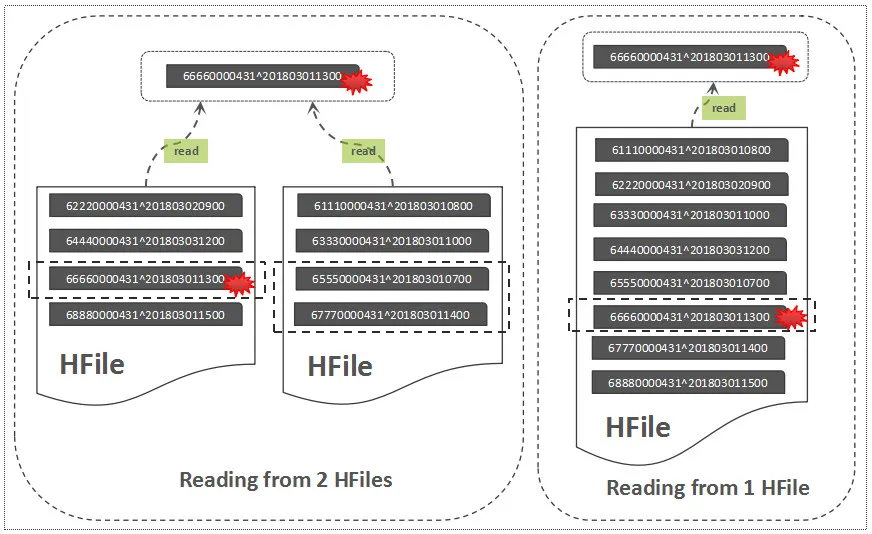
图中说明了从一个文件中指定RowKey读取记录和从两个文件中读取记录的区别,明显,从两个文件中读取,将导致更多的磁盘IO。这就是HBase执行Compaction得一个初衷,Compaction可以将一些HFile文件合并为一个较大的HFile文件,也可以把所有的HFile文件合并为一个大的HFile文件,这个过程可以理解为:将多个HFile的“交错无序态” 变成了单个HFile的"有序状态",降低读取时延性,小范围的HFile文件合并,称之为Minor Compaction,一个列簇中所有的HFile文件合并,称之为Major Compaction。除了文件合并范围的不同之处,Major Compaction 还会清理一些TTL过期/版本过旧以及被标记删除的数据。下图直观描述了Flush与Compaction流程:
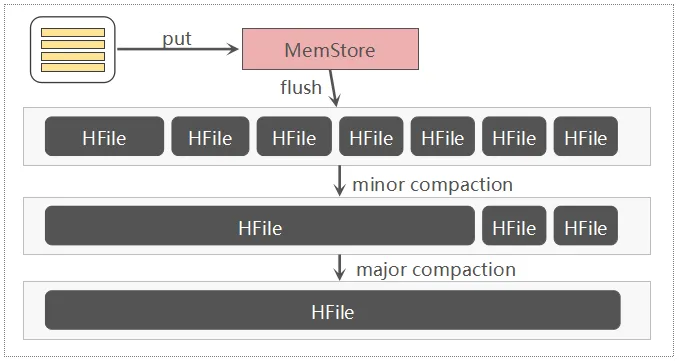
Compaction的本质
我们再想下,在集群中执行Compaction,本质是为了什么?大概的原因如下:
- 减少HFile的文件数量,减少文件句柄数量,降低读取时延
- Major Compaction 可以帮助清理集群中不再需要的数据(过期数据,被标记删除数据、版本溢出数据)
- 提高数据本地化率
很多Hbase用户在集群中关闭了自动Major Compaction,为了降低Compaction 对ID资源的抢占,但出于清理数据的需要,又不得不在一些非繁忙时段手动触发Major Compaction,这样既可以有效降低存储空间,也可以有效降低读取时效。

















 781
781

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









