



如何使用(不难 简单略过)
-
下载
python
代码解读
复制代码
pip install bandit -
开始扫描

-
等待扫描结果
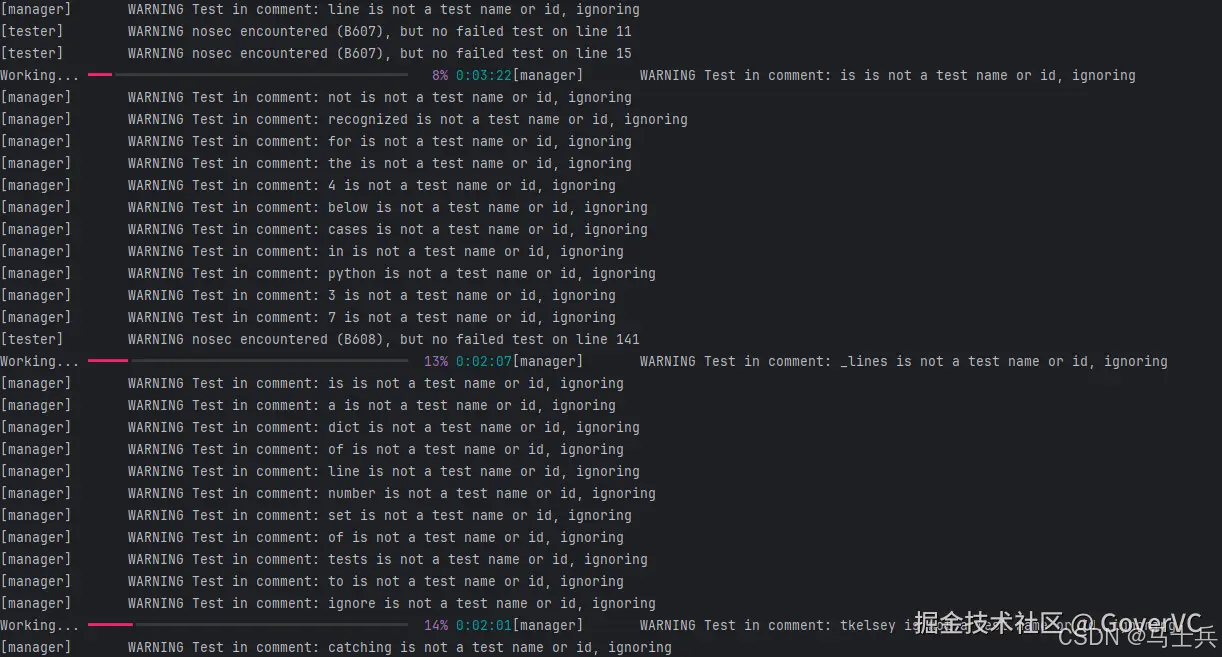
-
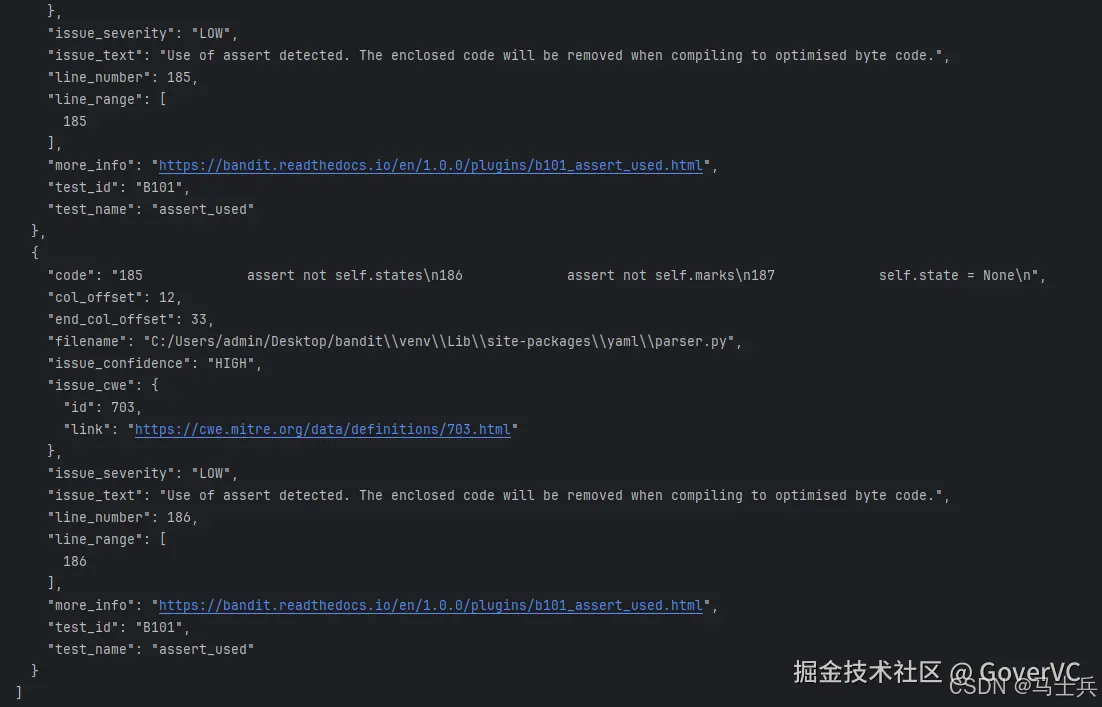
也可以导出为json文件格式,方便查看

命令行可输入参数
以下是 Bandit CLI 命令行工具的参数及其说明,格式为表格形式:
| 参数 | 作用描述 | 示例 |
|---|---|---|
-h, --help | 显示帮助信息并退出。 | bandit -h |
-r, --recursive | 递归查找并处理子目录中的文件。 | bandit -r /path/to/project |
-a {file,vuln}, --aggregate {file,vuln} | 聚合输出内容,可按漏洞类型 (vuln) 或文件名 (file) 聚合。 | bandit -r /path/to/project -a vuln |
-n CONTEXT_LINES, --number CONTEXT_LINES | 为每个问题输出的最大代码行数。 | bandit -r /path/to/project -n 5 |
-c CONFIG_FILE, --configfile CONFIG_FILE | 指定用于选择插件和覆盖默认设置的可选配置文件。 | bandit -c /path/to/config.yaml -r /path/to/project |
-p PROFILE, --profile PROFILE | 指定分析配置文件(默认为执行所有测试)。 | bandit -p profile_name -r /path/to/project |
-t TESTS, --tests TESTS | 指定要运行的测试 ID,多个 ID 用逗号分隔。 | bandit -t B101,B102 -r /path/to/project |
-s SKIPS, --skip SKIPS | 指定要跳过的测试 ID,多个 ID 用逗号分隔。 | bandit -s B104 -r /path/to/project |
-l, --level | 报告指定严重性级别或更高的所有问题:-l(低)、-ll(中)、-lll(高)。 | bandit -r /path/to/project -ll |
--severity-level {all,low,medium,high} | 报告指定的严重性级别及更高级别的问题。 | bandit -r /path/to/project --severity-level high |
-i, --confidence | 报告指定置信度级别或更高的所有问题:-i(低)、-ii(中)、-iii(高)。 | bandit -r /path/to/project -ii |
--confidence-level {all,low,medium,high} | 报告指定的置信度级别及更高级别的问题。 | bandit -r /path/to/project --confidence-level high |
-f {csv,custom,html,json,screen,txt,xml,yaml}, --format {csv,custom,html,json,screen,txt,xml,yaml} | 指定输出格式。 | bandit -r /path/to/project -f json |
--msg-template MSG_TEMPLATE | 指定输出消息模板,仅与 --format custom 配合使用。 | bandit -r /path/to/project --format custom --msg-template |
-o [OUTPUT_FILE], --output [OUTPUT_FILE] | 将报告写入文件,默认输出到控制台。 | bandit -r /path/to/project -o report.txt |
-v, --verbose | 输出额外信息,如排除的文件。 | bandit -r /path/to/project -v |
-d, --debug | 启用调试模式,显示调试信息。 | bandit -r /path/to/project -d |
-q, --quiet, --silent | 仅在发生错误时显示输出。 | bandit -r /path/to/project -q |
--ignore-nosec | 不跳过带有 # nosec 注释的行。 | bandit -r /path/to/project --ignore-nosec |
-x EXCLUDED_PATHS, --exclude EXCLUDED_PATHS | 排除特定路径,支持逗号分隔和通配符。 | bandit -r /path/to/project -x /path/to/exclude1,/path2 |
-b BASELINE, --baseline BASELINE | 指定基线报告路径(仅支持 JSON 格式文件),用于与当前扫描结果对比。 | bandit -r /path/to/project -b baseline.json |
--ini INI_PATH | 指定 .bandit 文件路径,文件中包含命令行参数。 | bandit -r /path/to/project --ini config.ini |
--exit-zero | 即使找到问题,退出码也返回 0。 | bandit -r /path/to/project --exit-zero |
--version | 显示程序的版本号并退出。 | bandit --version |
Bandit 扫描流程概述
-
main函数入口
-
bandit\bandit__main__.py
css
代码解读
复制代码
from bandit.cli import main # main方法入口 main.main() -
跳转进bandit\bandit\cli\main.py
python
代码解读
复制代码
def main(): """Bandit CLI.""" # 主函数,启动 Bandit 命令行工具 # 初始化日志设置,优先根据命令行参数确定日志级别 debug = ( logging.DEBUG # 如果传入了 -d 或 --debug,则设置为 DEBUG 级别 if "-d" in sys.argv or "--debug" in sys.argv else logging.INFO # 否则设置为 INFO 级别 ) # 剩余代码逻辑
-
-
文件发现与加载:位于bandit\bandit\cli\main.py
- Bandit 首先会使用文件发现机制来确定哪些文件需要进行扫描。通常,它会扫描指定目录下的 Python 文件(
.py)。这一步通过函数discover_files()来实现,它会递归查找符合条件的 Python 文件。
ini
代码解读
复制代码
def discover_files(self, targets, recursive=False, excluded_paths=""): # 遍历目标文件夹并找到所有 Python 文件,忽略排除的文件 - Bandit 首先会使用文件发现机制来确定哪些文件需要进行扫描。通常,它会扫描指定目录下的 Python 文件(
-
执行 Bandit 文件扫描:
-
执行bandit测试:
P:bandit\bandit\cli\main.py
bash
代码解读
复制代码
# 执行 Bandit 测试 b_mgr.run_tests()-
准备解析数据:
P:bandit\bandit\core\manager.py
ruby
代码解读
复制代码
def run_tests(self): # 代码逻辑... # 解析标准输入的数据 self._parse_file("<stdin>", fdata, new_files_list) -
-
AST 解析:
-
准备进行 AST 分析:
P:bandit\bandit\core\manager.py
ruby
代码解读
复制代码
def _parse_file(self, fname, fdata, new_files_list): # 业务逻辑... # 执行 AST 访问者,进行静态分析 score = self._execute_ast_visitor(fname, fdata, data, nosec_lines)-
处理文件数据,开始解析并执行 AST 访问,获取风险分数:
P:bandit\bandit\core\manager.py
ruby
代码解读
复制代码
def _execute_ast_visitor(self, fname, fdata, data, nosec_lines): # 业务逻辑... # 处理文件数据,开始解析并执行 AST 访问 score = res.process(data)-
Bandit 使用 Python 内置的
ast模块来解析代码文件并生成其 AST(抽象语法树) 。这一步主要在BanditNodeVisitor中完成。AST 是用于语法分析和代码遍历的核心数据结构。P:bandit\bandit\core\manager.py
ruby
代码解读
复制代码
def process(self, data): # 业务逻辑... # 将给定的代码数据解析为 AST f_ast = ast.parse(data)上面这行代码直接将读取到的 Python 源文件内容传入
ast.parse()函数,生成对应的 AST 树。 -
-
AST 遍历与插件执行:
- 生成了 AST 之后,Bandit 会遍历 AST 树,查找潜在的安全问题。这一步通过
generic_visit()和visit()方法来实现。这些方法会遍历 AST 节点,并在发现指定类型的节点时调用相应的测试函数。
scss
代码解读
复制代码
def generic_visit(self, node): for _, value in ast.iter_fields(node): if isinstance(value, ast.AST): self.visit(value) - 生成了 AST 之后,Bandit 会遍历 AST 树,查找潜在的安全问题。这一步通过
-
插件的加载和执行:
- Bandit 使用插件机制来定义具体的安全规则,这些规则通过特定的 AST 节点类型来匹配代码中的安全问题。插件的注册和执行通过装饰器
@test.checks和@test.test_id来实现。
less
代码解读
复制代码
@test.test_id("B324") @test.checks("Call") def hashlib(context): # 匹配 hashlib 模块中的弱哈希函数,如 MD5 和 SHA1当遍历到
Call类型的 AST 节点时,Bandit 会调用上面的hashlib()函数来检查是否使用了不安全的哈希函数。 - Bandit 使用插件机制来定义具体的安全规则,这些规则通过特定的 AST 节点类型来匹配代码中的安全问题。插件的注册和执行通过装饰器
-
扫描结果的生成与报告:
- 当某个测试函数检测到潜在的安全问题时,它会生成一个
Issue对象,并将其添加到结果列表中。Bandit 最终会汇总这些问题,并生成扫描报告。
- 当某个测试函数检测到潜在的安全问题时,它会生成一个
代码传入并进行匹配的细节(篇幅较长)
-
传入代码的时刻:
-
在
run_tests()方法中,Bandit 会从发现的文件列表中读取每个文件的内容,并调用_parse_file()方法对文件进行解析。在_parse_file()中,文件数据会被传递给ast.parse(),从而生成 AST。P:bandit\bandit\core\manager.py
ruby
代码解读
复制代码
def _parse_file(self, fname, fdata, new_files_list): # 读取文件内容并解析为 AST f_ast = ast.parse(data) -
-
AST 节点与插件匹配:
-
AST 树生成后,Bandit 会通过
BanditNodeVisitor遍历 AST 节点,并调用注册的插件来执行具体的安全检查。关键是generic_visit()和visit()函数,它们会根据节点类型决定调用哪个测试插件。P:bandit\bandit\core\node_visitor.py
python
代码解读
复制代码
def visit(self, node): name = node.__class__.__name__ # 获取当前 AST 节点的类型(如 "Call"、"Import" 等) method = "visit_" + name # 动态选择访问方法 ( visit_Call...位于node_visitor.py) visitor = getattr(self, method, None) # 动态获取方法, 在本类获取visit_Call,visit_Bytes等方法 if visitor is not None: if self.debug: LOG.debug("%s called (%s)", method, ast.dump(node)) visitor(node) # 调用特定的访问方法 else: # 没有特定访问方法时,直接运行测试。 self.update_scores(self.tester.run_tests(self.context, name))例如,当 AST 中有一个
Call类型的节点(表示函数调用)时,Bandit 会调用hashlib()插件,检查这个函数调用是否涉及不安全的哈希算法。 -
-
visitor 匹配逻辑(举其一
visit_Call为例):-
visit_Call方法,用于处理 AST 中的函数调用节点 (Call类型)。它提取函数的全限定名 (qualname) 和简短名称 (name),将这些信息记录在上下文中,然后执行与函数调用相关的测试,更新评分。P:bandit\bandit\core\node_visitor.py
python
代码解读
复制代码
def visit_Call(self, node): # 处理函数调用节点,并记录其上下文信息。 self.context["call"] = node qualname = b_utils.get_call_name(node, self.import_aliases) name = qualname.split(".")[-1] self.context["qualname"] = qualname self.context["name"] = name # 运行与 Call 相关的测试 self.update_scores(self.tester.run_tests(self.context, "Call")) -
-
tester.run_tests()逻辑
-
tester解释-
Bandit 中的测试单位,由
BanditNodeVisitor创建P:bandit\bandit\core\node_visitor.py
ruby
代码解读
复制代码
class BanditNodeVisitor: def __init__( self, fname, fdata, metaast, testset, debug, nosec_lines, metrics ): # 业务逻辑... # 创建 BanditTester 实例,用于执行测试 self.tester = b_tester.BanditTester( self.testset, self.debug, nosec_lines, metrics )
-
-
testset测试集(上方 self.testset, self.debug, nosec_lines, metrics 位置),由BanditTestSet进行创建P:bandit\bandit\core\test_set.py
ruby
代码解读
复制代码
class BanditTestSet: def __init__(self, config, profile=None): # 初始化 BanditTestSet 类的实例 if not profile: profile = {} # 如果未提供 profile,则初始化为空字典 extman = extension_loader.MANAGER # 获取扩展管理器 filtering = self._get_filter(config, profile) # 获取过滤后的测试 ID # 根据过滤后的测试 ID,筛选出插件 self.plugins = [ p for p in extman.plugins if p.plugin._test_id in filtering ] # 加载内置插件并添加到插件列表 self.plugins.extend(self._load_builtins(filtering, profile)) # 加载测试配置 self._load_tests(config, self.plugins)-
MANAGER(extman = extension_loader.MANAGER 位置)用于管理 Bandit 的格式化器、插件和黑名单测试。构造函数
__init__初始化时调用load_formatters、load_plugins和load_blacklists方法,读取 Bandit 目录下的相关配置文件进行加载P:bandit\bandit\core\extension_loader.py
ini
代码解读
复制代码
class Manager: # 这些是 Bandit 内置测试的 ID builtin = ["B001"] # 内置黑名单测试 def __init__( self, # formatters:存储输出格式相关文件(如json, txt...) formatters_namespace="bandit.formatters", # plugins:存储模板文件,动态分析,更为复杂的扫描,上下文扫描(如检测硬编码, 注入问题...) plugins_namespace="bandit.plugins", # blacklists:黑名单扩展,只检测是否有特殊模块,不做复杂分析,直接上报(如是否导入“pickle”, “subprocess”包...) blacklists_namespace="bandit.blacklists", ): # 加载格式化器、插件和黑名单的扩展 self.load_formatters(formatters_namespace) self.load_plugins(plugins_namespace) self.load_blacklists(blacklists_namespace) -
_load_tests(self._load_tests(config, self.plugins)位置)用于注册
tests空字典集,在tests.get(checktype)中可获取tests中对应测试方法python
代码解读
复制代码
def _load_tests(self, config, plugins): """Builds a dict mapping tests to node types.""" self.tests = {} # 初始化一个空字典,用于存储测试与节点类型的映射 for plugin in plugins: # 遍历传入的插件列表 if hasattr(plugin.plugin, "_takes_config"): # 检查插件是否有 _takes_config 属性,用于确定是否需要配置 cfg = config.get_option(plugin.plugin._takes_config) # 从配置中获取相应的配置选项 if cfg is None: # 如果配置未找到 genner = importlib.import_module(plugin.plugin.__module__) # 动态导入插件模块 cfg = genner.gen_config(plugin.plugin._takes_config) # 生成默认配置 plugin.plugin._config = cfg # 将配置赋值给插件 for check in plugin.plugin._checks: # 遍历插件的所有检查项 (_checks:"Files", "Call"...) self.tests.setdefault(check, []).append(plugin.plugin) # 将插件添加到对应的检查项列表中 LOG.debug( "added function %s (%s) targeting %s", plugin.name, plugin.plugin._test_id, check, ) # 记录调试信息,显示添加的插件信息
-
-
run_tests(self.context, "Call")主要执行分析逻辑的函数,下面只显示重要代码
python
代码解读
复制代码
def run_tests(self, raw_context, checktype): # 获取指定类型的测试 tests = self.testset.get_tests(checktype) #checktype为"Call", "Str"等,tests则为从testset中获取一系列归属checktype的测试集 for test in tests: name = test.__name__ # 获取测试的名称 # 复制原始上下文以供测试使用 temp_context = copy.copy(raw_context) # 将原文件内容temp_context转化为新的上下文对象Context,Context内部封装了许多函数(如获取函数名,获取与上下文关联的原始 AST 节点...) context = b_context.Context(temp_context) try: # 如果测试具有配置,则使用该配置进行测试 if hasattr(test, "_config"): # 将context传进每一个test中处理分析(test:hardcoded_password_string(context)......,plugins或blacklists目录下) result = test(context, test._config) else: result = test(context) # 执行测试 if result is not None: # 如果结果有效 nosec_tests_to_skip = self._get_nosecs_from_contexts( temp_context, test_result=result ) # 检查代码里是否有# nosec 注释,若有,则跳过 # 检查是否跳过测试 if nosec_tests_to_skip is not None: if not nosec_tests_to_skip: self.metrics.note_nosec() # 记录 nosec 计数 continue if result.test_id in nosec_tests_to_skip: self.metrics.note_skipped_test() # 记录跳过的测试 continue self.results.append(result) # 将结果添加到结果列表 else: # 处理没有结果的情况 nosec_tests_to_skip = self._get_nosecs_from_contexts(temp_context) if nosec_tests_to_skip and test._test_id in nosec_tests_to_skip: LOG.warning( f"nosec encountered ({test._test_id}), but no " f"failed test on line {temp_context['lineno']}" ) return scores # 返回分数
-
AST树结构
ini
代码解读
复制代码
import ast import io # 假设 'bandit' 是你的文件名 file_path = 'C:/Users/admin/Desktop/bandit/bandit/blacklists/utils.py' # 替换为实际路径 # 打开文件并读取内容 with open(file_path, "rb") as f: fdata = io.BytesIO(f.read()) # 使用 BytesIO 处理文件数据 # 读取数据并解析为 AST data = fdata.read() fdata.seek(0) # 重置文件指针 parsed_ast = ast.parse(data) # 解析 AST print(parsed_ast) # 打印 AST 的结构 print(ast.dump(parsed_ast, annotate_fields=True, include_attributes=True))
输入以上代码后,得到如下结果,可知ast树为python对象,bandit通过ast对象扫描结果来进行分析
-
parsed_ast

-
ast.dump(parsed_ast)

具体结构分析
ini
代码解读
复制代码
Module( # AST 树的根节点,表示一个 Python 模块 body=[ # 模块的主体部分,包含模块内的所有语句 Expr( # 表达式节点,表示一行独立的表达式 value=Constant( # 值节点,表示常量值 value='Utils module.', # 常量的值 lineno=5, # 该常量所在的代码行号(第5行) col_offset=0, # 该常量在行中的起始列(第0列) end_lineno=5, # 该常量结束的行号(与起始行号相同,都是第5行) end_col_offset=20), # 该常量在行中的结束列(第20列) lineno=5, # 表达式节点的行号 col_offset=0, # 表达式节点的列偏移量 end_lineno=5, # 表达式结束的行号 end_col_offset=20), # 表达式结束的列号 FunctionDef( # 函数定义节点,表示一个函数的定义 name='build_conf_dict', # 函数的名字 args=arguments( # 函数的参数列表 posonlyargs=[], # 仅限位置的参数列表(在该例中为空) args=[ # 函数的普通参数 arg( # 参数节点,表示一个参数 arg='name', # 参数名 lineno=8, # 参数定义的行号 col_offset=20, # 参数在行中的起始列 end_lineno=8, # 参数结束的行号 end_col_offset=24), # 参数结束的列号 # ................. arg( # 参数6 arg='level', # 参数名 lineno=8, # 参数定义的行号 col_offset=56, # 参数在行中的起始列 end_lineno=8, # 参数结束的行号 end_col_offset=61)], # 参数结束的列号 kwonlyargs=[], # 关键字参数列表 kw_defaults=[], # 关键字参数的默认值 defaults=[ # 参数的默认值列表 Constant( # 常量值,表示参数 'level' 的默认值 value='MEDIUM', # 常量的值 lineno=8, # 默认值的行号 col_offset=62, # 默认值在行中的起始列 end_lineno=8, # 默认值的结束行号 end_col_offset=70)]), # 默认值的结束列号 body=[ # 函数的主体部分,包含函数内部的所有语句 Expr( # 表达式节点 value=Constant( # 常量值 value='Build and return a blacklist configuration dict.', # 常量值 lineno=9, # 常量值所在行号 col_offset=4, # 常量值在行中的起始列 end_lineno=9, # 常量值的结束行号 end_col_offset=58), # 常量值的结束列号 lineno=9, # 表达式的起始行号 col_offset=4, # 表达式的起始列 end_lineno=9, # 表达式的结束行号 end_col_offset=58), # 表达式的结束列号 Expr( # 表示一个表达式语句节点 value=Call( # 表示一个函数调用节点 func=Name( # 表示函数名(这里是 'print') id='print', # 函数名是 'print' ctx=Load(), # 'Load' 表示变量在加载上下文中被使用(这里是函数调用) lineno=10, # 函数名所在的行号 col_offset=4, # 函数名的起始列号 end_lineno=10, # 函数名所在的结束行号 end_col_offset=9), # 函数名的结束列号 args=[ # 表示函数调用的参数列表 Constant( # 表示传递给函数的常量参数 value='Hello', # 该参数的值为 'Hello' lineno=10, # 参数所在的行号 col_offset=10, # 参数在行中的起始列 end_lineno=10, # 参数的结束行号 end_col_offset=15)], # 参数的结束列号 keywords=[], # 表示没有传递关键字参数 lineno=10, # 函数调用的行号 col_offset=4, # 函数调用的起始列 end_lineno=10, # 函数调用的结束行号 end_col_offset=16), # 函数调用的结束列号 lineno=10, # 表达式所在的行号 col_offset=4, # 表达式的起始列 end_lineno=10, # 表达式的结束行号 end_col_offset=16), # 表达式的结束列号 Return( # 返回值节点,表示函数的返回值 value=Dict( # 字典节点,表示返回的字典 keys=[ # 字典中的键列表 Constant( # 键值,字典中的每个键 value='name', # 键的值 lineno=11, # 键的行号 col_offset=8, # 键的起始列 end_lineno=11, # 键的结束行号 end_col_offset=14), # 键的结束列号 # .............. Constant( # 键值6 value='level', # 键的值 lineno=16, # 键的行号 col_offset=8, # 键的起始列 end_lineno=16, # 键的结束行号 end_col_offset=15)], # 键的结束列号 values=[ # 字典中的值列表 Name( # 值1,变量名 id='name', # 变量的名称 ctx=Load(), # 变量的上下文(读取) lineno=11, # 变量所在的行号 col_offset=16, # 变量的起始列 end_lineno=11, # 变量的结束行号 end_col_offset=20), # 变量的结束列号 # ............ Name( # 值6,变量名 id='level', # 变量名 ctx=Load(), # 变量上下文 lineno=16, # 变量的行号 col_offset=17, # 变量的起始列 end_lineno=16, # 变量的结束行号 end_col_offset=22)], # 变量的结束列号 lineno=10, # 返回的字典所在的行号 col_offset=11, # 字典的起始列 end_lineno=17, # 字典的结束行号 end_col_offset=5), # 字典的结束列号 lineno=10, # 返回节点的行号 col_offset=4, # 返回节点的起始列 end_lineno=17, # 返回节点的结束行号 end_col_offset=5)], # 返回节点的结束列号 decorator_list=[], # 无装饰器 lineno=8, # 函数定义的行号 col_offset=0, # 函数定义的起始列 end_lineno=17, # 函数定义的结束行号 end_col_offset=5)], # 函数定义的结束列号 type_ignores=[] # 忽略类型 )
自定义匹配模板文件
模板文件位置
Bandit自带的模板文件都在bandit\bandit\plugins目录下,里面配有各种漏洞的匹配方式(多数为污点分析)
自动扫描逻辑
- Bandit 自动扫描的核心机制依赖于
test类,该类位于bandit/bandit/core/test_properties.py文件中。通过使用装饰器(类似于面向切面编程 - AOP) - Bandit 可以将这些装饰器放置在函数上方,使函数动态识别是否需要参与安全分析。这种方式类似于注解,能够灵活标记和管理需要检测的函数或规则。
less
代码解读
复制代码
@test.checks("Str") @test.test_id("B105") def hardcoded_password_string(context): """**B105: 检测硬编码密码字符串** # 具体代码逻辑
0. @test.checks("Str")
- 作用: 该装饰器用于指定测试规则要检查的 AST 节点类型。Bandit 通过解析 Python 源代码生成 AST,
@test.checks装饰器告诉 Bandit 哪种类型的节点应该被此测试函数处理。 - 参数:
"Str"表示该测试函数专门检查Str类型的 AST 节点(即 Python 源代码中的字符串字面量)。其他常见的 AST 节点类型包括Call(函数调用)、Assign(赋值语句)等。
- @test.test_id("B105")
- 作用: 该装饰器为测试函数分配一个唯一的标识符(ID),方便标识和引用测试规则。这个 ID 用于在扫描报告中标识问题的来源,也用于启用、禁用特定测试规则。
- 参数:
"B105"是分配给该测试函数的唯一标识符。通常,Bandit 的测试 ID 以字母B开头,后面跟随三位数字。
自定义模板思路
-
将自定义的模板 py 文件放入 plugins 目录下或 blacklists 目录下
-
plugins:在函数上加上 @test 相关注解,进行匹配逻辑编写

-
漏洞分类
身份证 描述 B1xx 系列 MISC 测试 B2xx 系列 应用程序/框架配置错误 B3xx 系列 黑名单(calls) B4xx 系列 黑名单 (imports) B5xx 系列 密码学 B6xx 系列 注入 B7xx 系列 XSS (XSS) -
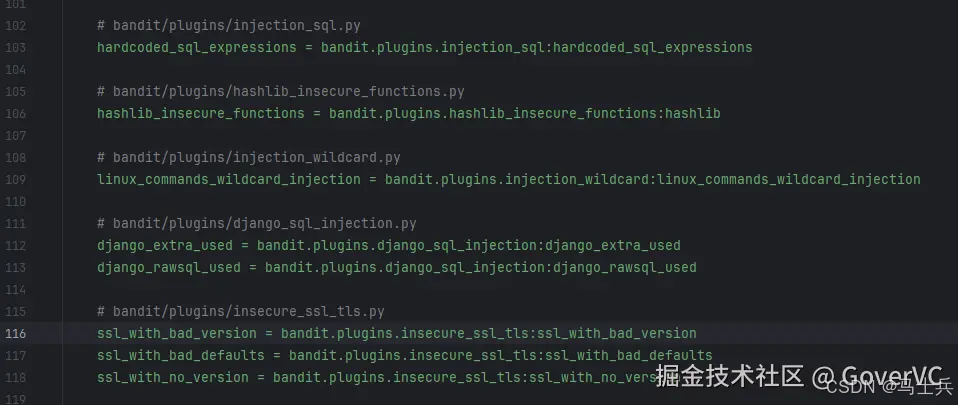
将新增的 py 文件具体信息加入 bandit\setup.cfg 文件对应位置下



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









