






欢迎来到 s a y − f a l l 的文章 欢迎来到say-fall的文章 欢迎来到say−fall的文章

前言:
继命名空间、缺省参数等基础内容之后,本篇主要讲述三个核心特性:引用、内联函数与 nullptr。它们是简化代码结构、优化程序性能的重要手段,也是不能轻易理解的知识点,尤其是引用。如何正确使用引用避免权限问题?内联函数的适用场景是什么?为何推荐用 nullptr 替代 NULL?带着这些疑问,本文彻彻底底帮你弄清楚这些概念。
文章目录
正文:
一、 引用
1. 引用基础
概念:给已有的变量“新名字”(别名)
使用:类型&引⽤别名=引⽤对象;
案例:在需要传指针的地方,可以用引用代替,不需要调用该指针,让形参就叫别名,改变形参就是改变实参
特性:
- 引用在定义的时候必须初始化
- 一个变量可以有多个引用
- 引用一旦引用一个实体,再不能引用其他实体
int a = 10;
int& ra; // 编译报错:“ra”: 必须初始化引⽤
int& b = a;
int c = 20;
// 这⾥并⾮让b引⽤c,因为C++引⽤不能改变指向,
// 这⾥是⼀个赋值
主要应用:
- 函数参数传递
- 函数返回值
引用返回值能不能随便用?
2. 引用返回注意事项:
int& func()
{
int a = 0;
return a;//错的:a是局部的,返回时候已经销毁,类似野指针
}
int& func1(int& ra)
{
ra = 3
return ra;//对的:ra是外部传入的引用,出函数依旧存在
}
3. const 引用规则:
权限可缩小不可放大,仅限制引用本身的访问权限
int main()
{
const int a = 0;
int& ra = a;//错的
const int& ra = a;//对的
//权限放大
//注意分辨:
const int a = 0;
int ra = a;//这是可以的,不是权限放大
int b = 0;
const int& rb = b;//对的
//权限缩小
//这个地方没有缩小b的权限,b依旧能该改变
b++;//对
rb++;//错
//类比:公共场合,添加一个身份,做不了一些事情(权限缩小)
int& rc = 30;//错
const int& rc = 30;//对
//const引用可以给常量取别名,单纯的引用不可以
//编译器需要⼀个空间暂存表达式的求值结果(中间值)时临时创建的⼀个未命名的对象
int rd = (a+b);//可以对临时对象赋值
int& rd = (a+b);//不可以对临时对象单纯引用(没法修改)
const int& rd = (a+b);//可以用const引用(不修改)
double d = 12.34;
int i = d;//是隐式类型转换,这个过程有临时对象
int& i = d;//不可以
const int& i = d;//可以
//下面介绍一个很好用的东西
//函数模板,T可以是任意类型
template <class T>
void func(T val)
{
//注意看这里传入的T是任意类型
//所以程序员对它进行一个引用(&T val)(防止传入的值太大拷贝成本高)
//这里传常量/临时对象/带有类型转换可以吗?不行
//最终:const &T val,这样子就什么都能传
// 使用const引用可接收:
// 1. 普通变量
// 2. 常量
// 3. 临时对象
// 4. 类型转换结果
// 类似void*的通用性
}
return 0;
}
4. 指针和引用的关系与区别
- 引用不额外开空间,指针是开一个空间来存储地址
- 引用使用必须初始化,指针不是必须要求的
- 引用只能初始化一次,不能更改,指针可以更改指向对象
- 引用可以直接访问对象(别名),指针需要解引用。
- sizeof()引用返回的是引用类型的大小,而指针则根据操作系统不一样大小不一样
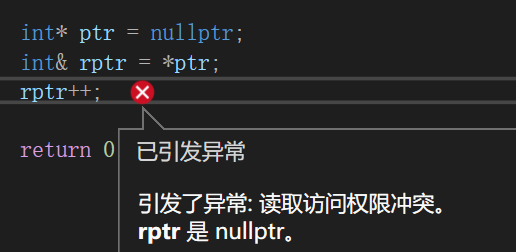
- 指针有野指针和空指针的问题,引用很少有
int* ptr = nullptr;
int& rptr = *ptr;
rptr++;
二、inline 和 宏函数
1. 宏函数
- 在C语言里有通过
#define定义的宏函数,为了防止,宏函数的使用往往小心翼翼,要加很多层括号 - 本质:预编译阶段的文本替换,不是真正的函数调用。
- 目的:在避免函数调用栈帧开销的同时,实现代码复用(比普通函数更轻量,比内联函数更「强制」替换)。
- 展示:
//正确
#define ADD(a,b) ((a)+(b))
int main()
{
int add = ADD(3,2);
return 0;
}
//错误加分号
#define ADD(a,b) ((a)+(b));
int main()
{
if (ADD(3, 2) > 0)
{
//执行某操作
}
return 0;
}
#define ADD(a,b) (a+b)
//错误不加内层括号
int main()
{
int add = ADD(1 ^ 1, 2 ^ 2);
//替换以后 =》1^(1+2)^2
return;
}
#define ADD(a,b) (a)+(b);
//错误外层无括号
int main()
{
int add = ADD(3,2) * ADD(3,2);
//替换以后 =》3+(2*3)+2
return 0;
}
以上是宏函数的使用
2. inline(内联函数)
上面宏函数都二条提到了内联函数,inline是一个关键字,他所修饰的函数称之为内联函数,上文提到宏函数是为减少函数栈帧的开销,inline也有这个作用
- 内联函数有什么用?
内联函数是一个类似”宏函数“的 函数 ,不同于宏函数,内联函数是在函数内部计算以后返回值,有的朋友要说:函数不都这样吗?其实不然,内联函数的本质是把函数的独立栈帧省略掉,直接使用调用者的栈帧。
这里插入栈帧的概念:
栈帧(也叫「活动记录」)是程序运行时,栈内存中为单个函数调用分配的一块独立内存区域,用于存储该函数的:
- 局部变量
- 函数参数
- 返回地址(函数执行完后要回到调用者的哪一行代码)
- 栈基址(EBP/RBP 寄存器,用于定位栈帧内的变量)
- 临时数据(比如表达式计算的中间结果)
- 程序的调用栈(Call Stack)就是由多个嵌套的栈帧组成的,比如
main() 调用funcA(),funcA() 又调用funcB(),栈中会依次压入:main栈帧 →funcA栈帧 →funcB栈帧(栈顶)。
比如说:在main函数中调用一个inline int add()的函数,如果去掉inline,他会创建栈帧;而加上inline变为内联函数以后就在main函数的栈帧上创建自己的栈帧,省去了跳转等操作,简单了许多
当函数 A 调用函数 B 时:
- 函数 A 是「调用者(Caller)」,它的栈帧就是「调用者的栈帧」;
- 函数 B 是「被调用者(Callee)」,它的栈帧就是「被调用者的栈帧」。
「调用者的栈帧」就是发起调用的那个函数在栈上的内存区域,在函数调用过程中,它会暂时被「被调用者的栈帧」覆盖(栈顶偏移),但调用结束后,CPU 会回到调用者的栈帧继续执行。
那内联函数好处这么多,能不能所有函数都直接前面加inline使其变成内联函数呢?
答案是 不可以 ,因为内联函数还是在调用者的内部把函数展开了,有点类似与你没有使用函数,而是直接给函数内部的代码 粘贴 到了原函数处,这大大增加了可执行文件的内存占用量。
除此之外,内联函数还有很重要的一个缺点:声明和定义不能分离在两个文件中,会导致链接失败。
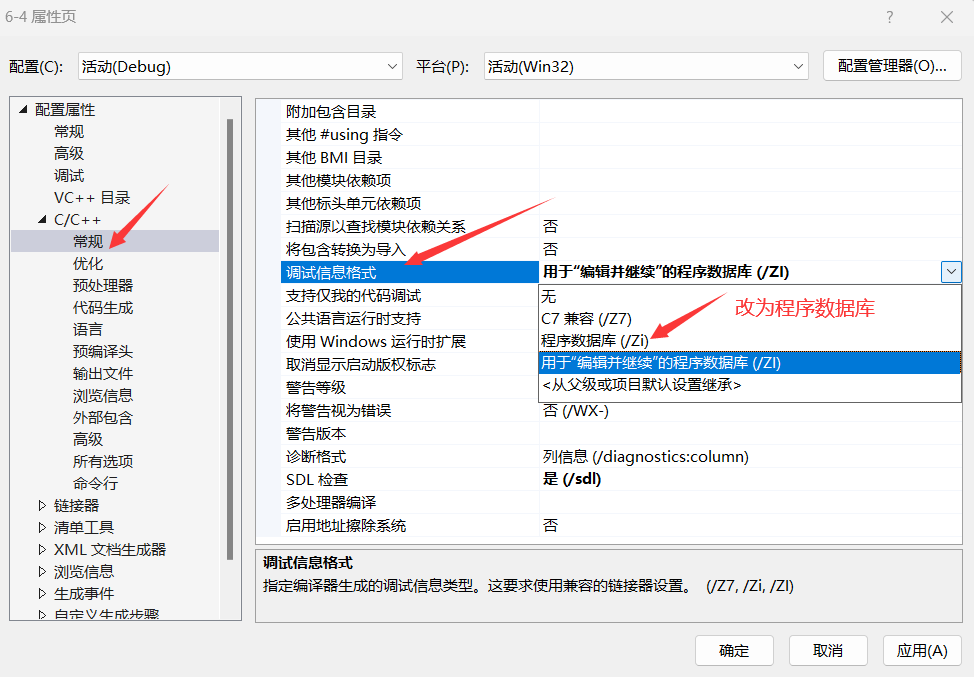
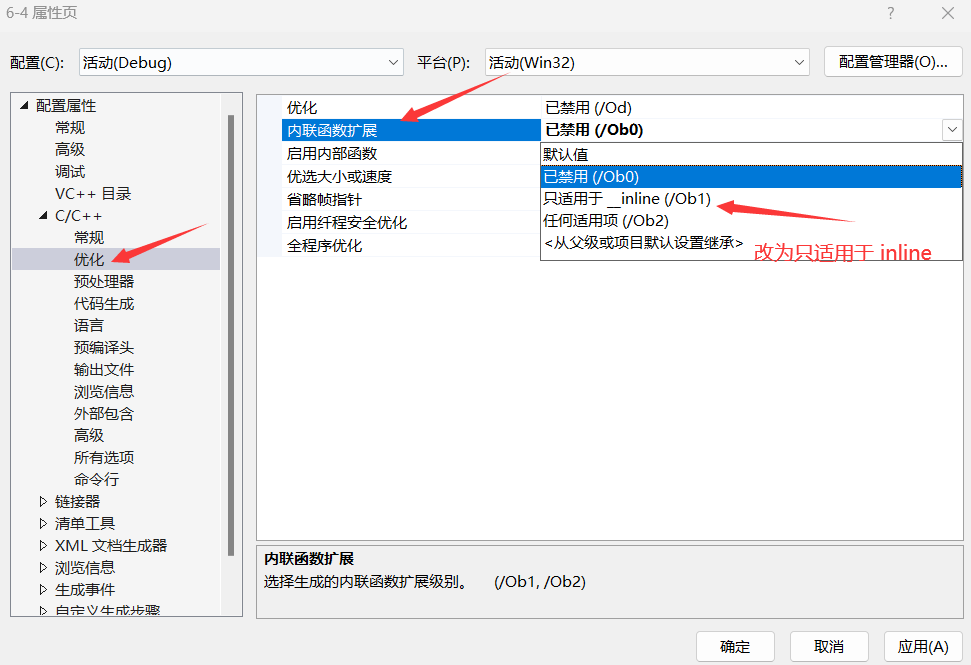
值得注意的一点是,在有些编译器(如vs2022)中,并非程序员添加inline他就变成了内联函数,这得编译器的心情(其实就是debug下,编译器会识别内联函数的代码量,如果代码量很大,就不会展开函数,而是作为一般函数调用)
如果想要调试的话,按照下方的操作可以在debug模式下调试:
- 菜单栏 - 项目 - 属性
三、 nullptr
NULL实际是⼀个宏,在传统的C头⽂件(stddef.h)中,可以看到如下代码:
#ifndef NULL
#ifdef __cplusplus
#define NULL 0
#else
#define NULL ((void *)0)
#endif
#endif
- 也就是说,在C++里面
NULL,被定义为了0,是一个int类型。 - C++11中引⼊
nullptr,nullptr是⼀个特殊的关键字,nullptr是⼀种特殊类型的字⾯量,它可以转换成任意其他类型的指针类型。使⽤nullptr定义空指针可以避免类型转换的问题,因为nullptr只能被隐式地转换为指针类型,⽽不能被转换为整数类型。
从此以后,C++里面的空指针使用
nullptr,不使用NULL。
- 本节完…

















 884
884








 到【灌水乐园】发言
到【灌水乐园】发言







