







 本文介绍了一种在简单知识库问答任务中创新纪录的方法,通过模式提取和实体链接,结合模式修正程序,以及多级编码和多维信息,增强关系检测和事实选择,实现高效问题解答。
本文介绍了一种在简单知识库问答任务中创新纪录的方法,通过模式提取和实体链接,结合模式修正程序,以及多级编码和多维信息,增强关系检测和事实选择,实现高效问题解答。
这是何世柱老师团队发表于COLING2018的一篇文章。
一. 文章贡献:
- 提出进行模式提取和实体链接,并提出模式修改程序来缓解错误传播问题
- 学习对候选主谓词对进行排序以使得能够在给出问题的情况下进行相关事实检索,我们建议通过关系检测来增强联合事实选择。利用多级编码和多维信息(计算语义相似性,问题话语和主语谓语对的多级编码)来加强整个过程
- 我们的方法在Simple KB-QA任务中创造了一项新记录
二 .数据集: Simple Questions
三. 网络模型:
1. 模式提取和实体链接
要解决的问题:
- 识别问题中连接到KB中实体的提及范围 (mention span) ----模式提取
- 生成问题应该引用的KB中的候选实体 (subject entities) ----实体链接(通过模式修改得到增强)
方法:
- 模式提取
- 通常是使用所有N-gram来检索KB中的候选主题,但由于大量非主题N-gram,导致候选池noise太大。
- 本文将问题表达分为两部分:涉及跨度以及问题模式(mention span 和 question pattern),其中涉及跨度是以引用KB中实体的比较少用的词,问题模式包含常用的反映问题表达所指代的关系的单词。
- 可以看做一个连续的标签任务,将少见的涉及跨度的连续词分为一种,相对常见的问题模式的词标记为另一种。
- 所以模式提取环节的主要任务是训练模型来预测文本涉及跨度中指向主题的连续词。
- 最终问题被分割为(mention,pattern)对。
-
模式修正:
上面模式提取中由于顺序标记模型的性能,在(mention,pattern)对中存在一些不好的结果,比如:上面模式提取中由于顺序标记模型的性能,在(mention,pattern)对中存在一些不好的结果,比如:
- 常见的错误有mention span标记错误
- 更严重的错误比如mention是问题表达本身,pattern为空。

所以对以上进行模式修正来增加好的pattern。该部分基于数据集中常见词组成的问题模式应该多次出现,pattern出现的次数越多越正确,保留所有提取的次数大于1的pattern作为pattern base Pn,原始问题作为句子表达baseQn。对于每个句子,重新评估其提取模式来实体找到更合适的模式。
- 实体链接:找到每个问题的mention span(用来链接KB中的实体)。基于mention span,我们用里面的每个单词来检索subject entities并选择得分最高的K个实体(这里通过最长公共子序列??没太懂)。
2. 关系检测和事实选择
- 关系检测增强
-
对于一个问题,相关联的实体有很多,为了简化问题,对关联实体进行排序,找出前K个最接近于gold fact的 candidate实体,训练了一个关系检测网络将每个问题表达映射为最可能的pridicate。
-
predicates用不同粒度来表示,分别是predicate-level和word-level,其中word-level作为predicate-level的补充来减轻数据稀疏性,因为好多predicate名称没有在训练数据集中出现
-
用问题表达作为关系检测器的输入。相似性分数srel(r, q) 是问题表达的LSTM 编码和predicate嵌入的cos距离。
-
提取candidate subject的显著类型作为类型信息,利用word-level LSTM 编码器来获取类型信息编码。然后再综合考虑predicate和word level类型信息,获取candidate subject的类型信息。
-
对于关联实体e和对应的关系Re,生成最终的分数。选择top-N entities生成事实池。
-
对于事实池中的每个subject entity s,有对应的predicate set Ps,问题转化为一个事实选择问题或者称为一个匹配问题。给定问题q(mention,pattern),subject entities和predicates,事实选择模型联合找出最匹配问题提的subject和predicate.
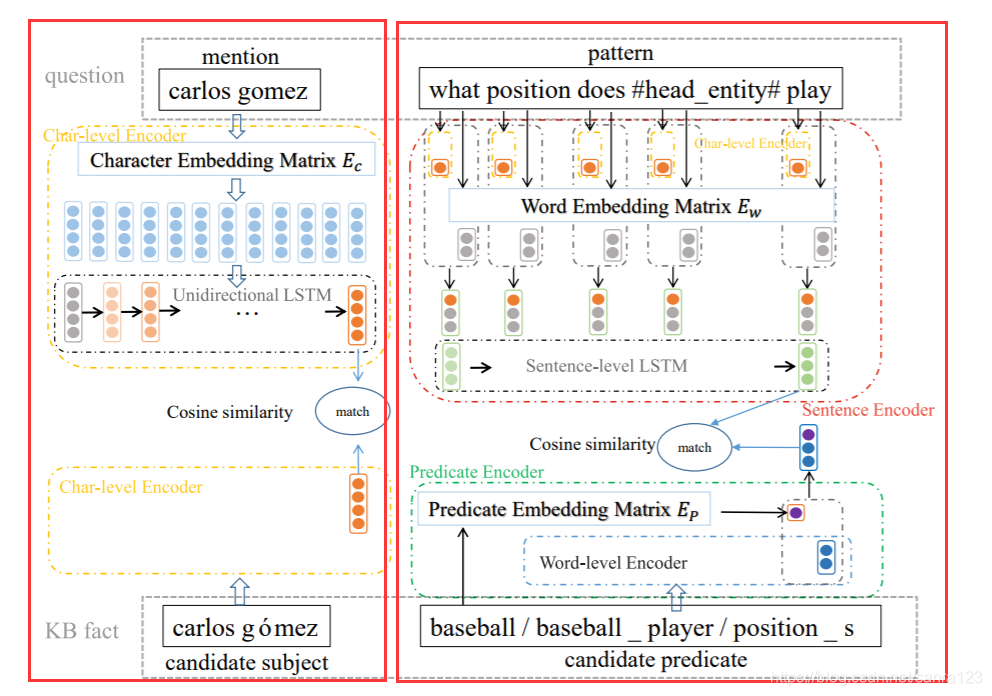
- 主题匹配网络:
- 计算问题的mention span和Predicate实体的相关性。由于单词嵌入的范围有限,实体名称中很多次都是OOV单词。计算问题的mention span和Predicate实体的相关性。由于单词嵌入的范围有限,实体名称中很多次都是OOV单词。
- 因此用character-level的RNN编码来编码mention span和candidate subject’s 名字,来减少OOV。
- predicate匹配:
-
将从问题表达中提取的模式和相应的candidate predicate进行匹配
-
【问题模式编码】和【predicate编码】,然后计算相似度

















 987
987

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









