






消息队列应用场景
- 缓存/削峰:有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。
- 解耦:允许开发人员独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
- 异步通信:允许用户把消息放入队列,但并不立即处理它,然后在需要的时候再去处理它们。
消息队列的两种模式
- 点对点模式
- 发布/订阅模式
- 可以有多个 topic
- 消费者消费数据后,不删除数据
- 每个消费者相互独立,都可以消费到数据
Kafka 分区的好处
- 便于合理使用存储资源。每个 Partition 在一个 Broker 上存储,可以把海量的数据按照分区切割成一块一块数据存储在多台 Broker 上。
- 提高并行度。生产者可以以分区为单位发送数据;消费者可以以分区为单位进行消费数据。
生产者如何提高吞吐量
- batch.size:批次大小,默认 16K
- liger.ms:等待时间,修改为 5-100ms
- compression.type:压缩 snappy
- RecordAccumulator:缓冲区大小,默认32M,修改为 64M
ACK 应答级别
- 0:生产者发送过来的数据,不需要等数据落盘就应答
- 1:生产者发送过来的数据,Leader 收到数据后应答
- -1:生产者发送过来的数据,Leader 和 ISR 队列里面的所有节点收齐数据后应答
数据完全可靠条件 = ACK级别设置为 -1 + 分区副本 >= 2 + ISR 里应答的最小副本数量 >= 2
幂等性原理
<PID,Partition,SeqNumber> 来确定唯一消息
- PID 是 Kafka 每次重启都会重新分配一个新的
- Partition 标识分区号
- SeqNumber 是单调自增
生产者事务
开启事务,必须开启幂等性。
默认有50个分区,每个分区负责一部分事务。事务划分是根据 transactional.id 的 hashcode 值 % 50,计算出该事务属于哪个分区,该分区的 Leader 副本所在 broker 节点即为这个事务对应的 Transaction Coordinator (事务协调器)节点。
解决数据乱序
- kafka 在 1.x 版本之前保证数据单分区有序,条件如下:
max.in.flight.requests.per.connection=1 - kafka 在 1.x 版本及以后保证数据单分区有序,条件如下:
未开启幂等性:max.in.flight.requests.per.connection=1
开启幂等性:max.in.flight.request.per.connection 需要设置小于等于 5
原因:kafka 1.x 以后,启用幂等性后,kafka 服务端会缓存 producer 发来的最近 5 个 request 的元消息,所以无论如何,都可以保证最近 5 个 request 的数据都是有序的。
文件清理策略
- delete 日志删除
- compact 日志压缩
高效读写数据
- Kafka 本身是分布式集群,可以采用分区技术,并行度高
- 读数据采用稀疏索引,可以快速定位要消费的数据
- 顺序写磁盘:Kafka 的 Producer 生产数据,要写入到 log 文件中,写的过程是一直追加到文件末端,为顺序写。官网有数据表明,同样的磁盘,顺序写能到 600M/s,而随机写只有 100K/s。这与磁盘的机械结构有关,顺序写之所以快,是因为省去了大量磁头寻址的时间。
- 零拷贝:Kafka 的数据加工处理操作交由 Kafka 生产者和 Kafka 消费者处理。Kafka Broker 应用层不关心存储的数据,所以就不用走应用层,传输效率高。
- PageCache 页缓存: Kafka 重度依赖底层操作系统提供的 PageCache 功能。当上层有写操作时,操作系统只是将数据写入 PageCache。当读操作发生时,先从 PageCahce 查找,如果找不到,再去磁盘读取。实际上 PageCache 是把尽可能多的空闲内存都当做了磁盘缓存来使用。
消费者组初始化流程
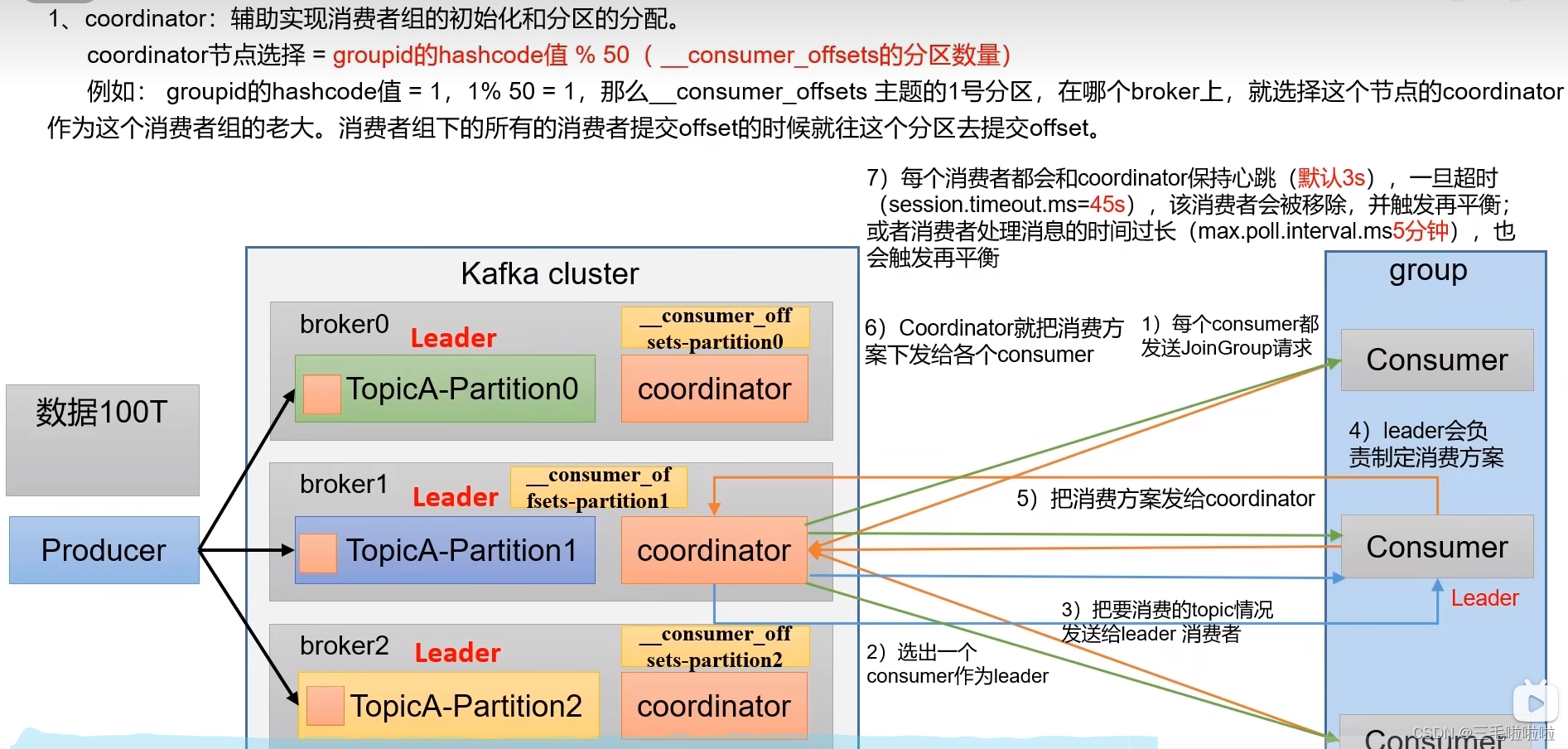
消费者组详细消费流程
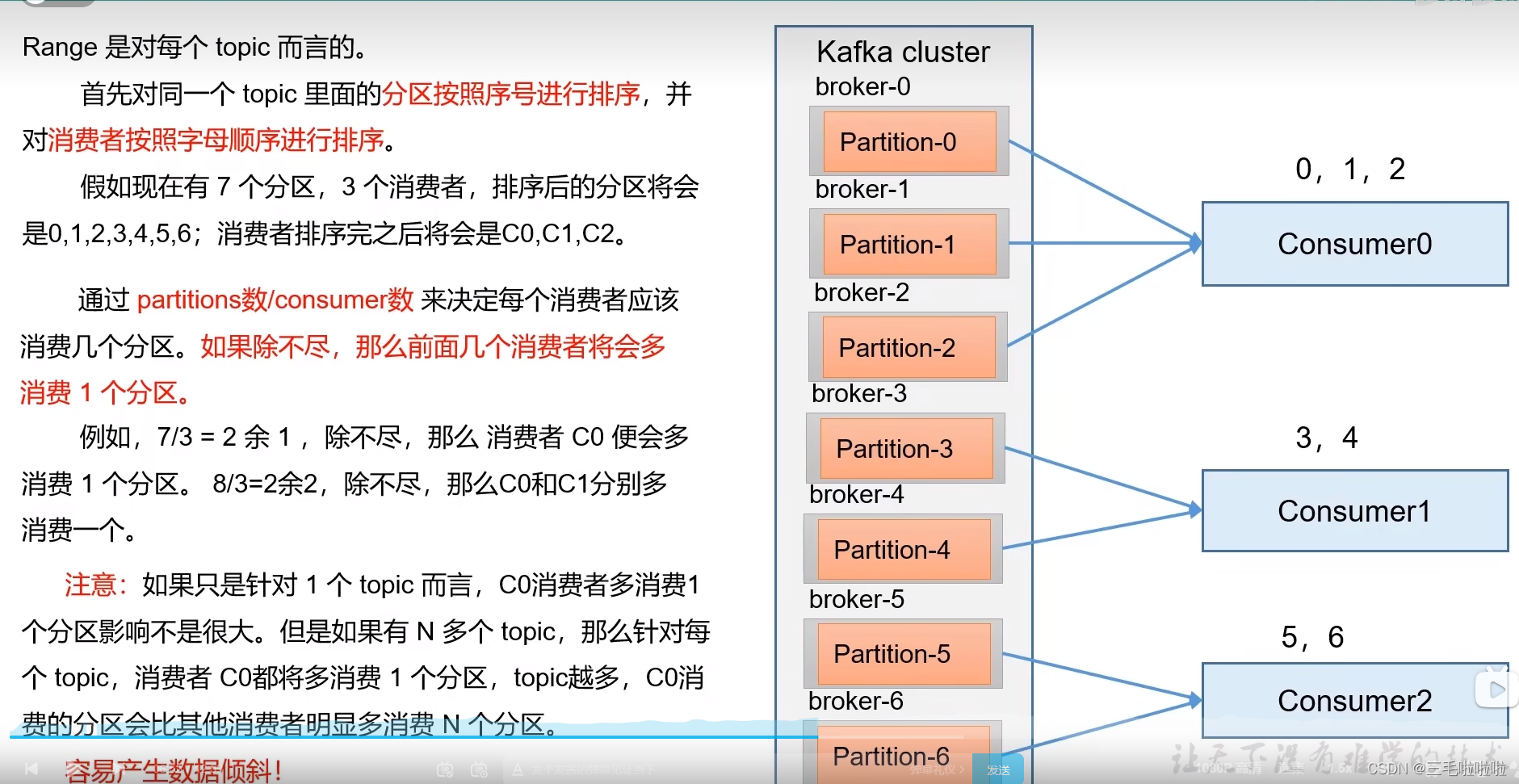
分区分配策略
-
Range
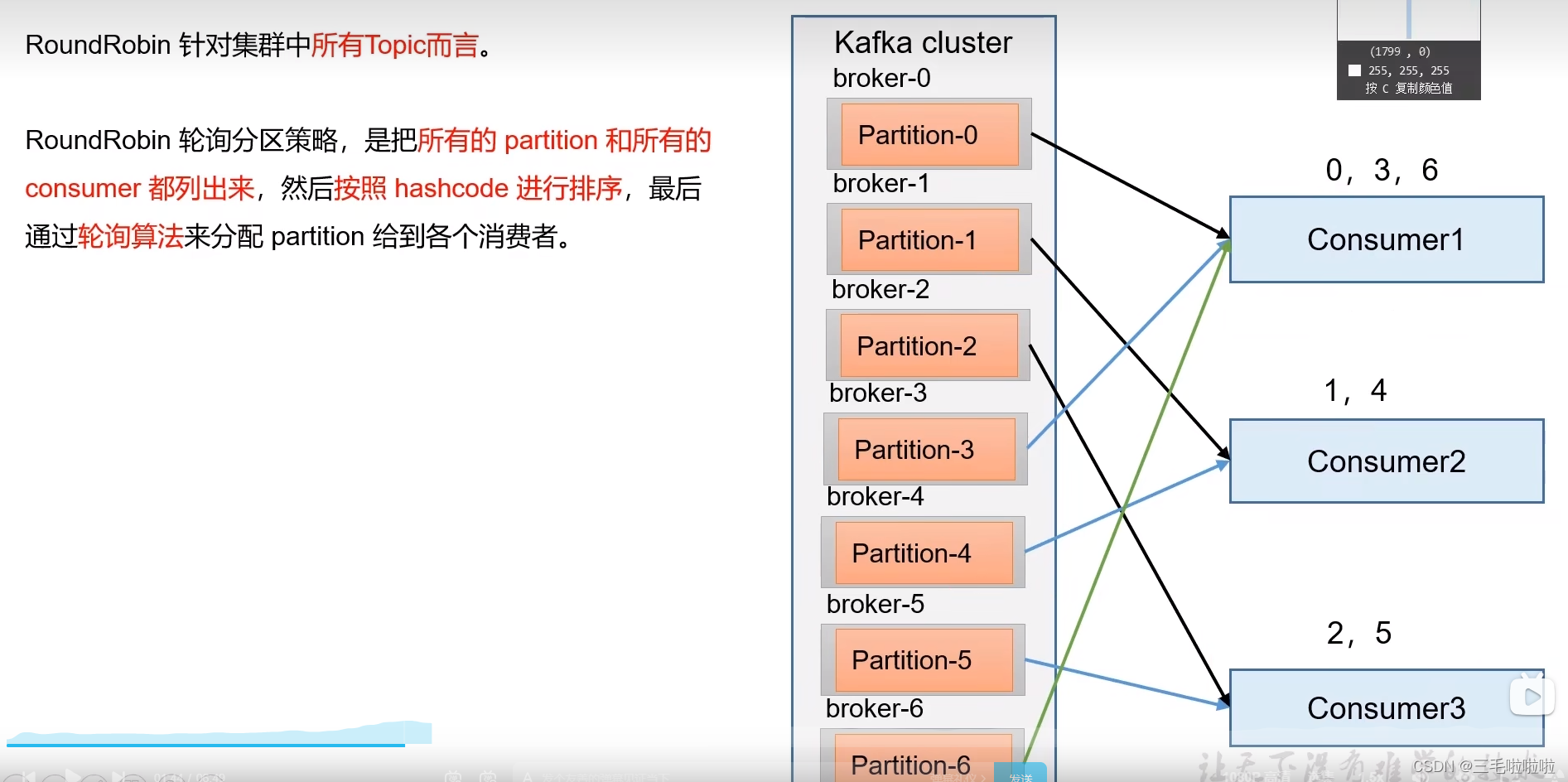
-
RoundRobbin
-
Sticky:粘性分区可以理解为分配的结果带有“粘性的”。即在执行一次新的分配之前,考虑上一次分配的结果,尽量少的调整分配的变动,可以节省大量的开销。
指定 Offset 消费
auto.offset.reset = earliest | latest | none(默认是 latest)
- earliest:自动将偏移量重置为最早的偏移量。–from-beginning
- latest: 自动将偏移量重置为最新偏移量。
- none:如果未找到消费者组的先前偏移量,则向消费者抛出异常。
- 任意指定 offset 位移开始消费
- 指定时间消费
重复消费
自动提交 offset 引起
漏消费
设置 offset 为手动提交,当 offset 被提交时,数据还在内存中未落盘,此时消费者线程被 kill 掉,那么 offset 已经被提交,但是数据未处理,导致这部分内存中的数据丢失。
消费者提高吞吐量
- 增加分区数
- 增加消费者数量(消费者数量 = 分区数)
- 提高每批次拉取的数量
Kafka-Kraft 模式的优点
- Kafka 不在依赖外部框架,而是能够独立运行
- controller 管理集群时,不再需要从 zookeeper 中先读取数据,集群性能上升
- 集群扩展时,不再收到 zookeeper 读写能力限制
- controller 不再动态选举,而是由配置文件规定。这样我们可以有针对性的加强 controller 节点的配置,而不是像以前一样对随机 controller 节点的高负载束手无策

















 20万+
20万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









