










 本文探讨了在PyTorch环境下使用MKLDNN进行模型推理优化的方法,包括如何利用MKLDNN加速卷积计算,以及通过调整OpenMP线程调度策略进一步提升CPU推理性能。
本文探讨了在PyTorch环境下使用MKLDNN进行模型推理优化的方法,包括如何利用MKLDNN加速卷积计算,以及通过调整OpenMP线程调度策略进一步提升CPU推理性能。
最近在pytorch下面做模型推理,官网pytorch默认就用了MKLDNN做优化,在pytorch里MKLDNN的多核多线程的调度用了OpenMP来做控制,所以可以用设置OpenMP环境的方法来控制OpenMP的调度逻辑,这里面发现一些有趣的现象。
首先做一些代码修改以便在pytorch下面最大程度的利用MKLDNN加速
通过设置环境变量MKLDNN_VERBOSE=1来观察默认pytorch里MKLDNN的运行信息
mkldnn_verbose,info,Intel MKL-DNN v0.21.1 (commit 7d2fd500bc78936d1d648ca713b901012f470dbc)
mkldnn_verbose,info,Detected ISA is Intel AVX2
mkldnn_verbose,exec,reorder,jit:uni,undef,in:f32_oihw out:f32_Ohwi8o,num:1,64x3x7x7,0.0109863
mkldnn_verbose,exec,convolution,jit:avx2,forward_training,fsrc:nchw fwei:Ohwi8o fbia:undef fdst:nChw8c,alg:convolution_direct,mb1_ic3oc64_ih512oh256kh7sh2dh0ph3_iw512ow256kw7sw2dw0pw3,14.6831
mkldnn_verbose,exec,reorder,jit:uni,undef,in:f32_nChw8c out:f32_nchw,num:1,1x64x256x256,9.35596
mkldnn_verbose,exec,reorder,jit:uni,undef,in:f32_nchw out:f32_nChw8c,num:1,1x64x128x128,0.699951
mkldnn_verbose,exec,reorder,jit:uni,undef,in:f32_oihw out:f32_OIhw8i8o,num:1,64x64x3x3,0.027832
mkldnn_verbose,exec,convolution,jit:avx2,forward_training,fsrc:nChw8c fwei:OIhw8i8o fbia:undef fdst:nChw8c,alg:convolution_direct,mb1_ic64oc64_ih128oh128kh3sh1dh0ph1_iw128ow128kw3sw1dw0pw1,10.8818
mkldnn_verbose,exec,reorder,jit:uni,undef,in:f32_nChw8c out:f32_nchw,num:1,1x64x128x128,1.10791
mkldnn_verbose,exec,reorder,jit:uni,undef,in:f32_nchw out:f32_nChw8c,num:1,1x64x128x128,0.687012
mkldnn_verbose,exec,reorder,jit:uni,undef,in:f32_oihw out:f32_OIhw8i8o,num:1,64x64x3x3,0.0280762
mkldnn_verbose,exec,convolution,jit:avx2,forward_training,fsrc:nChw8c fwei:OIhw8i8o fbia:undef fdst:nChw8c,alg:convolution_direct,mb1_ic64oc64_ih128oh128kh3sh1dh0ph1_iw128ow128kw3sw1dw0pw1,10.582
mkldnn_verbose,exec,reorder,jit:uni,undef,in:f32_nChw8c out:f32_nchw,num:1,1x64x128x128,1.13208
mkldnn_verbose,exec,reorder,jit:uni,undef,in:f32_nchw out:f32_nChw8c,num:1,1x64x128x128,0.660889
mkldnn_verbose,exec,reorder,jit:uni,undef,in:f32_oihw out:f32_OIhw8i8o,num:1,64x64x3x3,0.0280762
- 可以看到默认pytorch下面默认只用mkldnn来做卷积计算,reorder加在convolution前后负责把内存调整成最适合卷积计算的格式并且在计算后把内存再调回pytorch需要的内存格式;卷积之外的其他计算都用pytorch里的代码
接下可以参考这篇General guidelines for CPU performance on PyTorch上的文章把模型中MKLDNN能支持的运算方法都换成MKLDNN的版本。具体的方法是把
output = model(input)改为
input_ = input.to_mkldnn()
model_ = torch.utils.mkldnn.to_mkldnn(model)
output_ = model_(input_)
output = output_.to_dense()修改后pytorch里MKLDNN的运行信息为
mkldnn_verbose,exec,reorder,simple:any,undef,in:f32_nchw out:f32_nchw,num:1,1x3x512x512,0.160156
mkldnn_verbose,exec,convolution,jit:avx2,forward_training,fsrc:nchw fwei:Ohwi8o fbia:x fdst:nChw8c,alg:convolution_direct,mb1_ic3oc64_ih512oh256kh7sh2dh0ph3_iw512ow256kw7sw2dw0pw3,14.6609
mkldnn_verbose,exec,batch_normalization,jit:avx2,forward_inference,fdata:nChw8c fdiff:undef,flags:3,mb1ic64ih256iw256,6.22388
mkldnn_verbose,exec,eltwise,jit:avx2,forward_training,fdata:nChw8c fdiff:undef,alg:eltwise_relu,mb1ic64ih256iw256,1.27002
mkldnn_verbose,exec,pooling,jit:avx,forward_training,fdata:nChw8c fws:nChw8c,alg:pooling_max,mb1ic64_ih256oh128kh3sh2ph1_iw256ow128kw3sw2pw1,3.57104
mkldnn_verbose,exec,convolution,jit:avx2,forward_training,fsrc:nChw8c fwei:OIhw8i8o fbia:x fdst:nChw8c,alg:convolution_direct,mb1_ic64oc64_ih128oh128kh3sh1dh0ph1_iw128ow128kw3sw1dw0pw1,11.5671
mkldnn_verbose,exec,batch_normalization,jit:avx2,forward_inference,fdata:nChw8c fdiff:undef,flags:3,mb1ic64ih128iw128,2.31396
mkldnn_verbose,exec,eltwise,jit:avx2,forward_training,fdata:nChw8c fdiff:undef,alg:eltwise_relu,mb1ic64ih128iw128,0.333984
mkldnn_verbose,exec,convolution,jit:avx2,forward_training,fsrc:nChw8c fwei:OIhw8i8o fbia:x fdst:nChw8c,alg:convolution_direct,mb1_ic64oc64_ih128oh128kh3sh1dh0ph1_iw128ow128kw3sw1dw0pw1,11.6409
- 大量的reorder的操作在调用mkldnn_utils.to_mkldnn(model)时候就完成了,在推理时不再调用,节省了时间
- 对于batch_normal, Relu和sum操作都用了mkldnn的版本,速度更快
这样几句代码能够让我的resnet模型CPU推理有大约80%的性能提升
接下来看看调整OpenMP调度逻辑对性能的影响
这里主要通过3个环境变量来设置
- OMP_NUM_THREADS 告诉OpenMP每个推理进程用多少线程来跑,建议设置为当前CPU物理核心数
- KMP_AFFINITY 控制OpenMP调度线程的逻辑,对于有超线程HT的CPU来说,此设置控制线程只在同一个物理核上调度 (相同参数在windows和linux下调度逻辑不同)(默认设置线程可以在所有逻辑核之间调度) verbose表示打印运行时调度信息
- KMP_SETTING 控制打印OpenMP的设置信息
先上结果, 我用的CPU是i7-7700 4核8线程
- 默认模式,只打开KMP输出
export KMP_SETTINGS=1此时用8个线程做推理,CPU占用率800%
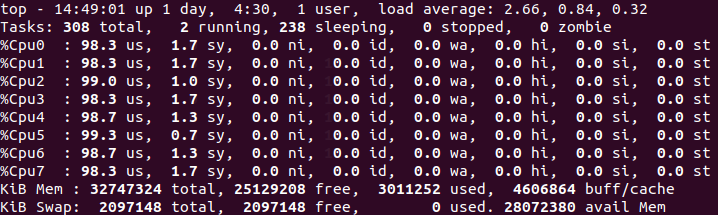
推理速度为8.25FPS
- 用4个线程推理
export KMP_SETTINGS=1
export OMP_NUM_THREADS=4此时CPU占用率400%, OpenMP默认每个线程对应一个CPU物理核,但是线程会在对应物理核上的2个逻辑核之间调度 (截图的时候线程4正在CPU逻辑核3,7之间切换, 在Linux里物理核3的2个逻辑核是CPU3,7)
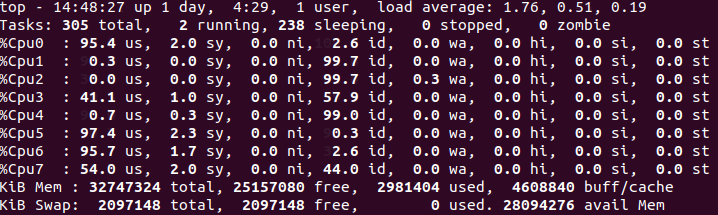
推理速度为8.29FPS
- 用4个物理核推理,同时禁止线程在同一物理核的2个逻辑核之间调度
export OMP_NUM_THREADS=4
export KMP_SETTINGS=1
export KKMP_AFFINITY=granularity=fine,compact,1,0 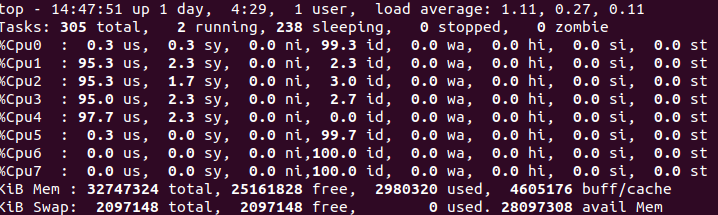
推理速度为8.46FPS
总的测试结果为,在4核8线程CPU上
| 默认设置 8线程 | 8.25FPS |
| 设置线程数为每线程对应一个物理核 4线程 | 8.29FPS |
| 设置线程数为每线程对应一个物理核,线程锁定逻辑核,4线程 | 8.46FPS |
结论
- 推理时不是所有CPU的逻辑核都用上速度最快,最好是有多少物理核起多少线程
- 有超线程的时候,禁止线程在物理核的2个逻辑核之间调度可以获得更好的性能
下面是个人对上面测试结果的一点分析和理解

从Intel的CPU架构上看,一个支持HT的物理核心上有2个逻辑核心,这2个逻辑核心分别有各自的独立寄存器组(AS),但是共享一组运算单元(也就是说即使2个逻辑核心各有一个线程在同时做重度运算的工作,如果运算部分的代码优化的足够好,那么双线程并发的运算速度不会比单线程来的快)。HT的优点是当2个线程(或进程)分别运行在2个逻辑核心上时,如果一个线程上的工作负载不能完全占满运算单元(ALU)时,另一个线程也可以把一些计算负载放进这个ALU里做,从而达到提高运算单元效率的目的。如果一个线程把这个物理核的运算单元都占满的话,另一个线程再想做一些运算就只能等着,无法达到1+1=2的目的。同时因为2个逻辑核心有自己独立的寄存器组,所以线程在这2个逻辑核间调度时候保存和恢复线程时不需要把所有的寄存器保存到内存里,可以很高效的切换。
结论:对于重度计算的应用场景,如果代码写的足够高效,一个物理核只跑一个线程就够了。如果是密集的I/O运算,可以一个物理核上跑2个线程,一个线程要等待从I/O传输数据的时候,可以快速切换到另一个线程运行。
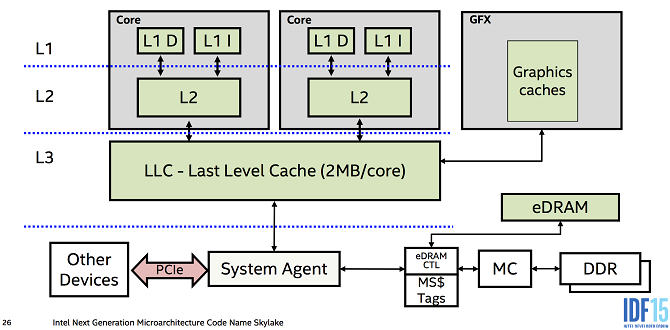
从这个图片可以看出来,一个线程在不同物理核之间切换的时候,因为不同物理核有各自不同的L1/L2缓存,所以线程切换物理核的时候会造成L1/L2缓存全部失效,再有内存读取的时候需要重新从内存里抓取,降低效率。
结论:对于大部分的应用场景,最好把运行线程绑死在一个物理核或者逻辑核上,这样可以提高程序运行效率。
对于OpenVINO, 线程的调度库默认用的是TBB,不是用的OpenMP。但是是基于相同的设计理念。在运行自带的sample里的benchmark_app的帮助里可以看到默认就是线程和物理核绑定的。具体的可以看官网benchmark_app的说明文档
-pin "YES"/"NO"/"NUMA" Optional. Enable threads->cores ("YES", default), threads->(NUMA)nodes ("NUMA") or completely disable ("NO") CPU threads pinning for CPU-involved inference.
最后一点经验是:
现代CPU的物理核数越来越多了,对于超多核数的CPU而言,比起只用一个推理请求,靠Pytorch或者OpenVINO推理框架把计算量分配到各个CPU核心的方法;更好的方法是多起几个推理请求,手工把CPU的物理核心分配的各个推理请求上。例如对于8核16线程的CPU,起4个推理请求,每个推理请求分配2个物理核心来运算,这么处理下来的推理速度要快于单推理请求,后面16个逻辑核一起处理一个推理请求的速度要快的多,毕竟人脑是最好的优化器 :)

















 933
933

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









