



 本文介绍了计算机视觉中的目标检测任务,包括人脸检测与人脸识别的区别,以及目标检测在证件检测中的应用。详细讨论了流行的目标检测算法,如基于RegionProposal的R-CNN系算法和Yolo、SSD等one-stage算法的特点和优缺点。
本文介绍了计算机视觉中的目标检测任务,包括人脸检测与人脸识别的区别,以及目标检测在证件检测中的应用。详细讨论了流行的目标检测算法,如基于RegionProposal的R-CNN系算法和Yolo、SSD等one-stage算法的特点和优缺点。
对于计算机视觉,大家最熟悉的是人脸识别。注意,人脸识别和人脸检测是不同的概念。人脸检测,是在图像中找出人脸并给出位置;人脸识别,不仅要从图像中找出人脸,并要识别出人脸对应的人的信息。
人脸检测是目标检测的一个例子。
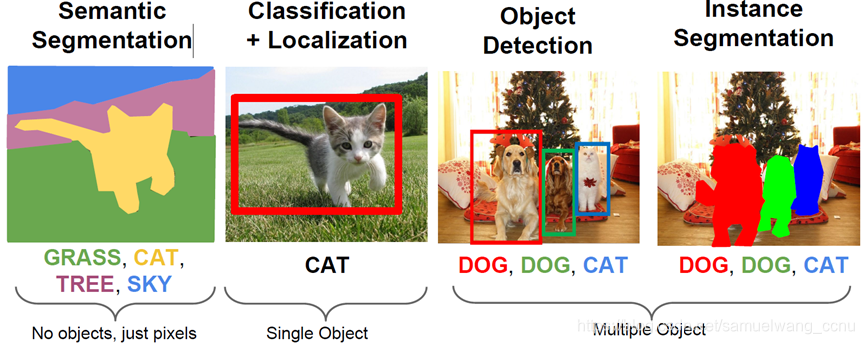
计算机视觉最基本的任务之一是图像分类。在图像分类的基础上,还有更复杂和有趣的任务,如目标检测、物体定位、图像分割等。
目标检测是要在图像中识别出指定类的对象,并给出其位置。由于图像中目标的个数和位置都是不固定的,所以,目标检测
任务并不简单。
目标检测的一个应用场景是证件检测。在证件检测场景中,需要从图像中检测出是否出示了指定的证件(比如,二代身份证),从而对图像中的行为作出判断。
目标检测算法,比较流行的分为两类,一类是基于Region Proposal的R-CNN系算法(R-CNN,Fast R-CNN, Faster R-CNN),它们是two-stage的,需要先使用启发式方法(selective search)或者CNN网络(RPN)产生Region Proposal,然后再在Region Proposal上做分类与回归。而另一类是Yolo,SSD这类one-stage算法,其仅仅使用一个CNN网络直接预测不同目标的类别与位置。第一类方法是准确度高一些,但是速度慢,但是第二类算法是速度快,但是准确性要低一些。
Yolo算法,其全称是You Only Look Once: Unified, Real-Time Object Detection。顾名思义就是只看一次,把目标区域预测和目标类别预测合二为一,作者将目标检测任务看作目标区域预测和类别预测的回归问题。该方法采用单个神经网络直接预测物品边界和类别概率,实现end-to-end的物品检测。


















 3003
3003

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









