



前言
有的时候看个视频太卡了,就想把视频搞下来,一些网站吧,它不让下载,而且还是ts流视频,于是就做了个m3u8视频下载器第一版本,如果大家使用的时候有问题,欢迎在评论区留言哦。
一、获取网站的m3u8文件url
打开想看的视频,然后F12打开控制台,找网络,里边搜索m3u8,然后刷新页面
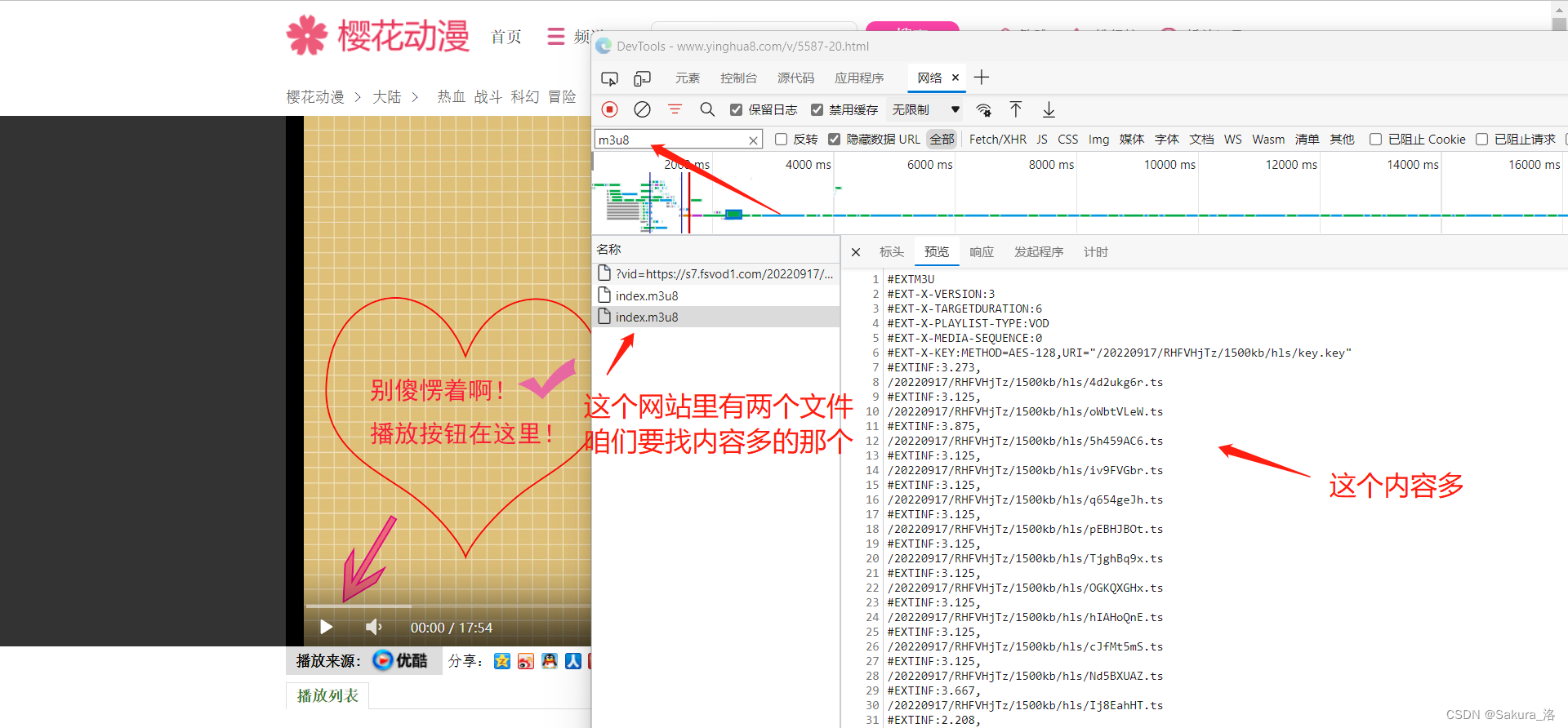
将url复制出来,后续用。
二、使用步骤
1.修改配置文件
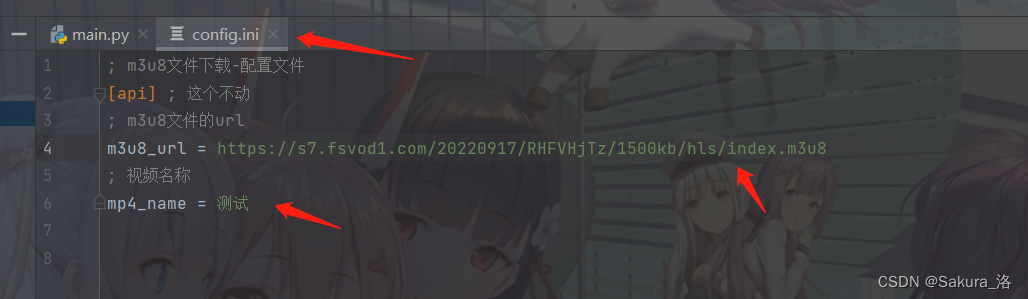
2.运行py或者exe
# -*- coding: utf-8 -*-
import os
import re
from concurrent.futures import ThreadPoolExecutor, as_completed
from configparser import ConfigParser
import requests
from Crypto.Cipher import AES
import subprocess
tPool = ThreadPoolExecutor(max_workers=30)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36 Edg/106.0.1370.42',
'Connection': 'close'
}
cryptor = None
tasks = []
def build_mk_ts():
mk_ts_path = os.getcwd() + r'\ts'
if not os.path.exists(mk_ts_path):
os.mkdir(mk_ts_path)
def set_file_name(file_name):
illegal_char = ['\\', '/', ':', '*', '?', '"', '<', '>', '|']
for char in illegal_char:
file_name = file_name.replace(char, '-')
return file_name
def read_config():
config = ConfigParser()
config_path = os.getcwd() + r'\config.ini'
config.read(config_path, encoding='utf-8')
return config
def m3u8_down(m3u8_url):
resp = requests.get(m3u8_url, headers=headers)
resp.raise_for_status()
m3u8_text = resp.text
return m3u8_text
def url_merge(m3u8_url, url):
m3u8_url_li = m3u8_url.split('/')
url_li = url.split('/')
for _ in url_li:
if len(_) != 0:
if _ in m3u8_url_li:
index = m3u8_url_li.index(_)
url_head = ('/').join(m3u8_url_li[:index])
else:
url_head = ('/').join(m3u8_url_li[:-1])
break
if url[0] == '/':
return url_head + url
else:
if len(url_head) != 0:
return url_head + '/' + url
else:
return url_head + url
def m3u8_analysis(m3u8_url, m3u8_text):
global cryptor
if "#EXT-X-KEY:METHOD=" in m3u8_text:
key_url = re.findall('URI="(.*?)"', m3u8_text)[0]
key_url = url_merge(m3u8_url, key_url)
resp = requests.get(key_url, headers=headers)
resp.raise_for_status()
key = resp.content
cryptor = AES.new(key, AES.MODE_CBC, key)
ts_url_li = re.findall('#EXTINF.*?,\n(.*)', m3u8_text)
return ts_url_li
def ts_down(index, ts_url, m3u8_url):
ts_url = url_merge(m3u8_url, ts_url)
resp = requests.get(ts_url, headers=headers, timeout=5)
resp.raise_for_status()
by = resp.content
if cryptor:
by = cryptor.decrypt(by)
with open(f'{os.getcwd()}\\ts/{str(index).zfill(5)}.ts', 'wb') as f:
f.write(by)
def ts_merge(mp4_name):
mp4_name = set_file_name(mp4_name)
if 'mp4' not in mp4_name.lower():
mp4_name += '.mp4'
cmd = rf'copy /b {os.getcwd()}\ts\*.ts {os.getcwd()}\ts\{mp4_name}'
subprocess.run(cmd, shell=True)
del_cmd = rf'del /Q {os.getcwd()}\ts\*.ts'
subprocess.run(del_cmd, shell=True)
def run():
try:
build_mk_ts()
config = read_config()
m3u8_url = config.get('api', 'm3u8_url')
m3u8_text = m3u8_down(m3u8_url)
ts_url_li = m3u8_analysis(m3u8_url, m3u8_text)
for index, ts_url in enumerate(ts_url_li):
task = tPool.submit(ts_down, index, ts_url, m3u8_url)
tasks.append(task)
count = 0
for _ in as_completed(tasks, timeout=60 * 2):
count += 1
print(f'\r爬取进度:{int(count / len(tasks) * 100)}%', end='')
print('\n爬取完毕')
ts_merge(config.get('api', 'mp4_name'))
print('合并完成!')
except Exception as e:
print(e)
finally:
input('请手动关闭!')
if __name__ == '__main__':
run()
总结
代码中用到的aes的解密,这个兼容了需要解密的和不需要解密的,都可以使用,想直接用exe和代码文件的私信领取哦。


















 1484
1484

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









