




 本文介绍了如何使用python爬虫配合ffmpeg,批量下载经过加密的ts文件,并解密合并成mp4视频。首先分析了大鹏教育直播回放的m3u8和ts加密机制,接着找到了m3u8 URL的规律,最后展示了完整的爬虫代码,并对ffmpeg的使用进行了简单说明。
本文介绍了如何使用python爬虫配合ffmpeg,批量下载经过加密的ts文件,并解密合并成mp4视频。首先分析了大鹏教育直播回放的m3u8和ts加密机制,接着找到了m3u8 URL的规律,最后展示了完整的爬虫代码,并对ffmpeg的使用进行了简单说明。
标题
python爬虫+ffmpeg批量下载ts文件,解密合并成mp4
前言
(第一次写博客,写的不好请见谅哈~~)
目标是大鹏教育里边的直播回放,他的回放是m3u8格式的,还有ts加密,这是分析过后才知道的,大家可以忽略哈,下边会有详细的过程!
一、分析目标
先进站点看看——大鹏教育拿一个免费的课程试试,

进视频F12看代码
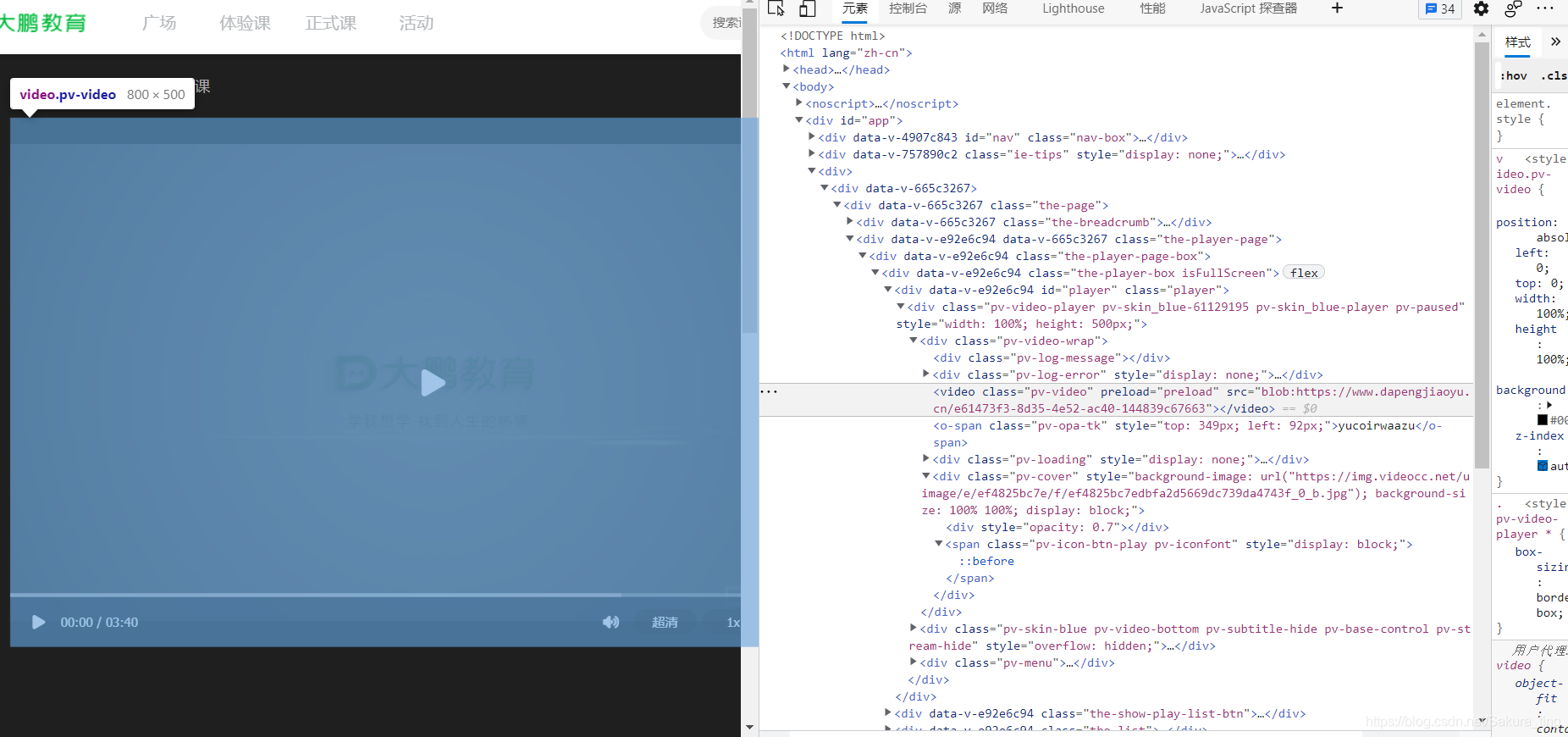
可以看到video的链接是blob加密的,这个我查了一下,看不懂,就没在这方面下手,如果有大佬会可以指点一下小弟,嘿嘿~~~
在页面搜索mp4文件,并没有

去网络中查mp4

json数据格式化以后是这样的

这里有mp4文件,但是呢,打不开

果断换方向,在网络中搜索m3u8(一般都是这个套路,要有这个敏感性)

直接找URL的,别的300的表示响应为m3u8,是ts文件,

这里有两个url,先看下边那个,可以发现是表示清晰度

可以看到第一个url里边是ts文件,还有一个key,这说明ts加密了,你下载ts不解密是看不了的,ffmpeg有解密功能
二、寻找url规律
我们做的是批量爬取,一定要去找url的规律,然后写代码,批量爬取。
m3u8的url: https://hls.videocc.net/ef4825bc7e/f/ef4825bc7edbfa2d5669dc739da4743f_3.m3u8?pid=1627609329566X1284092&device=desktop
实测?后的可以删除,不影响,删除后为:
https://hls.videocc.net/ef4825bc7e/f/ef4825bc7edbfa2d5669dc739da4743f_3.m3u8
再去查看别的视频的m3u8视频,可以发现https://hls.videocc.net/ef4825bc7e/f/
是一样的,改变的是ef4825bc7edbfa2d5669dc739da4743f_3这个
还记得这个嘛
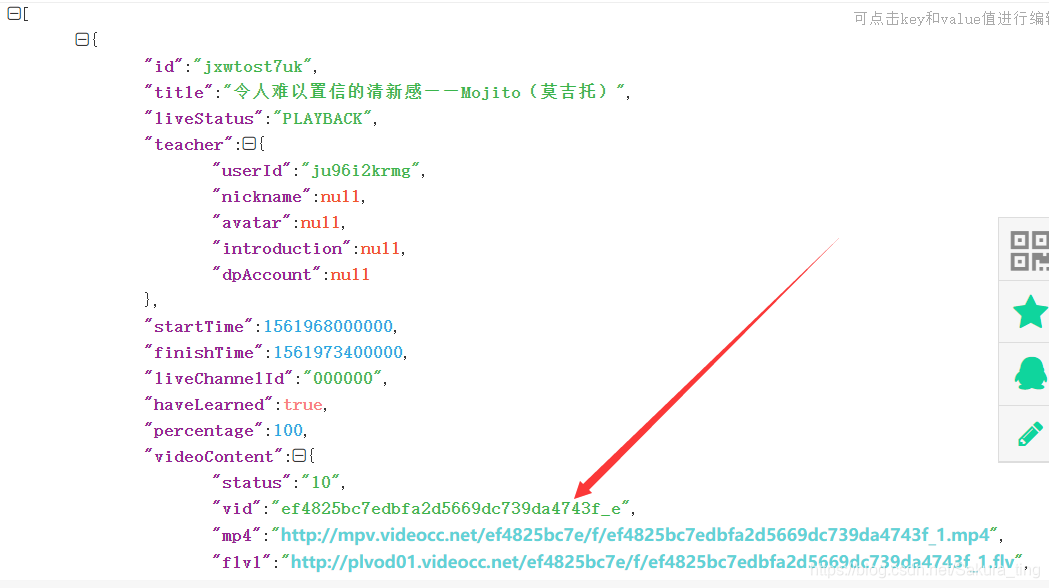
这个的url为: https://www.dapengjiaoyu.cn/dp-course/api/courses/stages/jxptdx8pvb/chapters?courseId=jxpjtxnsow&page=1&size=16
这个里边有课程的名称(title里边),有vid,所以先爬取这个页面,提取title和vid,然后用vid加上https://hls.videocc.net/ef4825bc7e/f/,构造我们的m3u8地址,思路理清楚了,上代码。
三、写代码
我直接上完整的代码了,在代码里边解释,QAQ
import requests
import re
import subprocess #后续会用到,控制终端的库
import os
from tqdm import tqdm #为了好看,加上进度条
from time import sleep
from multiprocessing.dummy import Pool #多线程的
s = '这里是你的cookies,直接复制过来就行'
#处理cookies的方式
cookies = {
}
s = s.encode('utf-8').decode('latin1') #如果cookies有中文,这样处理编码就不会报错了
for k_v in s.split(';'):
k,v = k_v.split('=',1)
cookies 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 148
148

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









