






 文章提出了一种名为UPC-SDG的模型,该模型在用户隐私可控的情况下生成合成数据,以保护推荐系统中的用户隐私。通过注意力机制选择对用户偏好贡献小的item,然后生成合成item以替换这些敏感数据。同时,采用隐私-效用权衡策略来平衡合成数据的隐私和效用。尽管存在疑问,即为何低注意力权重的item被视为敏感,但该模型旨在解决数据隐私、通信成本和用户隐私偏好差异的问题。
文章提出了一种名为UPC-SDG的模型,该模型在用户隐私可控的情况下生成合成数据,以保护推荐系统中的用户隐私。通过注意力机制选择对用户偏好贡献小的item,然后生成合成item以替换这些敏感数据。同时,采用隐私-效用权衡策略来平衡合成数据的隐私和效用。尽管存在疑问,即为何低注意力权重的item被视为敏感,但该模型旨在解决数据隐私、通信成本和用户隐私偏好差异的问题。
推荐系统的隐私保护合成数据生成
《Privacy-Preserving Synthetic Data Generation for Recommendation Systems》是一篇发表在SIGIR 2022上的文章,旨在根据用户不同的隐私需求,针对user-item数据集,利用合成的非敏感item替换原始数据中的敏感item。本人对文中所述方法仍存疑,欢迎一起探讨学习。
作者给出了源代码:https://github.com/HuilinChenJN/UPC_SDG
以下为原文内容:
当用户发送隐私交互数据给组织或者直接向公众发布数据时,存在隐私泄露问题。为此本文提出了一种用户隐私可控合成数据生成模型(UPC-SDG),该模型根据用户的隐私偏好为用户生成合成的交互数据。生成模型旨在提供一定的隐私保障,同时在data层面和item层面最大化生成的合成数据的效用。
具体来说,data层面,设计了一个选择模块,从用户交互数据中选择那些对用户偏好贡献较小的item;
对于Item层面,提出了合成数据生成模块,根据用户偏好生成与所选item对应的合成item。
此外,还提出了一种隐私-效用权衡策略来平衡合成数据的隐私和效用。
现有的解决方案:①针对去中心化提出;②针对模型训练和结果收集阶段的隐私问题而设计。
现有工作的局限性:①通信和成本。去中心化方法中的数据传输和本地计算问题使得难以应用到现实场景;
②数据共享和发布的风险。
③用户对于不同的推荐场景有不同的隐私偏好。例如对用户来说医疗和财务信息比较隐私,而不是杂货的购买记录。
生成合成数据的关键思想:从生成模型创建合成数据,同时尽可能多的保留原始数据的属性。
即使用噪声数据替换掉原始数据中的敏感信息。
基于此本文提出了一种用户隐私可控合成数据生成模型(简称UPCSDG),该模型从原始用户交互数据中生成包含用户隐私偏好的保护隐私的合成数据。
选择模块:采用了一种注意力机制来估计每个已交互item对用户的贡献,挑选出对用户偏好贡献较小的item。
合成item生成模块:考虑用户偏好的同时使用所选item生成有效的合成item。
2. 相关工作:
①协同过滤。基于GCN的推荐模型的优势在于它们能够显式地建模user和item之间的高阶邻近性。
②隐私保护合成数据。对于敏感数据的解决方案通常归为两类,一类为数据匿名化的方法净化数据。
③推荐中的生成模型。
数据噪声作为一种外在问题[13],来源于不同推荐场景下从用户收集的训练数据中产生的随意的、恶意的、无信息的反馈。例如,用户可能会购买与自己兴趣无关的item。以及随机选择的负样本也会在训练过程中误导推荐模型。
为了缓解数据稀疏性问题,已经开发了许多生成模型,通过添加缺失的交互信息来提高推荐系统的性能[5,33,38,42,48]。
模型:
目的:生成用户隐私偏好下的合成交互数据。
本文设置中,每个user和item被分配一个由特征向量表示的唯一ID。
生成合成数据Vu,用来替换一定比例的原始items。合成的交互数据要包含很少或者没有敏感信息。
替换率: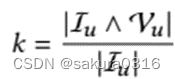
敏感度。敏感度γ用来描述item级别下原始item的隐私保证。通过计算原始数据和合成数据的相对相似度得到。对于原始数据和合成数据
,i和v之间的相关相似度表示为:
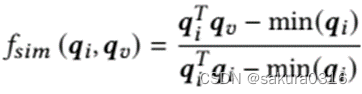
min(.)表示item i和集合I中最不敏感的item之间的余弦相似度。如果合成item满足![]() ,则表示合成item能够满足用户隐私需求。
,则表示合成item能够满足用户隐私需求。
直观上,不同的用户有不同的隐私偏好。因此,k和γ都是可调的(0, 1)之间的超参数来改变模型中合成数据的安全级别,两个参数根据用户的个人隐私偏好进行调节。
Item层面,生成模块根据用户偏好,用户隐私偏好和所选item的特征生成合成item。
合成数据生成
①数据层面。对于用户u,非敏感项替换了原始数据中的敏感项,则保护了用户的隐私。替换的items越多,数据泄露风险越小。选出贡献小的items。
历史交互item对模型用户偏好有不同的贡献[8,19],通过用户u的购买记录,用户偏好可以表示为:
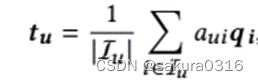
用户u对每个已交互的item都存在一个注意力权重,
是权重集。
通过一个注意力机制求解:
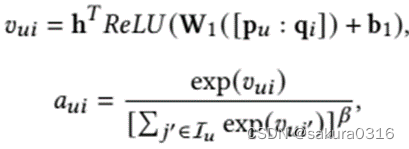
其中是隐藏层的输出映射到输出注意力权重
的向量。β是平滑指数,设置在[0, 1]中的超参数。激活函数ReLU。
由于和
都可以表示用户偏好,使用
作为监督信息学习注意力权重
。具体地,定义损失函数:
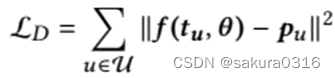
能够学到一个转换函数f(.),将和
映射到同一表征空间中, θ是函数f(.)的参数。 f(.)是一个带剪枝的多层感知器MLP,因为它优越的表示能力并且易于训练。通过训练来估计每个已交互item对用户偏好的贡献度。从而能够得到所有item的注意力权重,将对用户偏好贡献小的item挑选出来作为需要替换的item:
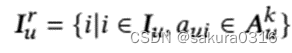
Item层面。得到了,接下来考虑使用哪些item替换
中的items。生成的item也要能吸引用户u的注意力,就是说仍然是用户感兴趣的。换句话说,需要使合成item的效用最大化。
②生成模块。第一步先把各个需要的向量拼起来映射到隐式空间,()
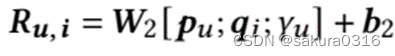
其中,论文中没写,需结合代码食用。
又有表示所有item的embeddings,可以通过以下公式得到隐式特征
和所有item embeddings的相似度:
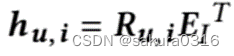
最后我们能够得到所有候选items的概率分布: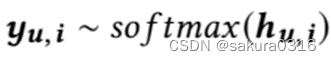
直观的说,应该采样概率最高的item作为所选item的合成item。然而采样的一个关键问题是离散抽样的过程是不可导的。换句话说,生成模型的训练不是端到端的,导致性能较差。最近提出的Gumbel-Softmax[15,23]可以通过应用可微过程近似分类样本。因此,提出Gumbel-Max技巧,将采样算子重新参数化如下:
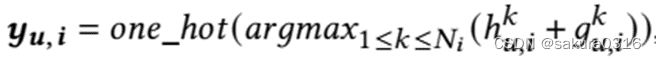
其中,
。
是一个服从是一个服从Gumbel分布的自变量。
。
μ服从(0, 1)之间的均匀分布。然而one_hot和argmax函数仍旧不可导,又有如下变形:
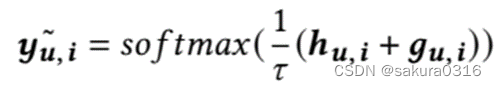
是一个可调的参数来控制soft的程度。
相对于
可导,所以可用来替代
。在获得候选items的得分后,我们使用以上公式对用户u未交互的item进行采样。最后,将生成的item传递给损失函数,以帮助优化生成过程。如果生成的合成item具有与所选item相似的属性,则仍然存在隐私泄露的风险。为了提供隐私保证的同时最大化合成item的效用,提出隐私-效用权衡策略。
我们使用隐私正则化器来约束所选原始item与生成item之间的相对相似性差异。隐私正则化器定义为: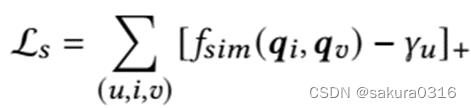
表示标准铰链损失函数。对于用户u来说,原始item i和合成item v之间相似度小于
是可以忍受的。受[20]启发,假如用户更喜欢合成item,则会给该item更高的分数。为了最大化合成item的效用,则希望合成item v也能够吸引用户u的注意。为了实现这个目标,定义了一个程序正则化器生成u和v的交互:
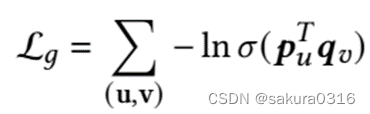
最后的隐私-效用权衡策略为: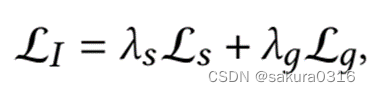
上式中的系数都是超参。生成模型的损失函数可以解释为试图生成用户喜欢的物品的模型。
优化:
最后的目标函数为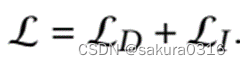
使用mini-batch Adam算法进行优化。
实验。
Q:本人一直对该方法的合理性存疑,为何注意力权重小就是贡献小,文中最开始提到敏感信息如医疗财务等需要被替换,注意力权重小的item就更敏感吗?对于这个疑问,实验后的隐私分析也未给出解答,欢迎共同讨论。

















 309
309

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









