




 本文详细介绍了决策树模型的构建过程,包括特征选择(信息增益、基尼指数、均方误差)、正则化策略(深度限制、叶子节点数、剪枝方法)及其在Python中的实现。通过实例演示了决策树在分类和回归任务中的应用,以及如何防止过拟合。
本文详细介绍了决策树模型的构建过程,包括特征选择(信息增益、基尼指数、均方误差)、正则化策略(深度限制、叶子节点数、剪枝方法)及其在Python中的实现。通过实例演示了决策树在分类和回归任务中的应用,以及如何防止过拟合。
阅读本文需要的背景知识点:一丢丢编程知识
一、引言
在生活中,每次到饭点时都会在心里默念——“等下吃啥?”,可能今天工作的一天了不想走远了,这时我们会决定餐厅的距离不能超过两百米,再看看自己钱包里的二十块钱,决定吃的东西不能超过二十,最后点了份兰州拉面。从上面的例子中可以看到,我们今天吃兰州拉面都是由前面一系列的决策所决定的。
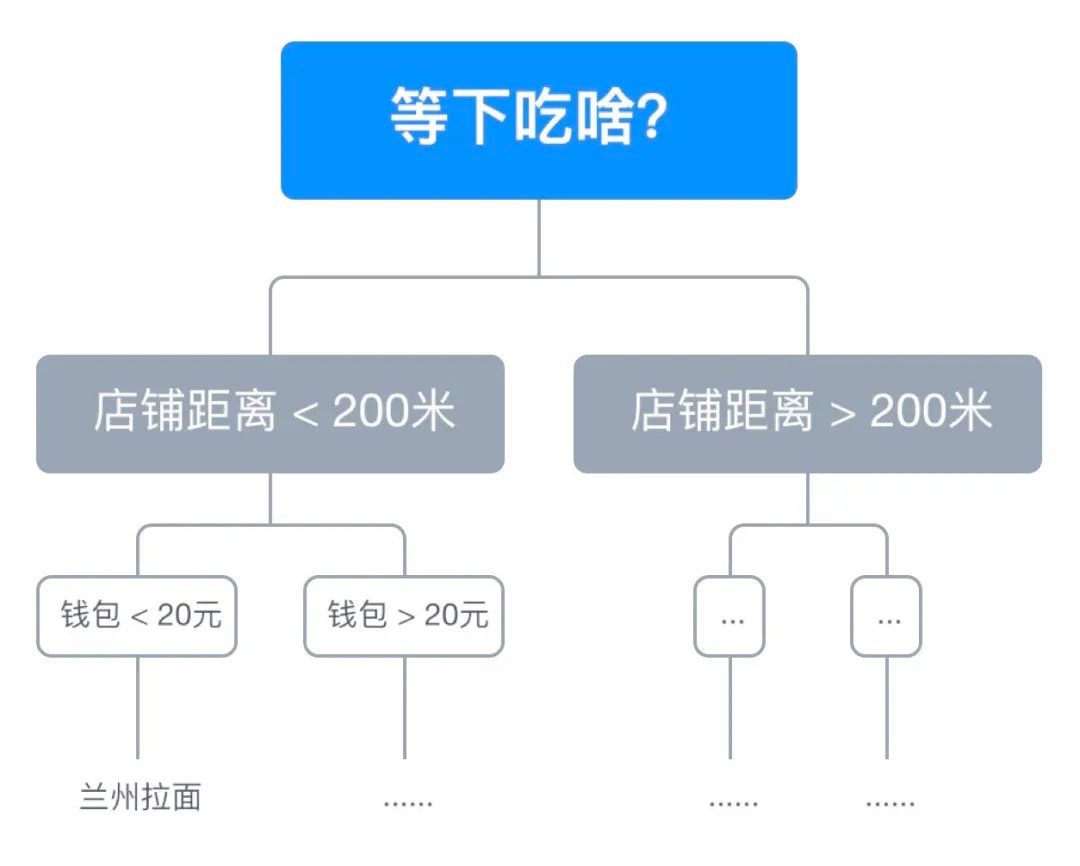
如图1-1 所示,将上面的决策过程用一颗二叉树来表示,这个树就被称为决策树(Decision Tree)。在机器学习中,同样可以通过数据集训练出如图1-1所示的决策树模型,这种算法被称为决策树学习算法(Decision Tree Learning)1 。
二、模型介绍
模型
决策树学习算法(Decision Tree Learning),首先肯定是一个树状结构,由内部结点与叶子结点组成,内部结点表示一个维度(特征),叶子结点表示一个分类。结点与结点之间通过一定的条件相连接,所以决策树又可以看成一堆if…else…规则的集合。
如图2-1 所示,其展示了一颗基本的决策树数据结构与其包含的决策方法。
特征选择
既然要做决策,需要决定的就是从哪个维度(特征)来做决策,例如前面例子中的店铺距离、钱包零钱数等。在机器学习中我们需要一个量化的指标来确定使用的特征更加合适,即使用该特征划分后,得到的子集合的“纯度”更高。这时引入三种指标——信息增益(Information Gain)、基尼指数(Gini Index)、均方误差(MSE)来解决前面说的问题。
信息增益(Information Gain)
式2-1 是一种表示样本集纯度的指标,被称为信息熵(Information Entropy),其中 D 表示样本集, K 表示样本集分类数, p k p_k pk 表示第 k 类样本在样本集所占比例。Ent(D) 的值越小,样本集的纯度越高。
Ent ( D ) = − ∑ k = 1 K p k log 2 p k \operatorname{Ent}(D)=-\sum_{k=1}^{K} p_{k} \log _{2} p_{k} Ent(D)=−k=1∑Kpklog2pk
式2-2 表示用一个离散属性划分后对样本集的影响,被称为信息增益(Information Gain),其中 D 表示样本集,a 表示离散属性,V 表示离散属性 a 所有可能取值的数量, D v D^v Dv 表示样本集中第 v 种取值的子样本集。
Gain ( D , a ) = Ent ( D ) − ∑ v = 1 V ∣ D v ∣ ∣ D ∣ Ent ( D v ) \operatorname{Gain}(D, a)=\operatorname{Ent}(D)-\sum_{v=1}^{V} \frac{\left|D^{v}\right|}{|D|} \operatorname{Ent}\left(D^{v}\right) Gain(D,a)=Ent(D)−v=1∑V∣D∣∣Dv∣Ent(Dv)
当属性是连续属性时,其可取值不像离散属性那样是有限的,这时可以将连续属性在样本集中的值排序后俩俩取平均值作为划分点,改写一下式2-2,得到如式2-3 的结果,其中 T a T_a Ta 表示平均值集合, D t v D_t^v Dtv 表示子集合,当 v = - 时表示样本中小于均值 t 的样本子集,当 v = + 时表示样本中大于均值t的样本子集,取划分点中最大的信息增益作为该属性的信息增益值。
T a = { a i + a i + 1 2 ∣ 1 ≤ i ≤ n − 1 } Gain ( D , a ) = max t ∈ T a Gain ( D , a , t ) = max t ∈ T a Ent ( D ) − ∑ v ∈ { − , + } ∣ D t v ∣ ∣ D ∣ Ent ( D t v ) \begin{aligned} T_{a} &=\left\{\frac{a^{i}+a^{i+1}}{2} \mid 1 \leq i \leq n-1\right\} \\ \operatorname{Gain}(D, a) &=\max _{t \in T_{a}} \operatorname{Gain}(D, a, t) \\ &=\max _{t \in T_{a}} \operatorname{Ent}(D)-\sum_{v \in\{-,+\}} \frac{\left|D_{t}^{v}\right|}{|D|} \operatorname{Ent}\left(D_{t}^{v}\right) \end{aligned} TaGain(D,a)={
2ai+ai+1∣1≤i≤n−1}=t∈TamaxGain(D,a,t)=t∈TamaxEnt(D)−v∈{
−,+}∑∣D∣∣Dtv∣Ent(Dtv)
Gain(D, a) 的值越大,样本集按该属
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+





 到【灌水乐园】发言
到【灌水乐园】发言







