




 本文从概率角度出发,深入解析线性判别分析(LDA)的原理与实现过程,包括正态分布、贝叶斯定理等内容,并给出了Python实现及与sklearn库的对比。
本文从概率角度出发,深入解析线性判别分析(LDA)的原理与实现过程,包括正态分布、贝叶斯定理等内容,并给出了Python实现及与sklearn库的对比。
阅读本文需要的背景知识点:正态分布、线性判别分析、一丢丢编程知识
一、引言
前面一节介绍了基本的线性判别分析算法,最后留下了一个问题,我们在使用 sklearn 得到的结果与上一节中自己实现的结果不同,这一节就来看看 sklearn 中通过概率分布的角度是如何实现线性判别分析的。
二、模型介绍
一元正态分布
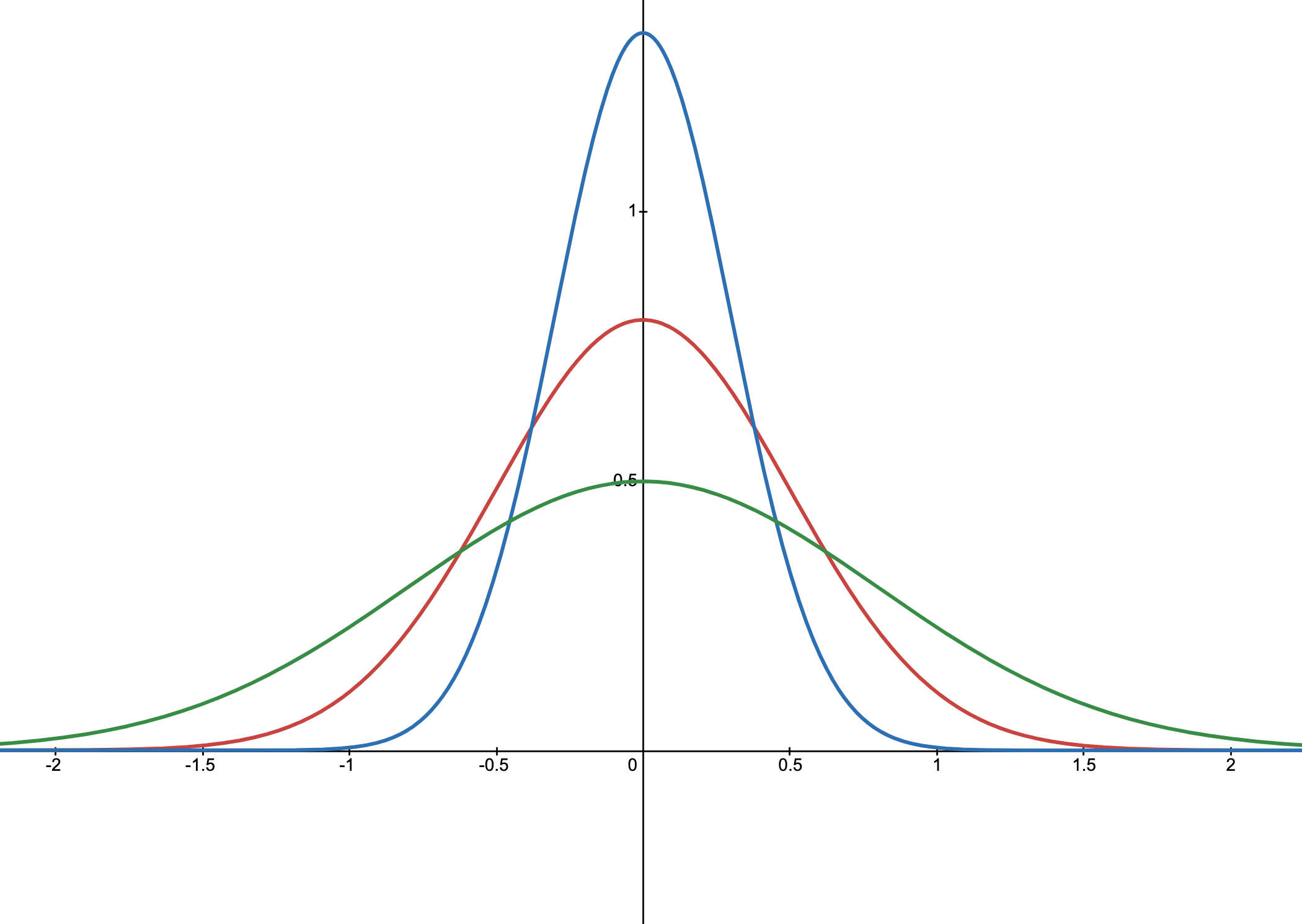
在介绍模型之前先来回顾一下一个在统计学中特别常见的分布——正态分布1(Normal distribution),同时也被称为高斯分布(Gaussian distribution),该分布是下面介绍模型的基础。
f ( x ; μ ; σ ) = 1 σ 2 π exp ( − ( x − μ ) 2 2 σ 2 ) f(x ; \mu ; \sigma)=\frac{1}{\sigma \sqrt{2 \pi}} \exp \left(-\frac{(x-\mu)^{2}}{2 \sigma^{2}}\right) f(x;μ;σ)=σ2π1exp(−2σ2(x−μ)2)
上面为一元正态分布的概率密度函数,其中 x x x 为一元随机变量, μ μ μ 为位置参数, σ σ σ 为尺度参数。
多元正态分布
在机器学习中我们的输入特征一般是多维的,多元正态分布的概率密度函数可以从一元正态分布的概率密度函数得到的。为了简单起见,假设随机变量之间是独立的,即相互之间不存在线性相关性。
(1)随机变量之间相互独立,则联合概率密度函数为每一个随机变量的概率密度函数的乘积,其中 x 为 p p p 维
(2)分别带入各个一元概率密度函数
(3)将 e 的指数用 z 的平方来表示
(4)z 的平方可以写成向量矩阵的形式
(5)观察中间的对角矩阵,用 Σ Σ Σ 来表示该对角矩阵的逆矩阵
(6)则 z 的平方可以简写成该式,x 为特征向量, μ μ μ 为均值向量。该表达式被称为马哈拉诺比斯距离2(Mahalanobis distance),用于表示数据的协方差距离
(7)观察 Σ Σ Σ, Σ Σ Σ 的行列式为对角线上的元素相乘,开根号后为各 σ σ σ 的乘积, ∣ Σ ∣ |Σ| ∣Σ∣ 表示 Σ Σ Σ 的行列式
(8)带入回多元正态分布的概率密度函数中,得到最终的形式
f ( x ) = f ( x 1 ) f ( x 2 ) … f ( x p ) ( 1 ) = 1 σ 1 σ 2 … σ p ( 2 π ) p exp ( − ( x 1 − μ 1 ) 2 2 σ 1 2 − ( x 2 − μ 2 ) 2 2 σ 2 2 − ⋯ − ( x p − μ p ) 2 2 σ p 2 ) ( 2 ) z 2 = ( x 1 − μ 1 ) 2 σ 1 2 + ( x 2 − μ 2 ) 2 σ 2 2 + ⋯ + ( x p − μ p ) 2 σ p 2 ( 3 ) = [ x 1 − μ 1 x 2 − μ 2 ⋯ x p − μ p ] T [ 1 σ 1 2 0 ⋯ 0 0 1 σ 2 2 ⋯ 0 ⋮ ⋮ ⋱ ⋮ 0 0 ⋯ 1 σ p 2 ] [ x 1 − μ 1 x 2 − μ 2 ⋯ x p − μ p ] ( 4 ) Σ = [ σ 1 2 0 ⋯ 0 0 σ 2 2 ⋯ 0 ⋮ ⋮ ⋱ ⋮ 0 0 ⋯ σ p 2 ] ( 5 ) z 2 = ( x − μ ) T Σ − 1 ( x − μ ) ( 6 ) ∣ Σ ∣ 1 2 = σ 1 σ 2 … σ p ( 7 ) f ( x ) = 1 ∣ Σ ∣ 1 2 ( 2 π ) p 2 exp ( − ( x − μ ) T Σ − 1 ( x − μ ) 2 ) ( 8 ) \begin{aligned} f(x) &=f\left(x_{1}\right) f\left(x_{2}\right) \ldots f\left(x_{p}\right) & (1)\\ &=\frac{1}{\sigma_{1} \sigma_{2} \ldots \sigma_{p}(\sqrt{2 \pi})^{p}} \exp \left(-\frac{\left(x_{1}-\mu_{1}\right)^{2}}{2 \sigma_{1}^{2}}-\frac{\left(x_{2}-\mu_{2}\right)^{2}}{2 \sigma_{2}^{2}}-\cdots-\frac{\left(x_{p}-\mu_{p}\right)^{2}}{2 \sigma_{p}^{2}}\right) & (2)\\ z^{2}&=\frac{\left(x_{1}-\mu_{1}\right)^{2}}{\sigma_{1}^{2}}+\frac{\left(x_{2}-\mu_{2}\right)^{2}}{\sigma_{2}^{2}}+\cdots+\frac{\left(x_{p}-\mu_{p}\right)^{2}}{\sigma_{p}^{2}} & (3)\\ &=\left[\begin{array}{c} x_{1}-\mu_{1} \\ x_{2}-\mu_{2} \\ \cdots \\ x_{p}-\mu_{p} \end{array}\right]^{T}\left[\begin{array}{cccc} \frac{1}{\sigma_{1}^{2}} & 0 & \cdots & 0 \\ 0 & \frac{1}{\sigma_{2}^{2}} & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & \frac{1}{\sigma_{p}^{2}} \end{array}\right]\left[\begin{array}{c} x_{1}-\mu_{1} \\ x_{2}-\mu_{2} \\ \cdots \\ x_{p}-\mu_{p} \end{array}\right] & (4)\\ \Sigma&=\left[\begin{array}{cccc} \sigma_{1}^{2} & 0 & \cdots & 0 \\ 0 & \sigma_{2}^{2} & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & \sigma_{p}^{2} \end{array}\right] & (5)\\ z^{2}&=(x-\mu)^{T} \Sigma^{-1}(x-\mu) & (6)\\ |\Sigma|^{\frac{1}{2}} &=\sigma_{1} \sigma_{2} \ldots \sigma_{p} & (7)\\ f(x) &=\frac{1}{|\Sigma|^{\frac{1}{2}}(2 \pi)^{\frac{p}{2}}} \exp \left(-\frac{(x-\mu)^{T} \Sigma^{-1}(x-\mu)}{2}\right) & (8) \end{aligned} f(x)z2Σz2∣Σ∣21f(x)=f(x1)f(x2)…f(xp)=σ1σ2…σp(2π)p1exp(−2σ12(x1−μ1)2−2σ22(x2−μ2)2−⋯−2σp2(xp−μp)2)=σ12(x1−μ1)2+σ22(x2−μ2)2+⋯+σp2(xp−μp)2=⎣⎢⎢⎡x1−μ1x2−μ2⋯
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3077
3077

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









