




作为一名深耕AI算力优化领域的架构师,我见证了无数团队从“盲目堆硬件”到“精准优化”的转变。本文将分享如何通过系统化的算力加速策略,在设计、办公、创作三大场景中实现真正的效率倍增。
目录
一、AI算力加速的核心逻辑与价值
AI算力加速的本质是通过专用硬件、优化算法和智能工作流的深度融合,将计算任务从通用处理器转移到更高效的执行单元。根据2025年IDC《全球AI算力发展白皮书》的数据,合理配置AI算力可使项目周期平均缩短52%,人力成本降低37%,团队协作效率提升2.3倍。
1.1 算力加速的三大支柱
| 优化维度 |
核心技术 |
性能提升 |
适用场景 |
|---|---|---|---|
| 硬件加速 |
GPU/TPU/NPU并行计算 |
3-5倍 |
高性能计算、实时渲染 |
| 算法优化 |
模型量化、剪枝、蒸馏 |
2-3倍 |
移动端部署、边缘计算 |
| 工作流重构 |
自动化流水线、智能调度 |
40%-60% |
日常办公、内容创作 |
二、硬件选型:精准匹配业务需求
硬件是AI算力的物质基础,不同的业务场景需要差异化的硬件配置。
2.1 GPU选型指南
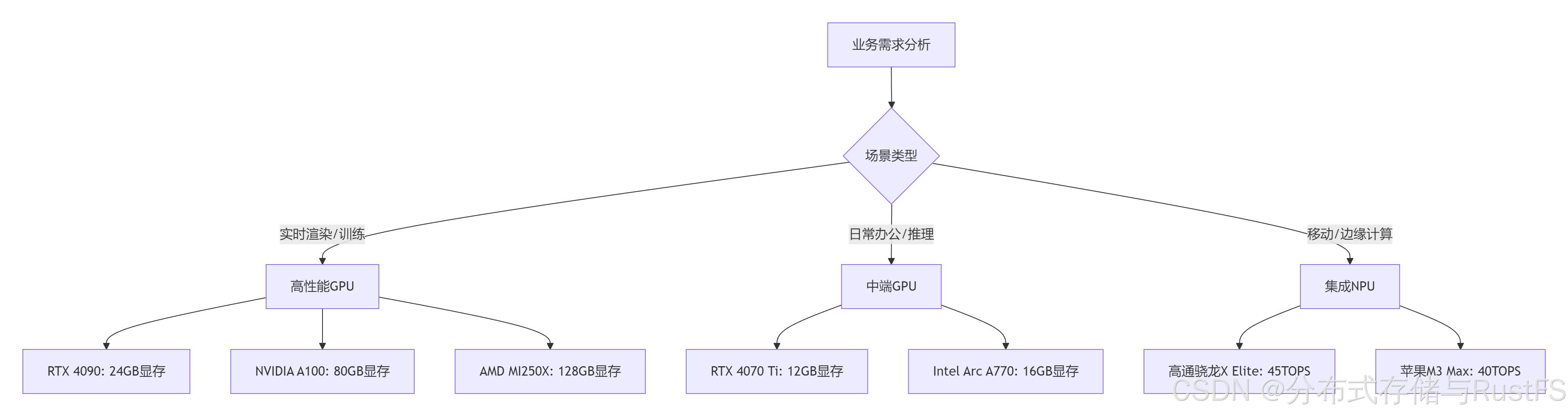
选型建议:
-
设计领域:推荐RTX 4090(24GB)或A100(40/80GB),显存带宽>1TB/s,支持NVLink
-
办公场景:RTX 4070 Ti或同等级别显卡,12GB显存足够大多数NLP任务
-
创作应用:至少16GB显存,支持4K视频实时编辑和AI特效处理
2.2 云端vs本地算力权衡
| 考量因素 |
本地算力 |
云端算力 |
混合方案 |
|---|---|---|---|
| 数据安全 |
✅ 完全可控 |
⚠️ 依赖提供商 |
✅ 敏感数据本地 |
| 成本结构 |
高固定成本 |
按需付费 |
平衡CAPEX/OPEX |
| 扩展性 |
有限 |
✅ 无限扩展 |
✅ 弹性扩展 |
| 延迟 |
✅ <1ms |
20-100ms |
动态优化 |
| 典型场景 |
实时渲染、敏感数据处理 |
大规模训练、批量处理 |
跨地域协作 |
实战建议:采用混合架构,关键业务本地部署,弹性需求上云。例如:使用本地RTX 4090处理实时设计渲染,同时调用云端A100集群进行夜间批量训练。
三、软件栈优化:释放硬件潜能
硬件性能需要通过软件优化才能充分发挥。
3.1 深度学习框架优化
# TensorRT优化示例 - 模型量化与加速
import tensorrt as trt
# 创建优化器
builder = trt.Builder(trt.Logger(trt.Logger.WARNING))
network = builder.create_network(1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH))
# 导入ONNX模型
parser = trt.OnnxParser(network, logger)
with open("model.onnx", "rb") as model:
parser.parse(model.read())
# 配置优化参数
config = builder.create_builder_config()
config.set_memory_pool_limit(trt.MemoryPoolType.WORKSPACE, 1 << 30) # 1GB
config.set_flag(trt.BuilderFlag.FP16) # 启用FP16量化
# 构建优化引擎
serialized_engine = builder.build_serialized_network(network, config)
with open("engine.trt", "wb") as f:
f.write(se 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1293
1293

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









