 恶意攻击传播建模核心
恶意攻击传播建模核心




第2章 恶意攻击传播建模初步
2.1 图论
图通常用于表示计算机科学、生物学和社会学等不同领域的网络。一个图 G=(V, E)由一组节点V(表示对象)和一组边E={eij|i, j ∈ V}(表示关系)组成。例如,在计算机网络中,一个节点代表一台计算机或服务器,一条边代表两台计算机或服务器之间的连接;在社交网络中,一个节点代表一个人,一条边代表两人之间的友谊。从数学上讲,图也可以表示为邻接矩阵 A,其中每个元素aij标记边eij上的权重。
为了捕捉网络中节点的重要性,多年来提出了许多不同的中心性度量方法[98]。根据弗里曼在1979年[66]的说法:“关于中心性的确切定义及其概念基础,目前肯定没有一致意见,对于如何正确测量中心性也几乎没有共识。” 在本章中,我们介绍一些常用的中心性度量方法如下。
度
给定一个节点 i,节点 i 的度是与该节点相连的边的数量。在图2.1a中,黑色节点的度值高于白色节点。高度中心性表明该节点在网络中具有较高的影响力。例如,计算机网络中的高度节点通常充当枢纽或作为网络中数据传输的主要通道。同时,度衡量了节点的局部影响力,因为该值是通过考虑该节点与其直接相邻节点之间的连接数量来计算的。节点 D(i) 的度 Di 可按如下方式计算:
$$
D(i)= \sum_{j=1}^{n} e_{ij}, \quad (2.1)
$$
其中n是网络中节点的总数,$ e_{ij} = 1 $ 当且仅当i和j通过一条边相连;否则 $ e_{ij} = 0 $。
介数
一个节点的介数量化了该节点在另外两个节点之间的最短路径上作为桥梁的次数[65]。具有高介数的节点促进了信息流动,因为它们在其他节点或节点组之间构成了关键的桥梁(见图2.1b)。精确地说,假设 $ g^{(st)} i $ 是从节点s到节点t且经过节点i的最短路径数量,而 $ n {st} $ 是从s到t的最短路径总数。那么节点i的介数定义如下:
$$
B(i)= \frac{\sum_{s<t} g^{(st)} i / n {st}}{\frac{1}{2} n(n -1)}. \quad (2.2)
$$
研究人员发现,一些度不大的节点在信息扩散中也起着至关重要的作用 [72, 110]。如图2.1b所示,节点E的度小于节点A、B、C和D。然而,节点E在信息传播中明显更为重要,因为它是两个大群体之间的连接者。通过使用介数中心性,我们可以成功定位这些节点。
接近度
一个节点的接近度[65, 136]定义为该节点与所有其他可达节点之间最短路径长度的平均值。数学上,节点i的接近度中心性C可按如下方式计算[66]:
$$
C(i)= \frac{n -1}{\sum_{j=1}^{n} d(i, j)}, \quad (2.3)
$$
其中 $ d(i, j) $ 表示从节点 i 到节点 j 的最短路径的距离。[136]一个节点的接近度可被视为衡量信息从该节点依次传播到所有其他节点所需时间的指标。一个节点越中心,其到所有其他节点的总距离越小,因此接近度越大。如图2.1c 所示,节点A和B是距离所有其他节点最近的节点。

图2.1 一些中心性度量的示意图。(a) 度。(b) 介数。(c) 接近度
特征向量中心性
一个节点的特征向量中心性[21, 133]是基于无向图G的邻接矩阵A的主特征向量定义的。设x为邻接矩阵A最大特征值 λ对应的特征向量。节点i的特征向量中心性定义为主特征向量x中的第i个元素xi。等价地,一个节点的特征向量中心性与其所有邻居节点的特征向量中心性的总和成比例。数学上,给定一个节点i及其邻居节点集合Ni,节点i的特征向量中心性等于其所有邻居节点的特征向量中心性之和:
$$
x_i = \sum_{j \in N_i} x_j = \sum_{j \in V} A_{ij}x_j. \quad (2.4)
$$
因此,i的特征向量中心性既取决于其邻居的数量 $ |N_i| $,也取决于其连接的质量 $ x_j, j \in N_i $。在现实世界中,一个具有影响力节点的特点是它与其他有影响力的节点相连。因此,具有高特征向量中心性的节点是一个连接良好的节点,并对周围网络具有主导性影响力。
聚类系数
在图论中,聚类系数是衡量图中节点聚集程度的指标 [79, 179]。该指标有两种形式:全局和局部。全局聚类系数旨在提供网络中整体聚类情况的指示,而局部聚类系数则反映单个节点的嵌入程度。全局和局部聚类系数均定义于无向图中。三元组由三个节点组成,其间有两条(开放三元组)或三条(闭合三元组)无向边。全局聚类系数定义为图中闭合三元组占所有三元组的比例 [113]。
$$
C_G = \frac{|{ e_{ij}, e_{jk}, e_{ik} \in E }|}{|{ e_{ij}, e_{jk} \in E }|}. \quad (2.5)
$$
三角形是指三个节点之间通过三条无向边相互连接的集合。节点i的局部聚类系数定义为:在节点i的邻域中,所有包含节点i的节点三元组中,构成三角形的分数。
$$
C(i)= \frac{|{ e_{jk} | j, k \in N_i, e_{jk} \in E }|}{k_i(k_i -1)}, \quad (2.6)
$$
其中 $ N_i = { j | e_{ij} \in E $ 或 $ e_{ji} \in E } $ 是节点i的邻居集合。局部聚类系数用于衡量一个节点的邻居节点之间形成团[179]的紧密程度。
在现实世界中,恶意攻击通常从底层网络的影响节点开始,以便快速感染大量主机。在本书的后续章节中,我们将分析不同中心性节点在传播中的特征恶意攻击,并分析如何通过阻断关键节点来抑制恶意攻击。对于其他中心性度量,读者可参考[21]以了解详细信息。
2.2 网络拓扑
恶意攻击传播所依赖的底层网络是一个复杂系统。理解该系统的拓扑结构对于遏制恶意攻击的传播至关重要。随着移动设备和物联网(IoT)的发展,网络系统通过网络用户或资产之间的动态交互不断变化。研究此类系统的一种常用方法是利用复杂网络理论的工具来分析网络动力学以及在此动力学过程中涌现出的拓扑特性。为了捕捉这些特性,研究人员已开发出多种致力于复现网络拓扑动态演化过程的模型,例如基于优先连接、节点异质性和三元闭包的模型。接下来,我们将介绍一些流行的网络生成模型。
埃尔德什‐雷尼随机网络
第一个网络生成模型由埃尔德什和雷尼在 1959[53] 提出。该模型描述了一个随机网络的增长过程:从所有n个节点间可能的 m条边中,以相等的概率p随机选择边进行连接,共有 $ n(n -1)/2 $ 种可能的边。在埃尔德什-雷尼(ER)网络中,节点度呈现泊松分布。另一个关键特征是随着p的增加,网络连通性会发生突变:当p较小时,存在许多小且孤立的簇;但一旦p增大到超过一个临界值,网络会突然变得非常密集,几乎所有节点都通过一个巨型连通分量相互连接。这一特征的示意图见图2.2。

图2.2 ER随机网络 [53, 131]中排除巨型组件(如果存在)的平均组件大小(黑色实线)和巨型组件大小(红色虚线)的曲线图
小世界网络
小世界网络起源于米尔格拉姆的实验[125],在该实验中,选定的人被要求仅通过将信件传递给他们的熟人,将其送达目标接收者。在所有成功传递的案例中,这些通信链的平均长度很短,大约为6步。这一现象被称为“小世界效应”或“六度分隔”。小世界网络具有基于熟人关系的边,且任意两人之间的距离比预期要短。在现实世界中,小世界效应意味着一个人的大多数朋友都住在附近,但他也可能有少数朋友居住在较远的地方。
人们不断移动,但地理距离限制了社会关系的强度。瓦茨-斯特罗加茨模型通过以概率 p[179]重连规则网络中的每条连接来再现小世界现象。如图 2.3所示,当 p= 0时,网络完全有序;当 p= 1时,每条边都被重连,从而形成一个随机网络;当 0< p< 1时,我们得到一个具有较小平均最短路径和较高聚类系数的小世界网络[179]。
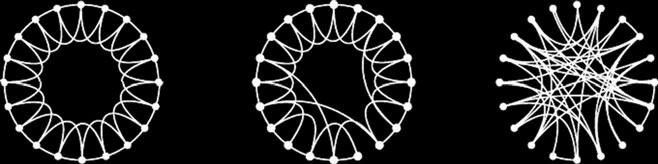
图2.3 瓦茨‐斯特罗加茨模型通过根据随机参数p[179]重连规则网络中的边来复现小世界现象
2.3 社区结构
一个社区是图中高度连接的节点组成的群体。社区结构被认为是多种复杂网络的一个关键特性,表明网络可以划分为多个簇,使得同一簇内的节点内部连接紧密,而与外部节点连接稀疏;这种聚类可能源于人们的共同兴趣、电网的地理划分或蛋白质的功能相似性[72, 134]。已有许多社区检测方法被提出,包括寻找分离/非重叠社区(见图2.5a)和检测重叠社区(见图2.5b)。接下来,我们介绍两种流行的方法:Infomap [153]和链接聚类 [3]。关于其他社区检测方法,读者可参考[59]。
Infomap
Infomap算法旨在寻找非重叠社区。该方法基于以下假设:随机游走者更可能被困在社区内部,而非在社区之间移动。随机游走者的路径可以被编码,并通过分层网络划分进行压缩,从而使编码描述最短。在网络中发现社区结构与编码问题之间的对偶性在于:为了找到一种高效的编码方式,需要将包含n个节点的网络划分为m个模块的划分M。
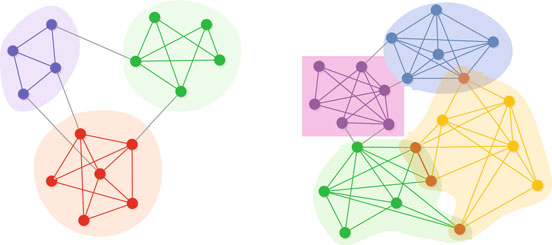
图2.5 网络社区示意图。(a)非重叠社区。(b)重叠社区
模块,以最小化随机游走的期望描述长度。通过使用模块划分M,单步的平均描述长度由下式给出
$$
L(M)= q^\curvearrowright H(\mathcal{L}) + \sum_{i=1}^{m} p_i^\circlearrowleft H(\mathcal{P}_i), \quad (2.7)
$$
其中,$ H(\mathcal{L}) $ 是模块名称在 M 中的熵;$ H(\mathcal{P}_i) $ 是模块内移动的熵;$ q^\curvearrowright $ 表示随机游走在某一步切换模块的概率;$ p_i^\circlearrowleft $ 是模块 i 内部模块内移动概率与离开 i 的概率之和。该公式的第一部分描述了社区之间移动的熵,第二部分则汇总了每个社区内部的熵。最终,Infomap 应用计算搜索算法以找到最优划分为结果 [153]。
链接聚类
与Infomap不同,链接聚类算法旨在发现重叠社区,其中允许一个节点属于多个社区。该算法将社区重新定义为链路的集合而非节点的集合。节点 i 的邻居集合表示为 Ni。对于具有一个共享节点的一对链路,eij 和 ejk,这两条链路之间的相似度是两个不同端点的邻居集合之间的杰卡德相似系数:
$$
S(e_{ij}, e_{jk}) = \frac{|N_i \cap N_k|}{|N_i \cup N_k|}. \quad (2.8)
$$
然后根据这些相似性使用单连接层次聚类构建树状图,并在某一层次切割树状图以产生重叠的社区结构。给定一个划分 $ P = {P_1, P_2, …, P_C} $,可以通过每个划分中现有链接的比例加权的平均划分密度来计算划分密度D:
$$
D = \sum_c \frac{m_c}{M} D_c = \frac{2}{M} \sum_c \frac{m_c}{m_c - (n_c - 1)} \cdot (n_c - 2)(n_c - 1), \quad (2.9)
$$
其中 $ m_c $ 和 $ n_c $ 分别是划分 Pc 中的边和节点的数量。树状图中的切割阈值可以通过实现最大划分密度来确定。
2.4 信息传播模型
早期关于通信动态的模型受到疾病传播研究的启发[10, 12, 39, 73, 149]。类似于传染病在人群中的传播方式,信息可以通过社交关系从一个人传递给另一个人,“感染”个体随后可将信息进一步传播给其他人,有可能引发大规模传染。易感‐感染(SI)[93, 94]、易感‐感染‐恢复(SIR)[10]、和易感‐感染‐易感(SIS)[12]模型是流行病学中的三种经典模型,其中感染人群呈指数增长,直到感染率与恢复率达到平衡,或者当恢复率占主导时,传染最终消退。作为该领域的另一基础,不同模型对应于寻找传播源的不同场景。目前,研究人员主要采用这三种传染病模型来建模恶意攻击的传播过程:
易感‐感染(SI)模型
在此模型中,节点最初处于易感状态,并可随着信息传播而被感染(图2.6a)。一旦节点被感染,将始终保持感染状态。该模型仅关注感染过程 $ S \rightarrow I $,而不考虑恢复过程。假设 β为节点通过接触而被感染的感染可能性率,则从时间t到t+Δt的平均新增感染数可计算为
$$
\Delta I = \beta \cdot I(t) \cdot S(t). \quad (2.10)
$$
根据假设,我们有 $ S(t) = n - I(t) $。因此,我们可以将SI模型重写如下
$$
\frac{dI(t)}{dt} = \beta I(t)(n - I(t)). \quad (2.11)
$$
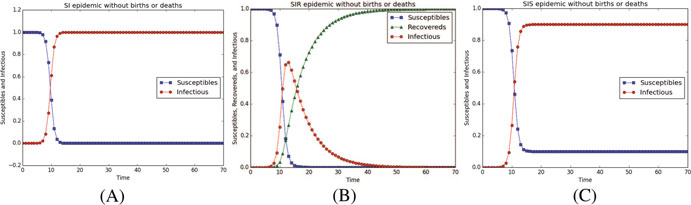
图2.6 疾病传播模型示意图。(a) SI模型;(b) SIR模型;(c) SIS模型
易感‐感染‐恢复(SIR)模型
该模型考虑了恢复过程(图2.6b)。类似地,节点最初处于易感状态,并随着传播而被感染。感染的节点随后可以恢复,且永远不会再次变为易感状态。该模型描述了感染和治愈过程 $ S \rightarrow I \rightarrow R $。假设 γ是从感染状态转换到恢复状态的转换率,则SIR模型可用以下公式表示:
$$
\frac{dS(t)}{dt} = -\beta \frac{I(t)S(t)}{n}, \quad (2.12)
$$
$$
\frac{dI(t)}{dt} = \beta \frac{I(t)S(t)}{n} - \gamma I(t), \quad (2.13)
$$
$$
\frac{dR(t)}{dt} = \gamma I(t). \quad (2.14)
$$
易感‐感染‐易感(SIS)模型
在此模型中,感染节点在治愈后可再次变为易感节点(图2.6c)。该模型表示感染与恢复过程 $ S \rightarrow I \rightarrow S $。假设 γ为感染状态向易感状态的转换率,则SIS模型可用以下公式表示:
$$
\frac{dS(t)}{dt} = -\beta \frac{I(t)S(t)}{n} + \gamma I(t), \quad (2.15)
$$
$$
\frac{dI(t)}{dt} = \beta \frac{I(t)S(t)}{n} - \gamma I(t). \quad (2.16)
$$
基于SI、SIR和SIS模型的感染节点数量和易感节点数量随 t 的变化如图2.7a、b和c所示。还有许多其他传染病模型,例如SIRS [166], SEIR [196], MSIR[78], SEIRS[36]。读者可参考 [190]和 [176]的工作以了解更多传染病模型。
图2.7 基于不同模型的传播过程。(a)SI模型。(b)SIR模型。(c)SIS模型

















 564
564

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









