







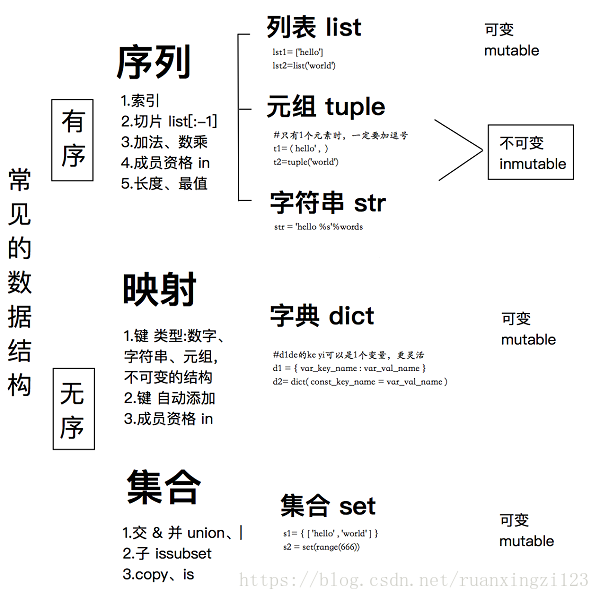
一:python内部数据类型分类
这里有个很重要的东西要先提醒注意一下:原子性数据类型和非原子性数据类型的区别
Python内部数据从某种形式上可以分为两种:
其一是原子性数据类型:int,float,str
其余的是非原子性的(按有序性分):
有序的:list, tuple
无序的:set, dict
那么什么是原子性呢,在第一篇讲赋值语句时有个例子:
赋值语句:x = 6
其实这个过程是建立了一个指向(reference),左边的是指向,右边的是一个对象(object)或者一个有指向对象的指向,可以有多个指向指向同一个对象(object),[注意此地对象的意思,可以是值,实例,函数等等], 综上,此地时建立了一个叫x的变量(variable)让其拥有object 6的reference
注意:
>>> a=[1,2,3,4] >>> a=1
>>> b=a >>> b=a
>>> a[0]=None >>> a=2
>>> b >>> b
[None, 2, 3, 4] 1
这里就出现了一个很奇怪的现象了,左边的b跟着a变而右边的没有,其实这就是因为int为原子性数据结构带来的。可以认为原子性数据所在内存地址是固定的,这样改变了a变量的值就是改变了a变量指向的地址。而非原子性改变a就是改变了a所指内存地址所存储的东西而没有改变a指向的地址。这样就能够解释通了。
另一个有趣的例子:
>>>my_list = [1,2,3]
>>>A = [my_list]*3
>>>A
[1,2,3,1,2,3,1,2,3]
变量A是三个my_list的reference的集合,my_list某个元素的改变都会折射到其上
1.数字——》int 类型
Python的数字类型有int整型、long长整型、float浮点数、complex复数、以及布尔值(0和1),这里只针对int整型进行介绍学习。在Python2中,整数的大小是有限制的,即当数字超过一定的范围不再是int类型,而是long长整型,而在Python3中,无论整数的大小长度为多少,统称为整型int。
其主要方法有以下两种:
1)int -->将字符串数据类型转为int类型, 注:字符串内的内容必须是数字
代码:
s = '2345'
i = int( s )
print( i)
结果:2345
2)bit_length() -->将数字转换为二进制,并且返回最少位二进制的位数
代码:
a =12345
v= a.bit_length()
print(v)
结果:14
2.布尔值-----》bool类
对于布尔值,只有两种结果即True和False,其分别对应与二进制中的0和1。而对于真即True的值太多了,我们只需要了解假即Flase的值有哪些---》None、空(即 [ ]/( ) /" "/{ })、0;
>>> bool(None)
False
>>> bool('')
False
>>> bool([])
False
>>> bool(0)
False
>>> bool(())
False
>>> bool({})
False
3.字符串-----》str类
关于字符串是Python中最常用的数据类型,其用途也很多,我们可以使用单引号 ‘’或者双引号“”来创建字符串。字符串是不可修改的。所有关于字符我们可以从 索引、切片、长度、遍历、删除、分割、清除空白、大小写转换、判断以什么开头等方面对字符串进行介绍。
1)创建字符串
代码:
name ='little_five'
print(name)
结果:little_five
2)切片
获取切片,复数代表倒数第几个,从0开始
代码:
name ="little-five"
print(name[1])
#从第一个到倒数第二个,不包含倒数第二个
print(name[0:-2] )
结果:
i
'little-fi'
3)索引--> index()、find()
index()与find()的不同之处在于:若索引的该字符或者序列不在字符串内,对于index--》ValueError: substring not found,而对于find -->返回 -1。
代码:
name = "little_five"
#index-->获取索引,第二个参数指定获取该子字符或者子序列的第几个
print(name.index("l",2))
#结果为 4
#find -->其作用与index相似
print(name.find("l",2)) #
结果也为 4
4) 长度 -->len()
len()方法-->同样可以用于其他数据类型,例如查看列表、元组以及字典中元素的多少。
代码:
s = "123456"
print(len(s))
结果:6
5)删除 --> del
#删除字符串,也是删除变量
>>> name ="little-five"
>>> del name
>>> name
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'name' is not defined
6)判断字符串内容 --> isalnum()、isalpha()、isdigit()
#判断是否全为数字
>>> a ="123"
>>> a.isdigit()
True
>>> b ="a123"
>>> b.isdigit()
False
#判断是否全为字母
>>> d ="alx--e"
>>> d.isalpha()
False
>>> c ="alex"
>>> c.isalpha()
True
#判断是否全为数字或者字母
>>> e ="abc123"
>>> e.isalnum()
True
7)大小写转换 --> capitalize()、lower()、upper()、title()、casefold()
#大小写的互相转换
>>> name ="little_five"
#首字母大写-->capitalize
>>> name.capitalize()
'Little_five'
#转为标题-->title
>>> info ="my name is little_five"
>>> info.title()
'My Name Is Little_Five'
#全部转为小写-->lower
>>> name ="LITTLE_FIVE"
>>> name.lower()
'little_five'
#全部转为大写-->upper
>>> name = "little_five"
>>> name.upper()
'LITTLE_FIVE'
#大小写转换-->swapcase
>>> name ="lIttle_fIve"
>>> name.swapcase()
'LiTTLE_FiVE'
# 特殊字符(很多未知的对象)以及字母转换为小写casefold()
>>> name ="lItLE_fIve"
>>> name.casefold()
'litle_five'
8) 判断以什么开头结尾 --> startswith()、endswith()
#判断以什么开头、结尾
>>> name ="little-five"
#判断以什么结尾
>>> name.endswith("e")
True
#判断以什么开头
>>> name.startswith("li")
True
9)扩展-->expandtabs()
#expandtabs -->返回字符串中的 tab 符号('\t')转为空格后生成的新字符串。通常可用于表格格式的输出
info ="name\tage\temail\nlittlefive\t22\t994263539@qq.com\njames\t33\t66622334@qq.com"
print(info.expandtabs(20)) #extendtabs,断句20
#输出为:
name age email
littlefive 22 994263539@qq.com
james 33 66622334@qq.com
10) 格式化输出-->format()、format_map()
#格式化输出-->format、format_map
#forma方法
#方式一
>>> info ="my name is {name},I'am {age} years old."
>>> info.format(name="little-five",age=22)
"my name is little-five,I'am 22 years old."
#方式二
>>> info ="my name is {0},I'am {1} years old."
>>> info.format("little-five",22)
"my name is little-five,I'am 22 years old."
#方式三
>>> info ="my name is {name},I'am {age} years old."
>>> info.format(**{"name":"little-five","age":22})
"my name is little-five,I'am 22 years old."
#format_map方法
>>> info ="my name is {name},I'am {age} years old."
>>> info.format_map({"name":"little-five","age":22})
"my name is little-five,I'am 22 years old."
11) jion方法
#join--> join(): 连接字符串数组。将字符串、元组、列表中的元素以指定的字符(分隔符)连接生成一个新的字符串
#字符串
>>> name ="littefive"
>>> "-".join(name)
'l-i-t-t-e-f-i-v-e'
#列表
>>> info = ["xiaowu","say","hello","world"]
>>> "--".join(info)
'xiaowu--say--hello--world'
12) 分割 --> split()、partition()
#分割,有两个方法-partition、split
#partition -->只能将字符串分为三个部分,生成列表
>>> name ="little-five"
>>> name.partition("-")
('little', '-', 'five')
#split-->分割字符串,并且可以指定分割几次,并且返回列表
>>> name ="little-five-hello-world"
>>> name.split("-")
['little', 'five', 'hello', 'world']
>>> name.split("-",2) #指定分割几次
['little', 'five', 'hello-world']
>>>
13) 替代 -->replace
#替代
>>> name ="little-five"
>>> name.replace("l","L")
'LittLe-five'
#也可以指定参数,替换几个
>>> name.replace("i","e",2)
'lettle-feve'
14)清除空白 --> strip()、lstrip()、rstrip()
#去除空格
>>> name =" little-five "
#去除字符串左右两边的空格
>>> name.strip()
'little-five'
#去除字符串左边的空格
>>> name.lstrip()
'little-five '
#去除字符串右边的空格
>>> name.rstrip()
' little-five'
14) 替换 -->makestran 、translate
#进行一一替换4、列表 --->list类
>>> a ="wszgr"
>>> b="我是中国人"
>>> v =str.maketrans(a,b) #创建对应关系,并且两个字符串长度要求一致
>>> info ="I'm a Chinese people,wszgr"
>>> info.translate(v)
"I'm a Chine是e people,我是中国人"、
15)计算个数---》count()
name="abcdafghath:
name.count("a")
结果为:3
v= name.count("a",0,5) # name从0开始带5之间有多少a
结果为:2
4、列表 --->list类
列表是由一系列特定元素顺序排列的元素组成的,它的元素可以是任何数据类型即数字、字符串、列表、元组、字典、布尔值等等,同时其元素也是可修改的。其形式为:
names = ['little-five","James","Alex"]
#或者
names = list(['little-five","James","Alex"])
1)索引、切片
#索引-->从0开始,而不是从一开始
name =["xiaowu","little-five","James"]
print(name[0:-1])
结果:['xiaowu', 'little-five']
#切片-->负数为倒数第几个,其为左闭右开,如不写,前面表示包含前面所有元素,后面则表示后面所有元素
m1 =name[1:]
print(m1)
结果:['little-five', 'James']
m2 =name[:-1]
print(m2)
结果:['xiaowu', 'little-five']
# 根据值获取当前值索引位置(左边优先)
li = [11,22,33,22,44]
v = li.index(22)
print(v)
结果:1
# 在指定索引位置插入元素
li = [11, 22, 33, 22, 44]
li.insert(0,99)
print(li)
结果:[99, 11, 22, 33, 22, 44]
2) 追加-->append()
#追加元素-->append()
name =["xiaowu","little-five","James"]
name.append("alex")
print(name)
结果:['xiaowu', 'little-five', 'James', 'alex']
3)拓展-->extend()
扩展extend与追加append的区别:
extend与append方法的相似之处在于都是将新接收到参数放置到已有列表的后面。而extend方法只能接收list,且把这个list中的每个元素添加到原list中。
而append方法可以接收任意数据类型的参数,并且简单地追加到list尾部。
#extend-->扩展
name =["xiaowu","little-five","James"]
name.extend(["hello","world"])
print(name)输出为-->['xiaowu', 'little-five', 'James', 'hello', 'world']
#append -->追加
name.append(["hello","world"])
print(name) 输出为 -->['xiaowu', 'little-five', 'James', ['hello', 'world']]
#扩展--》其将字符串或者列表的元素添加到列表内
一、将其他列表元素添加至列表内
name =["xiaowu","little-five","James"]
name.extend(["alex","green"])
print(name) #输出为-->['xiaowu', 'little-five', 'James', 'alex', 'green']
二、将字符串元素添加到列表内
name =["xiaowu","little-five","James"]
name.extend("hello")
print(name)
#输出为-->xiaowu', 'little-five',"James", 'h', 'e', 'l', 'l', 'o']
三、将字典元素添加至列表内,注:字典的key。
name =["xiaowu","little-five","James"]
name.extend({"hello":"world"})
print(name) #--->['xiaowu', 'little-five', 'James', 'hello']
4)insert() -->插入
#insert()插入-->可以指定插入列表的某个位置,前面提到过列表是有序的
name =["xiaowu","little-five","James"]
name.insert(1,"alex") #索引从0开始,即第二个
print(name)---->['xiaowu', 'alex', 'little-five', 'James']
5)pop() -->取出
#pop()--取出,可将取出的值作为字符串赋予另外一个变量
name =["xiaowu","little-five","James"]
special_name =name.pop(1)
print(name) #输出为:['xiaowu', 'James']
print(special_name,type(special_name)) #输出为:['xiaowu', 'James'] little-five <class 'str'>
6) remove()-->移除、del -->删除
#remove -->移除,其参数为列表的值的名称
name =["xiaowu","little-five","James"]
name.remove("xiaowu")
print(name) #其输出为:['little-five', 'James']
#del -->删除
name =["xiaowu","little-five","James"]
name.remove("xiaowu")
del name[1]
print(name)#其输出为:['little-five']
7)sorted()-->排序,默认正序,加入reverse =True,则表示倒序
#正序
num =[11,55,88,66,35,42]
print(sorted(num)) -->数字排序 #输出为:[11, 35, 42, 55, 66, 88]
name =["xiaowu","little-five","James"]
print(sorted(name)) -->字符串排序 #输出为:['James', 'little-five', 'xiaowu']
#倒序
num =[11,55,88,66,35,42]
print(sorted(num,reverse=True)) #输出为:[88, 66, 55, 42, 35, 11]
8)拷贝,浅拷贝
代码:
li = [11, 22, 33, 22, 44]
v = li.copy()
print(v)
结果:[11, 22, 33, 22, 44]
5、元组 --->tuple类
为什么要引入元组?
元组和序列是相对的,元组是不可变的序列,一旦创建无法修改里面的值。
元祖的使用:
-
创建形式1:用(.)。注意,最后要加多一个.
-
创建形式2:tuple()
-
元组操作比较简单,记住其是不可变的
元组即为不可修改的列表。其于特性跟list相似。其使用圆括号而不是方括号来标识。
创建和访问一个元组
如果创建一个空元组,直接使用小括号即可;
如果要创建的元组中只有一个元素,要在它的后面加上一个逗号‘,’。
#元组
name = ("little-five","xiaowu")
print(name[0])
6、字典 --->dict类
字典为一系列的键-值对,每个键值对用逗号隔开,每个键都与一个值相对应,可以通过使用键来访问对应的值。无序的。键的定义必须是不可变的,即可以是数字、字符串也可以是元组,还有布尔值等。而值的定义可以是任意数据类型。
#字典的定义
info ={
1:"hello world", #键为数字
("hello world"):1, #键为元组
False:{
"name":"James"
},
"age":22
}
1) 遍历 -->items、keys、values
info ={
"name":"little-five",
"age":22,
"email":"99426353*@qq,com"
}
#键
for key in info:
print(key)
print(info.keys())
#输出为:dict_keys(['name', 'age', 'email'])
#键值对
print(info.items())
#输出为-->dict_items([('name', 'little-five'), ('age', 22), ('email', '99426353*@qq,com')])
#值
print(info.values())
#输出为:dict_values(['little-five', 22, '99426353*@qq,com'])
2)字典for循环
info = {
"k1": 18,
2: True,
"k3": [
11,
[],
(),
22,
33,
{
'kk1': 'vv1',
'kk2': 'vv2',
'kk3': (11,22),
}
],
"k4": (11,22,33,44)
}
print("取出所有的key")
for item in info:
print(item)
结果:
取出所有的key
k1
2
k3
k4
print("取出所有的key")
for item in info.keys():
print(item)
结果:
取出所有的key
k1
2
k3
k4
print("取出所有的value")
for item in info.values():
print(item)
结果:
取出所有的value
18
True
[11, [], (), 22, 33, {'kk1': 'vv1', 'kk2': 'vv2', 'kk3': (11, 22)}]
(11, 22, 33, 44)
print("取出所有的key所对应的值")
for item in info.keys():
print(item,info[item])
结果:
取出所有的key所对应的值
k1 18
2 True
k3 [11, [], (), 22, 33, {'kk1': 'vv1', 'kk2': 'vv2', 'kk3': (11, 22)}]
k4 (11, 22, 33, 44)
print("取出所有的key所对应的值")
for k,v in info.items():
print(k,v)
结果:
取出所有的key所对应的值
k1 18
2 True
k3 [11, [], (), 22, 33, {'kk1': 'vv1', 'kk2': 'vv2', 'kk3': (11, 22)}]
k4 (11, 22, 33, 44)
3)字典支持 del 删除
info = {
"k1": 18,
2: True,
"k3": [
11,
[],
(),
22,
33,
{
'kk1': 'vv1',
'kk2': 'vv2',
'kk3': (11,22),
}
],
"k4": (11,22,33,44)
}
del info['k1']
del info['k3'][5]['kk1']
print(info)
7、集合 -->set类
关于集合set的定义:在我看来集合就像一个篮子,你可以往里面存东西也可往里面取东西,但是这些东西又是无序的,你很难指定单独去取某一样东西;同时它又可以通过一定的方法筛选去获得你需要的那部分东西。故集合可以 创建、增、删、关系运算。
集合的特性:
1、去重
2、无序
3、每个元素必须为不可变类型即(hashable类型,可作为字典的key)。
1)创建:set、frozenset
#1、创建,将会自动去重,其元素为不可变数据类型,即数字、字符串、元组
test01 ={"zhangsan","lisi","wangwu","lisi",666,("hello","world",),True}
#或者
test02 =set({"zhangsan","lisi","wangwu","lisi",666,("hello","world",),True})
#2、不可变集合的创建 -->frozenset()
test =frozenset({"zhangsan","lisi","wangwu","lisi",666,("hello","world",),True})
2)增: add、update
#更新单个值 --->add
names ={"zhangsan","lisi","wangwu"}
names.add("james") #其参数必须为hashable类型
print(names)
#更新多个值 -->update
names ={"zhangsan","lisi","wangwu"}
names.update({"alex","james"})#其参数必须为集合
print(names)
3)删除:pop、remove、discard
#随机删除 -->pop
names ={"zhangsan","lisi","wangwu","alex","james"}
names.pop()
print(names)
#指定删除,若要删除的元素不存在,则报错 -->remove
names ={"zhangsan","lisi","wangwu","alex","james"}
names.remove("lisi")
print(names)
#指定删除,若要删除的元素不存在,无视该方法 -->discard
names ={"zhangsan","lisi","wangwu","alex","james"}
names.discard("hello")
print(names)
4) 关系运算:交集 & 、并集 | 、差集 - 、交差补集 ^ 、 issubset 、isupperset
比如有两个班英语班和数学班,我们需要统计这两个班中报名情况,例如既报名了英语班有报名数学班的同学名字等等,这时候我们就可以应用到集合的关系运算:
english_c ={"ZhangSan","LiSi","James","Alex"}
math_c ={"WangWu","LiuDeHua","James","Alex"}
#1、交集--> in a and in b
#统计既报了英语班又报了数学班的同学
print(english_c & math_c)
print(english_c.intersection(math_c))
#输出为:{'Alex', 'James'}
#2、并集--> in a or in b
#统计报名了两个班的所有同学
print(english_c | math_c)
print(english_c.union(math_c))
#输出为:{'James', 'ZhangSan', 'LiuDeHua', 'LiSi', 'Alex', 'WangWu'}
#3、差集--> in a not in b
#统计只报名英语班的同学
print(english_c - math_c)
print(english_c.difference(math_c))
#输出为:{'LiSi', 'ZhangSan'}
4、交差补集
#统计只报名一个班的同学
print(english_c ^ math_c)
#输出为:{'LiuDeHua', 'ZhangSan', 'WangWu', 'LiSi'}
5)判断两个集合的关系是否为子集、父集 --> issubset 、isupperset
#issubset-->n 是否为 m 的子集
# issuperset --> n 是否为 m 的父集
n ={1,2,4,6,8,10}
m ={2,4,6}
l ={1,2,11}
print(n >= m)
#print(n.issuperset(m)) #n 是否为 m的父集
#print(n.issuperset(l))
print(m <=n)
#print(m.issubset(n)) #m 是否为 n的子集

















 227
227

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









