



为什么需要QucikList
一、ZipList的核心缺陷
尽管ZipList通过紧凑存储节省内存(如图片展示的变长编码设计),但其本质是连续的线性结构,导致以下问题:
-
连锁更新(Cascading Update)
- 当修改中间节点时(如插入/删除),由于其
previous_entry_length字段采用变长存储:- 若某个节点的长度变化导致跨越254字节分界线(如从253→254字节)
- 后续所有节点的
previous_entry_length需从1字节扩容到5字节,触发链式更新
- 后果:时间复杂度从O(1)退化为O(N),极端场景性能骤降。
- 当修改中间节点时(如插入/删除),由于其
-
大对象操作效率低下
- ZipList所有数据在内存中连续排列:
- 插入/删除节点需整体移动后续数据(类似数组)
- 对大列表操作的时间复杂度为O(N),无法接受高频写入场景。
- ZipList所有数据在内存中连续排列:
-
内存使用瓶颈
- 单块连续内存存储所有数据:
- 内存碎片问题严重(频繁修改导致无法复用释放的空间)
- 最大容量受单块内存分配限制(如32位系统最大4GB)
- 单块连续内存存储所有数据:
QuickList数据结构
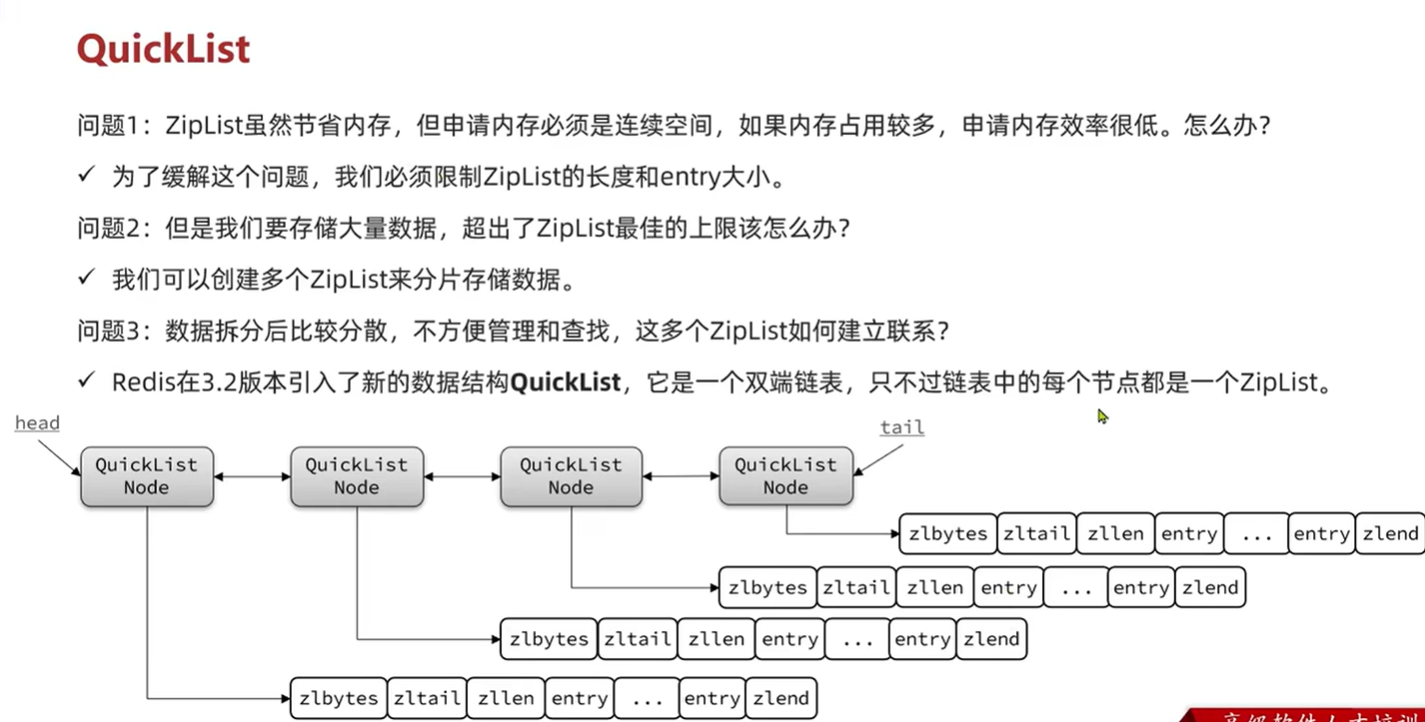

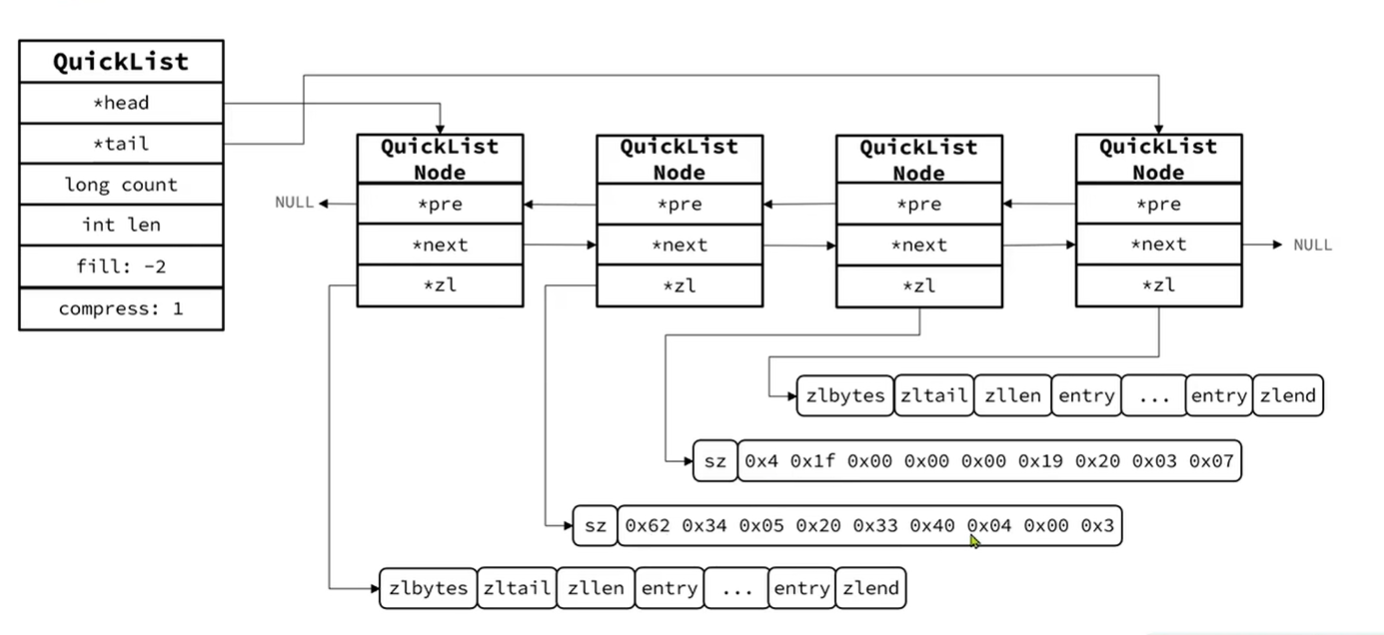
这里的中间的ZipList是压缩过后的结果 后面有说
QuickList内存优化
限制ZipList的大小
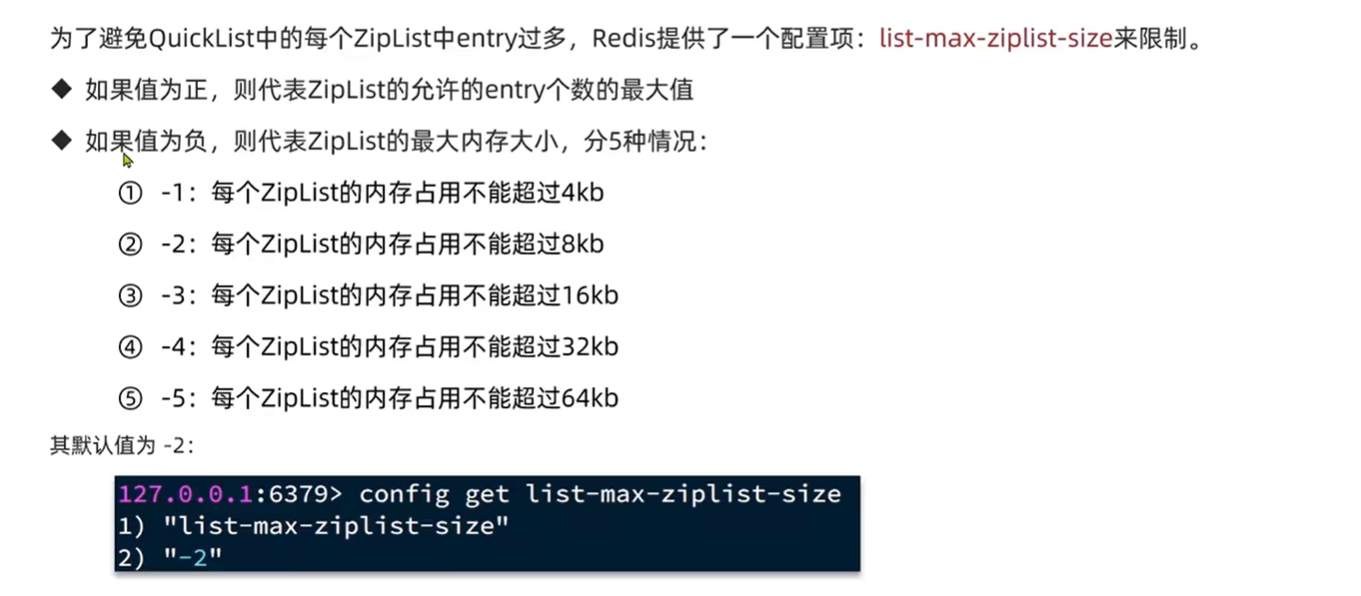
如果list-max-zip-size为正代表每个ZipList中entry个数最大值,但是可能entry对象过大还是有可能内存超出,所以推荐第二种方式
对ZipList进行压缩
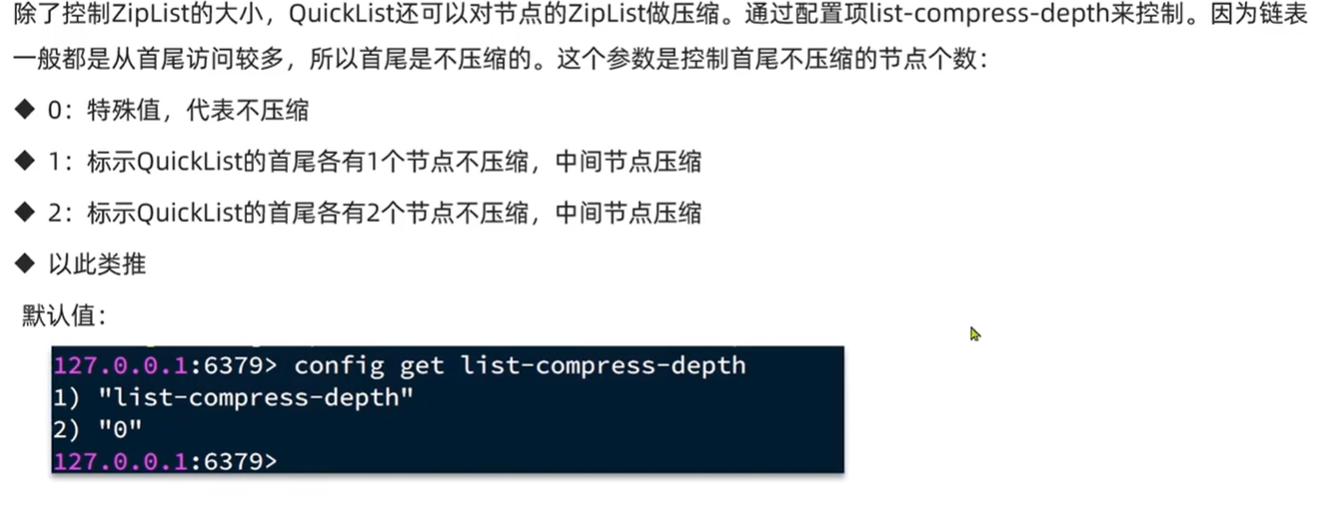
一般来说链表中间部分访问频率低,所以我们对低访问频率节点启用压缩,减少内存占用,这里的压缩都保证了首位节点不压缩,头部和尾部节点一般不压缩的核心原因是为了保证高频操作
从数据结构特性看:
| 操作类型 | 作用位置 | 典型场景 |
|---|---|---|
| LPUSH/LPOP | 头部节点 | 队列入队/出队(消息队列) |
| RPUSH/RPOP | 尾部节点 | 栈压入/弹出(历史记录) |
| LINDEX | 随机节点 | 数据查询(频率远低于头尾操作) |

















 1483
1483

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









