



ZipList数据结构
对于Dict来说最大的问题就是内存的浪费(内存不连续),在整个Dict中大量的使用了指针,而ziplist的内存空间是连续的,节省了很多内 存空间,不需要通过指针来寻址找到各个节点 ,有了这个特性从开始寻找到结束的就十分方便
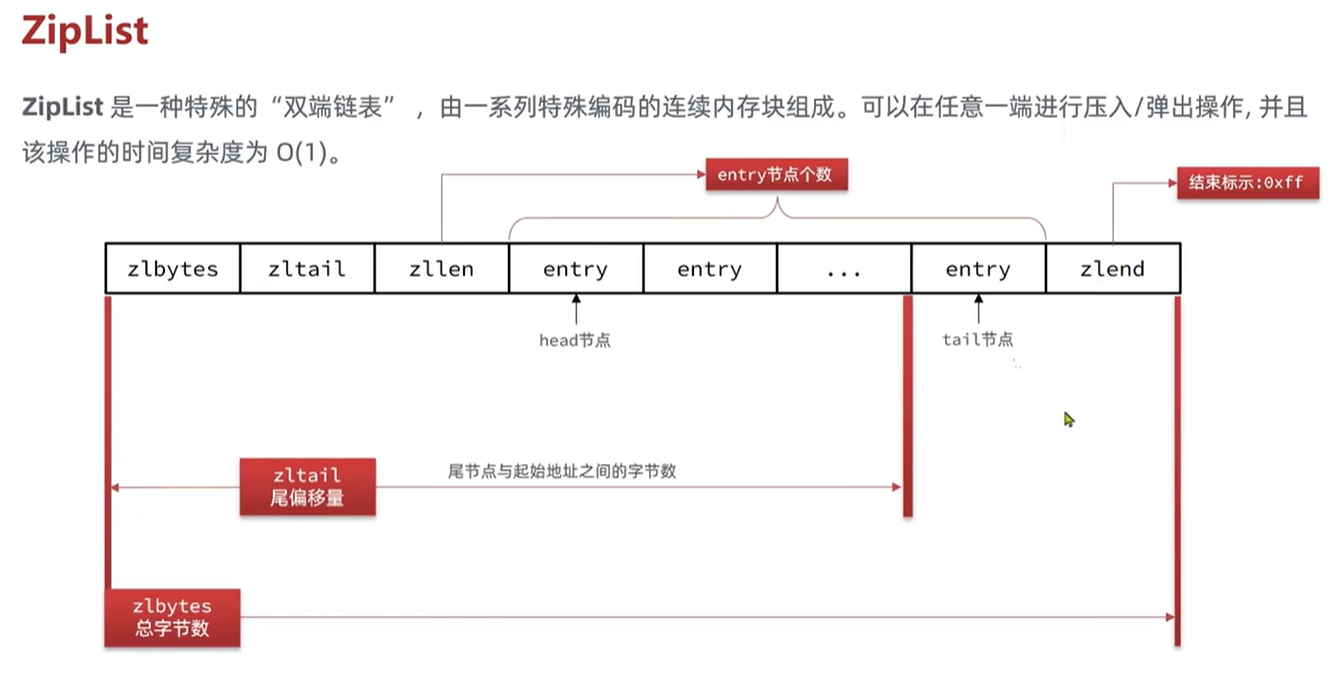
所有的这些标识字段所占用的大小是固定的
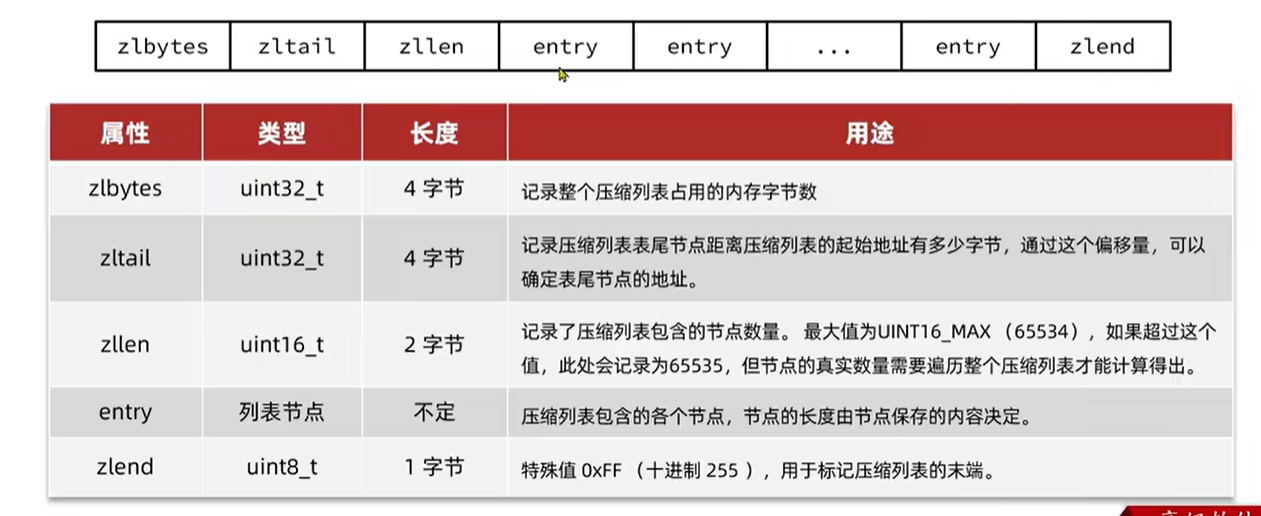
但是对于entry来说每个entry的大小是不固定的,为了节省内存空间,不同大小的entry占用不同的空间,那这里又有问题了大小不固定接下来证明去寻址遍历呢
ZipListEntry数据结构
如何实现双端列表逻辑 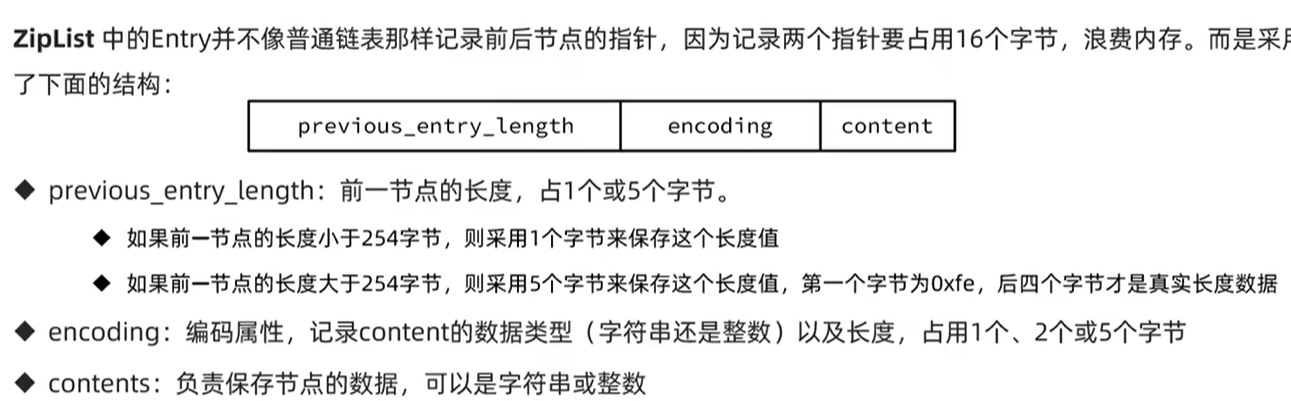
通过ZipListEntry的数据结构可以实现双端列表的逻辑,核心就是previous_entry_length字段,标识前一个节点的长度,如果是第一个节点那么长度为0
-
正向遍历(从头部到尾部)的逻辑实现:
- ZipList作为一个连续的内存块存储,所有Entry按照顺序排列(例如,Entry1、Entry2、Entry3等)。
- 要正向遍历(从头到尾),代码可以简单地从ZipList的开头开始,顺序访问每个Entry:
- 找到第一个Entry:ZipList的头部通常有额外元信息
- 读取当前Entry的
encoding和content,处理数据。 - 移动到下一个Entry:利用
encoding和content计算出当前Entry的总长度(包括所有字段),然后从当前结束位置跳到下一个Entry的起始位置。
-
反向遍历(从尾部到头部)的逻辑实现:
- 这是ZipList实现双端链表逻辑的核心,依赖于
previous_entry_length字段。 - 每个Entry的
previous_entry_length存储了前一节点的长度信息。通过这个字段,代码可以从任何节点开始反向移动到前一节点:- 找到最后一个Entry(通常ZipList的尾部可通过元信息或计算定位)。
- 读取当前Entry的
previous_entry_length:根据规则解析这个字段(如果是1字节直接读取长度;如果是5字节,跳过0xFE后读取后4字节)。 - 计算前一节点的位置:当前节点的起始地址减去
previous_entry_length的值就是前一节点的起始地址。 - 重复过程:移动到前一节点后,继续使用该节点的
previous_entry_length找到更前的节点,直到头部。
- 这是ZipList实现双端链表逻辑的核心,依赖于
Encoding编码
字符串
对于ab来说保存如下 二进制要转化为16进制
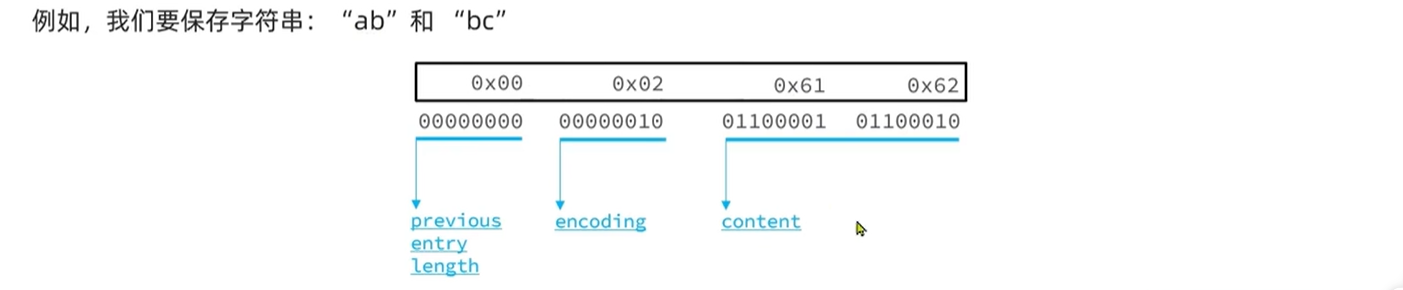
要注意的是ZipList中所有存储长度的数值采用小端字节序,即低位字节在前,高位字节在后

整数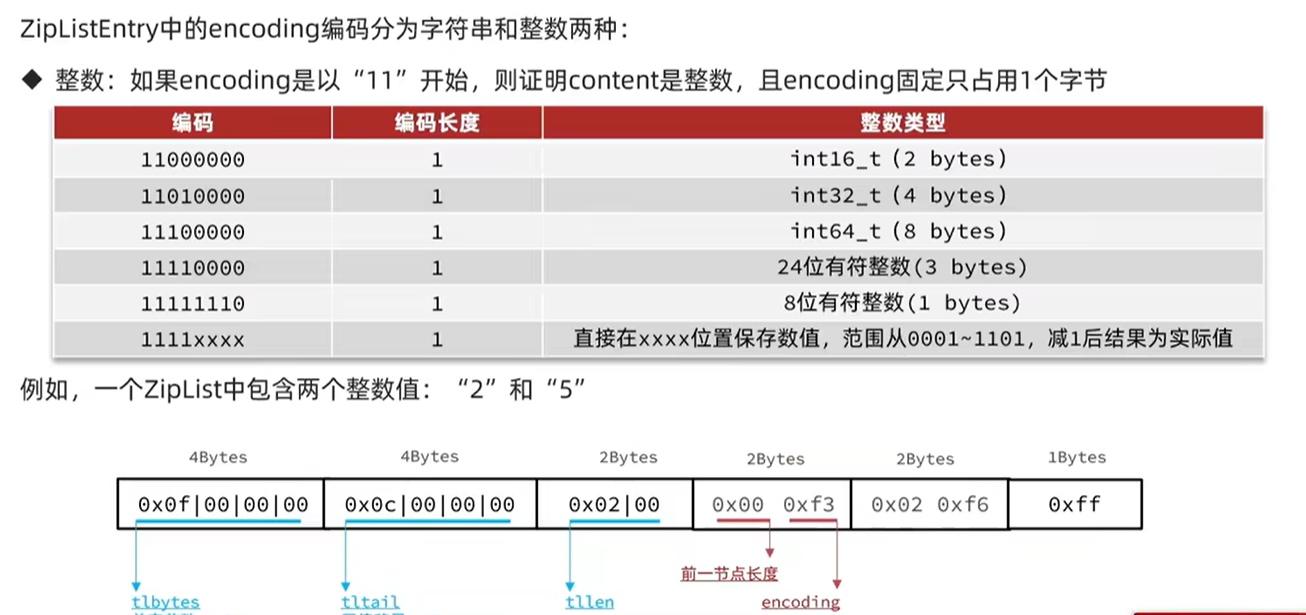
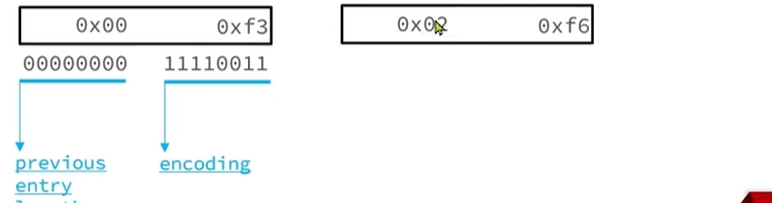
对于特别小的数来说,如果使用一个字节来表示,还是有点浪费内存,于是直接使用编码中的后四个比特位记录数值
ZipList连锁问题

如果说每个entry都是在250字节 如果插入了一个254字节的entry那么previous_entry_length要变程五个字节 后续的previous_entry_length也需要更新 一直连续下去


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









