



要理解前缀索引查询时“数据中的email不等于目标值”的情况,需要从前缀索引的结构、查询执行流程和性能影响三个维度展开:
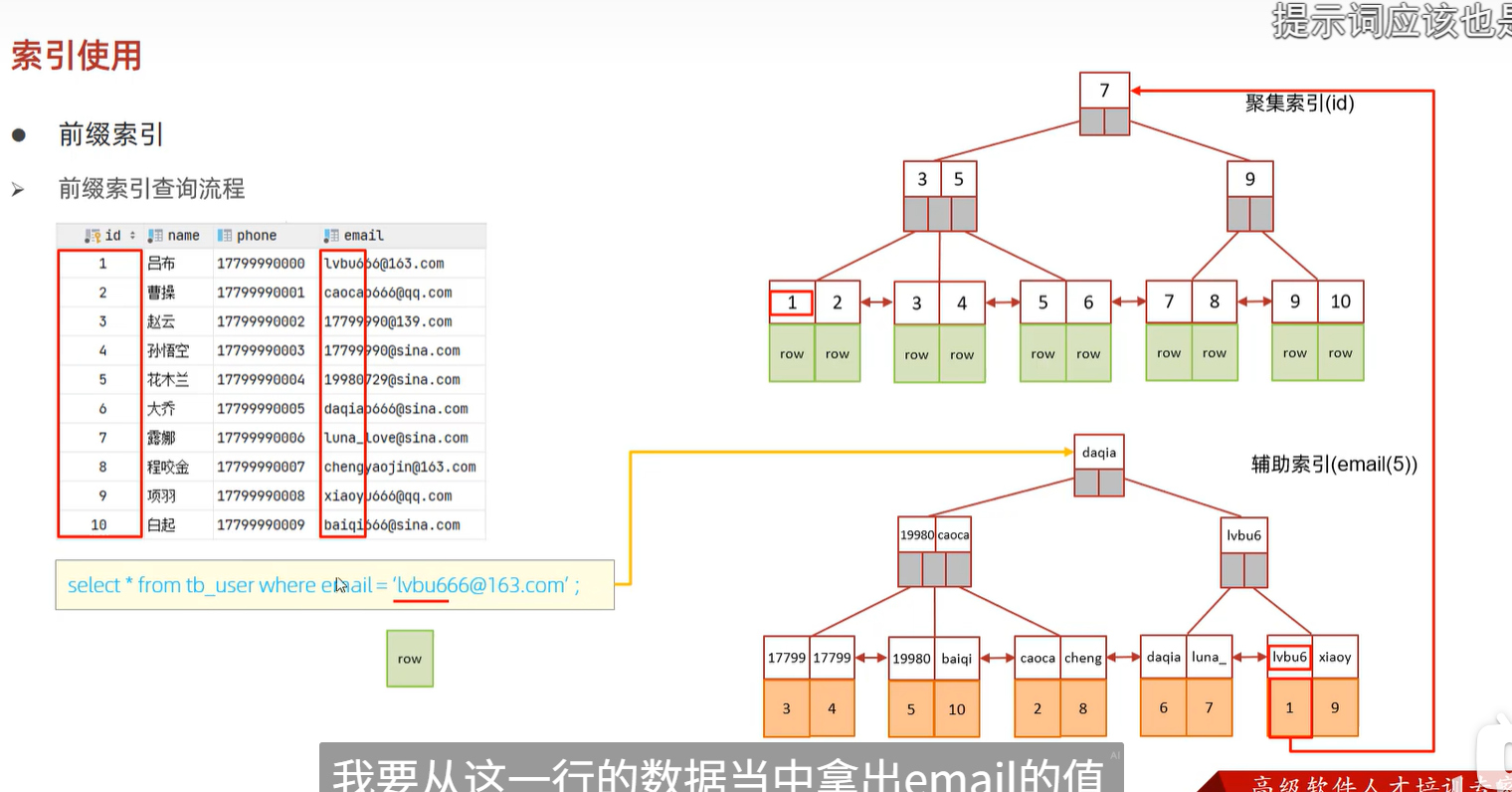
一、先明确:前缀索引的核心是“截断的索引键”
例子中的前缀索引是email(5),即仅取email字段的前5个字符作为索引键(如lvbu666@163.com的索引键是lvbu6)。 这种设计的目的是节省索引空间(比如email字段平均长度20字节,email(5)仅需5字节),但代价是可能失去部分“唯一性”——不同的email可能有相同的前5个字符。
二、查询时“email不等于目标值”的场景与流程
假设我们执行查询: SELECT * FROM tb_user WHERE email = 'lvbu666@163.com'; 前缀索引(email(5))的执行流程如下:
1. 第一步:用前缀索引找到所有“前5字符匹配”的行
前缀索引的B+树中,索引键是email的前5个字符(lvbu6)。优化器会快速定位到所有索引键等于lvbu6的叶子节点,获取对应的主键ID(比如例子中的id=1,以及可能的其他行,如id=X)。
注意:如果有其他行的
lvbu6(比如lvbu6xx@qq.com),这些行也会被索引“命中”。
2. 第二步:回表获取完整email值
由于前缀索引不包含完整的email字段(仅前5个字符),因此需要通过第一步得到的主键ID,到聚集索引(id为主键)中查询对应的完整行数据(包括email字段)。
比如例子中的id=1,回表后得到完整email是lvbu6@163.com
3. 第三步:过滤“完整值不匹配”的行
回表后,需要逐行比较完整的email值是否等于目标值(lvbu666@163.com)。如果不匹配(比如id=1的email是lvbu6@163.com),则这些行会被过滤掉,不会出现在最终结果中。
4. 最终结果:返回“完整值匹配”的行
只有当回表后的完整email值完全等于目标值时,该行才会被返回。如果所有“前5字符匹配”的行都不满足完整值条件,则返回空结果。
三、具体例子:假设id=1的email不等于目标值
比如例子中的id=1的email是lvbu6@163.com(前5字符lvbu6),而查询的目标是lvbu666@163.com(前5字符也是lvbu6):
- 索引命中:
id=1(前5字符匹配); - 回表取完整
email:lvbu6@163.com; - 过滤:
lvbu6@163.com != lvbu666@163.com,因此id=1被排除; - 结果:如果没有其他行的
email前5字符是lvbu6,则返回空结果。
四、这种情况的性能影响
当“前5字符匹配但完整值不匹配”时,会导致以下性能问题:
- 额外的回表开销:即使最终结果为空,也需要回表获取完整
email值(IO操作); - 扫描行数增加:如果有很多行的
email前5字符相同(比如lvbu6xxx@xx.com),索引会命中所有这些行,导致回表和过滤的行数增加; - 选择性下降:前缀索引的“选择性”(即不同索引键的数量)越低,越容易出现“前5字符匹配但完整值不匹配”的情况,性能越差。
五、如何避免或优化?
-
选择合适的前缀长度: 前缀长度太短(如
email(3))会导致选择性差,太多“前3字符匹配”的行;前缀长度太长(如email(20))则失去节省空间的意义。建议通过SELECT COUNT(DISTINCT LEFT(email, n))/COUNT(*)计算选择性,选择选择性接近1的最小n(比如n=8时选择性达到99%)。 -
使用覆盖索引: 如果查询的字段都包含在索引中(比如
SELECT id, email FROM tb_user WHERE email = ?),可以将email的完整值加入索引(如CREATE INDEX idx_email ON tb_user (email)),避免回表。 -
添加唯一约束: 如果
email是唯一的,可以添加UNIQUE约束(CREATE UNIQUE INDEX idx_email ON tb_user (email)),此时前缀索引的“前n字符”若能唯一标识行,则可以避免“前n字符匹配但完整值不匹配”的情况。
总结
当前缀索引查询时,**“数据中的email不等于目标值”**的情况会导致:
- 索引命中所有“前n字符匹配”的行;
- 回表获取完整
email值; - 过滤掉不匹配的行;
- 最终返回空或符合条件的行。
性能关键:前缀索引的选择性(即前n字符的唯一性)越高,“前n字符匹配但完整值不匹配”的情况越少,性能越好。反之,选择性越低,性能越差(需要扫描更多行、更多回表操作)。
例子中的补充说明: 在你提供的例子中,辅助索引(email(5))的叶子节点里,lvbu6对应的是id=1和id=9吗?看例子中的辅助索引结构,右边的叶子节点有一个红色框,里面是lvbu6和xiaoy,对应的id是1和9?比如id=1的email是lvbu6@163.com(前5字符lvbu6),id=9的email是xiaoy666@qq.com(前5字符xiaoy),所以当查询email='lvbu666@163.com'时,索引会命中id=1(前5字符lvbu6),回表后发现email不等于目标值,因此id=1被过滤掉,最终返回空结果。

















 308
308

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









