






序言
这次,我将解说 Google 介绍的用于检测LLM的幻觉的机制“RIG(检索交错生成)”。

https://research.google/blog/grounding-ai-in-reality-with-a-little-help-from-data-commons/![]() https://research.google/blog/grounding-ai-in-reality-with-a-little-help-from-data-commons/https://arxiv.org/pdf/2409.13741
https://research.google/blog/grounding-ai-in-reality-with-a-little-help-from-data-commons/https://arxiv.org/pdf/2409.13741![]() https://arxiv.org/pdf/2409.13741
https://arxiv.org/pdf/2409.13741
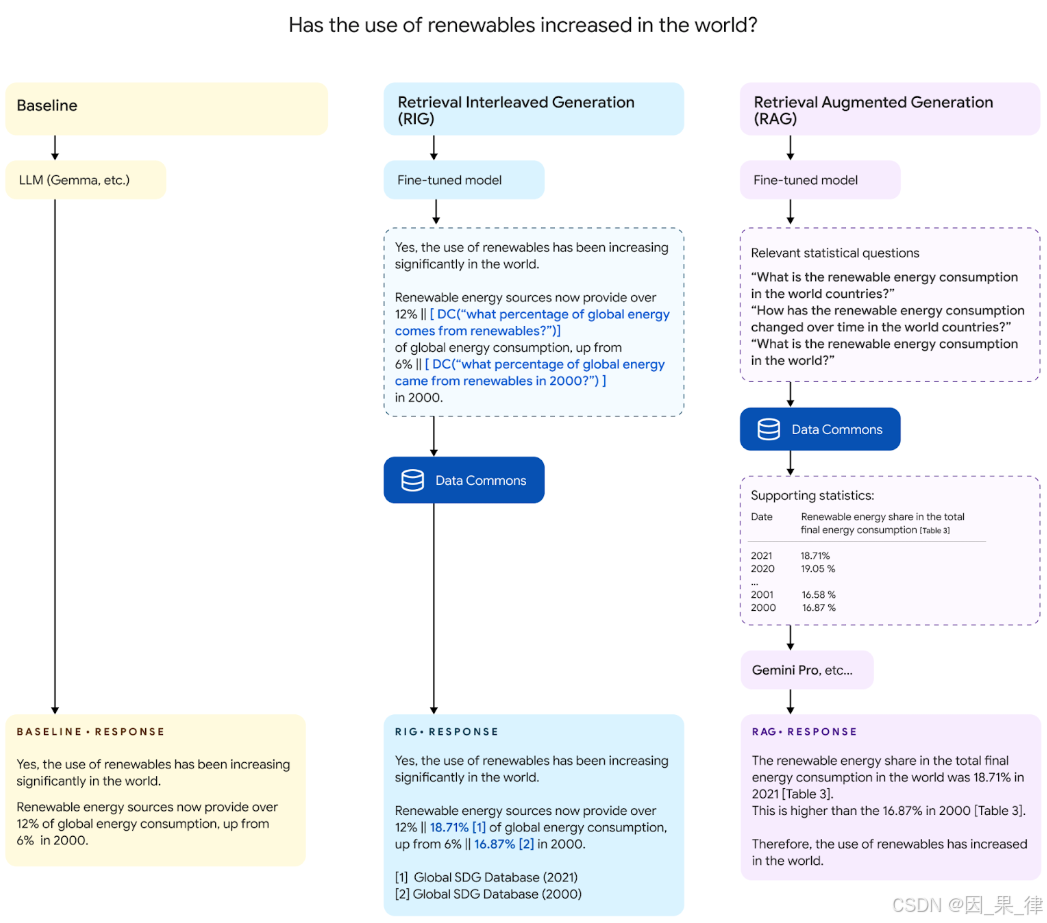
顺便提一下,这个 RIG 在 2024 年 9 月就已经公开了,但最近又被发布了,所以我希望能借此机会介绍一下!
摘要
LLM由于其性质,完全避免幻觉是困难的。因此,使用LLM时,用户需要在一定程度上准确判断信息。
然而,生成的文章中仅有信息的参考来源,判断真伪的难度大大降低。“RIG”通过对LLM进行微调,可以将LLM的输出与 Data Commons 中包含的参考数据联系起来。
这将使得LLM的输出变得更加可靠。
LLM的幻觉
LLM可能包含被称为幻觉的错误。此外,如果输出的句子没有相关知识,可能会难以察觉这些错误。因此,使用LLM可能导致对事实的误解,或者根本无法信任LLM的答案,导致使用困难。
RIG 是什么
概要
RIG 是一个判断LLM生成的回答是否正确的机制。针对LLM生成的回答,从一个名为 Data Commons 的大规模数据库中搜索并获取相关信息,并将结果作为依据进行提示。通过获得这个依据,用户可以将LLM所示的信息视为更可靠的数据进行处理。
手法
RIG 是如何获取依据信息的。
手顺如下。
- 在经过微调的LLM中回答用户的问题。这个微调的过程是为了学习如何将自然语言搜索查询嵌入到回答文本中。
- 提取嵌入在输出中的搜索查询。下图中所说的[DC(...)]部分。

- 将LLM输出的搜索查询转换为可以在 Data Commons 内搜索数据的查询。将使用嵌入和模板模式进行转换。
- 将查询搜索的结果应用于搜索查询部分并输出。

详细的特征
RIG 通过一些巧妙的设计,以高精度获取符合事实的数据。
不使用LLM的推论
LLM引起幻觉的原因被认为主要是推理。因此,RIG 仅限于利用LLM进行数据转换和自然语言搜索查询的转换,而不是推理。
自然语言查询的利用
在 RIG 中,查询信息时采用自然语言处理。严格来说,查询在一定程度上是格式化的,但并没有使用像 Json 这样的优化搜索的查询格式。其目的在于,LLM的输出更适合自然语言,并且在论文中提到这更简洁。
搜索查询的转换
在 Data Commons 的搜索中,采用基于规则的查询生成进行搜索,而不是使用嵌入的搜索。在 Data Commons 中,每个数据集合都有一个表格,其中存储了与地点或属性相关的具体数据。
具体来说,首先 RIG 会提取查询中包含的重要单词。提取的单词包括表示主题、地点、属性的单词等,主题通过 Embedding 用于表格的决策,其他信息则用于实际从表格中提取值的决策。
然后根据提取的信息和查询的信息,对查询的格式进行分类。
根据这些信息生成最终在 Data Commons 内获取信息的结构化查询。
从与 RAG 的区别来看其特点
在从数据库获取信息并提供给用户这一点上,RIG 和 RAG 似乎是相似的。然而,它们的目的和实现这一目标的手段是不同的,因此我将对此进行整理。
| 観点 | RIG | RAG |
|---|---|---|
| 目的 | 显示LLM的声明是否正确的依据 | 根据用户所需的信息进行搜索和推理后进行回答 |
| 検索 内容 | 搜索内容已确定 | 推断应该搜索的内容 |
| 検索 方法 | 不使用LLM的转换逻辑进行搜索 | 将文章转换为向量进行搜索 |
| 出力 | 在许多情况下,单一的数据 | 符合问题的自然句子 |
RIG 与 RAG 的出发地点不同。虽然有些重复,但 RIG 会基于输出的文本确认其内容是否正确。或者,可以说 RIG 通过更明确的目标来提高对目标的准确性。
成果
接下来,我将介绍利用 RIG 能够了解到多大程度的正确信息,以及 RIG 和 RAG 因何原因会提供不准确的信息的总结结果。
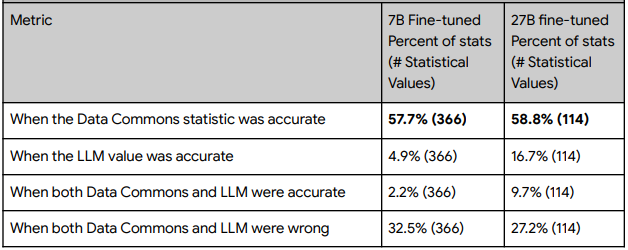
从这个表中可以看出,首先LLM直接回答问题的概率为 5-17%,而 RIG 获得正确结果的概率大约为 58%,大幅改善。另一方面,表明在 27-32%的概率下,两者都未能返回正确结果。
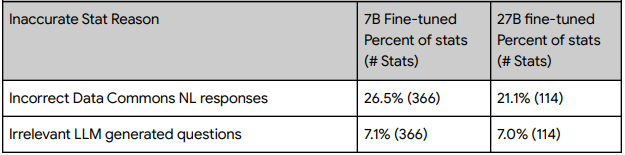
这个表格分析了 RIG 未能返回正确结果的原因。未能返回正确结果的原因大约 75%是由于将自然语言搜索查询转换为结构化查询的过程中的错误,其余大约 25%则是在生成自然语言搜索查询阶段的错误。
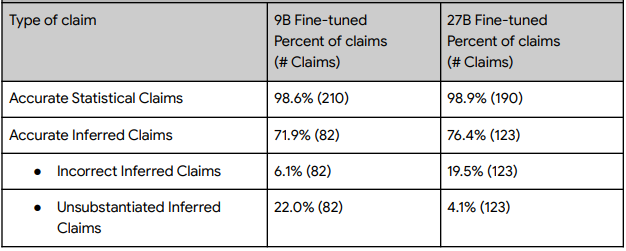
接下来是使用 RAG 的回答准确性相关结果。在直接搜索统计值的任务中,其准确性大约为 99%,相当高。然而,当试图使用推理进行主张时,准确性下降了 22-27%。
分析原因后,性能较低的模型倾向于通过推理输出数据中不存在的信息,而性能较高的模型则倾向于输出错误的推理(遗漏)。
请注意,这个结果表示在获取到正确的信息的基础上与正确回答相联系的概率,并且没有考虑到数据搜索失败的情况。
总结
介绍了检测LLM的幻觉的“RIG”。希望能整理出这个功能的目的和与 RAG 的区别。从这里开始,我想结合个人的感想,从几个角度总结一下 RIG。
吸引人的点
这个方法中我觉得特别有趣的有两个点。
通过限定目的来提高精度的尝试
RAG 的方法由于覆盖范围广,因此即使被认为精度高的方法在目的不同的情况下也常常无法达到精度。RIG 专注于真伪的确认,特别是统计值的真伪确认,致力于提高精度,我认为这在这一点上是一个有趣的思路。
数据的搜索方法
一般来说,RAG 通常将自然语言直接通过 Embedding 转换为向量进行搜索,或者直接生成结构化数据进行搜索。相比之下,RIG 利用符合格式的自然语言进行搜索。正如之前提到的,这使得我们能够同时获得自然语言简洁搜索表达和结构化数据严格搜索的优点。(当然,也可能继承双方的缺点。)我认为这是LLM与数据库之间接触的有趣手段。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









