







机器学习概述
机器学习的一般任务是利用有标记的数据,学习属性(标记)与相应(目标)之间的函数关系,来预测未标记属性输入的相应。
一般按照是否标记分为有监督学习和无监督学习。
1.损失函数的矩阵化
一般我们使用如下的均方损失来计算模型的损失:
L
=
1
N
∑
n
−
1
N
(
t
n
−
w
⊤
x
n
)
2
\mathcal{L}=\frac{1}{N} \sum_{n-1}^{N}\left(t_{n}-\mathbf{w}^{\top} \mathbf{x}_{n}\right)^{2}
L=N1n−1∑N(tn−w⊤xn)2
注意到当
x
\mathbf{x}
x的元素变多时,损失的计算就会非常复杂,同时也为了让计算机计算方便我们要将上式变为向量和矩阵的形式:
L
=
1
N
(
t
−
X
w
)
⊤
(
t
−
X
w
)
\mathcal{L}=\frac{1}{N}(\mathbf{t}-\mathbf{X} \mathbf{w})^{\top}(\mathbf{t}-\mathbf{X} \mathbf{w})
L=N1(t−Xw)⊤(t−Xw)
其中有:
X
=
[
x
1
⊤
x
2
⊤
⋮
x
N
⊤
]
=
[
1
x
1
1
x
2
⋮
⋮
1
x
N
]
,
t
=
[
t
1
t
2
⋮
t
N
]
,
w
=
[
w
1
w
2
]
\mathbf{X}=\left[\begin{array}{c} \mathbf{x}_{1}^{\top} \\ \mathbf{x}_{2}^{\top} \\ \vdots \\ \mathbf{x}_{N}^{\top} \end{array}\right]=\left[\begin{array}{cc} 1 & x_{1} \\ 1 & x_{2} \\ \vdots & \vdots \\ 1 & x_{N} \end{array}\right], \mathbf{t}=\left[\begin{array}{c} t_{1} \\ t_{2} \\ \vdots \\ t_{N} \end{array}\right], \mathbf{w}=\left[\begin{array}{c} w_{1} \\ w_{2} \\ \end{array}\right]
X=⎣⎢⎢⎢⎡x1⊤x2⊤⋮xN⊤⎦⎥⎥⎥⎤=⎣⎢⎢⎢⎡11⋮1x1x2⋮xN⎦⎥⎥⎥⎤,t=⎣⎢⎢⎢⎡t1t2⋮tN⎦⎥⎥⎥⎤,w=[w1w2]
为了理解这个变化我们首先记住两个细节,在第一个式子中,预测值 w ⊤ x n \mathbf{w}^{\top} \mathbf{x}_{n} w⊤xn中系数参数向量转置后与 x \mathbf{x} x矩阵相乘,其实这里的顺序并没有所谓,因为得到的是常数,但是在第二个式子中变为 X w \mathbf{X} \mathbf{w} Xw,即是 X \mathbf{X} X的行乘以 w \mathbf{w} w的列,故这里得到了所有与预测值的列向量。之后与真实值的向量做差,转置成为 1 ∗ n 1*n 1∗n的向量再与 n ∗ 1 n*1 n∗1的自己相乘得到平方和。.
2.最大似然估计
极大似然法的想法十分自然,当某种现象可能由多个原因中的一个造成时,我们认为是可能性最大的哪一种。所以,这种估计法就是要取可能性最大的那个参数作为参数的估计。
若总体为离散的总体,样本的二重性可以解释为:
{
X
1
=
x
1
,
X
2
=
x
2
,
⋯
,
X
n
=
x
n
}
\left.\{ X_{1}=x_{1}, X_{2}=x_{2}, \cdots, X_{n}=x_{n}\right\}
{X1=x1,X2=x2,⋯,Xn=xn}
这时,上式的概率为:
P
∣
X
1
=
x
1
,
X
2
=
x
2
,
⋯
,
X
n
=
x
n
∣
=
∏
i
=
1
n
P
{
X
i
=
x
i
}
=
∏
i
=
1
n
f
(
x
i
;
θ
)
P\left|X_{1}=x_{1}, X_{2}=x_{2}, \cdots, X_{n}=x_{n}\right|=\prod_{i=1}^{n} P\left\{X_{i}=x_{i}\right\}=\prod_{i=1}^{n} f\left(x_{i} ; \theta\right)
P∣X1=x1,X2=x2,⋯,Xn=xn∣=i=1∏nP{Xi=xi}=i=1∏nf(xi;θ)
上式中
θ
\theta
θ为参数。
若总体为连续总体,取一点的概率为0,所谓的样本观察值
(
x
1
,
x
2
,
.
.
.
,
x
n
)
(x_1,x_2,...,x_n)
(x1,x2,...,xn)落在了一个充分小的邻域内部,此时有
P
∣
(
X
1
,
X
2
,
⋯
,
X
n
)
∈
δ
(
x
1
,
x
2
,
⋯
,
x
n
)
∣
≈
∏
n
f
(
x
i
;
θ
)
⋅
∣
δ
(
x
1
,
x
2
,
⋯
,
x
n
)
∣
P\left|\left(X_{1}, X_{2}, \cdots, X_{n}\right) \in \delta\left(x_{1}, x_{2}, \cdots, x_{n}\right)\right| \approx \prod_{n} f\left(x_{i} ; \theta\right) \cdot\left|\delta\left(x_{1}, x_{2}, \cdots, x_{n}\right)\right|
P∣(X1,X2,⋯,Xn)∈δ(x1,x2,⋯,xn)∣≈n∏f(xi;θ)⋅∣δ(x1,x2,⋯,xn)∣
两种情况可以统一记为:
L
(
θ
)
≜
∏
i
=
1
n
f
(
x
i
;
θ
)
L(\theta) \triangleq \prod_{i=1}^{n} f\left(x_{i} ; \theta\right)
L(θ)≜i=1∏nf(xi;θ)
我们将
L
(
θ
)
L(\theta)
L(θ)称为似然函数。显然对上式来说,观察中样本的观测值是确定的,所以上式就是参数
θ
\theta
θ的函数。那么依据刚刚讨论的最大似然估计的思想,使得似然函数取最大的参数
θ
\theta
θ就是我们的点估计结果。
L
(
θ
^
)
=
sup
θ
∈
Θ
L
(
θ
)
=
sup
θ
∈
Θ
∏
i
=
1
n
f
(
X
i
;
θ
)
L(\hat{\theta})=\sup _{\theta\in\Theta} L(\theta)=\sup _{\theta \in \Theta} \prod_{i=1}^{n} f\left(X_{i} ; \theta\right)
L(θ^)=θ∈ΘsupL(θ)=θ∈Θsupi=1∏nf(Xi;θ)
如果似然函数连续可微,则令:
d
L
(
θ
)
d
θ
=
0
\frac{dL(\theta)}{d\theta} = 0
dθdL(θ)=0
或者可以对似然函数求对数之后再微分。得到的解就时参数的最大似然估计。
3.贝叶斯方法
机器学习中最基础的线性模型,依赖最小二乘法,使用均方损失作为损失函数,可以给出某个具体的目标值,但是有些情况下直接给出一个具体的预测值说服力不足,我们需要给出一系列的可能值做为预测值的候选,并且计算出他们的概率,通常我们会取概率最大的候选值作为预测值。
贝叶斯方法将我们要训练的参数视为变量,这个方法的目的是通过贝叶斯定理求解参数(或者说是后验)的分布。
贝叶斯方法基础
贝叶斯方法依据贝叶斯定理:
p
(
r
∣
y
N
)
=
P
(
y
N
∣
r
)
p
(
r
)
P
(
y
N
)
p\left(r \mid y_{N}\right)=\frac{P\left(y_{N} \mid r\right) p(r)}{P\left(y_{N}\right)}
p(r∣yN)=P(yN)P(yN∣r)p(r)
贝叶斯估计给出一种将先验假设和观测值的统一显式表达形式,贝叶斯方法也给出了在观测数据
y
n
y_n
yn已知后,
r
r
r的概率分布。要么使用
p
(
r
∣
y
N
)
p\left(r \mid y_{N}\right)
p(r∣yN)最大时的
r
r
r值,要么使用期望
E
p
(
r
∣
y
N
)
\mathbf{E}_{p\left(r \mid y_{N}\right)}
Ep(r∣yN)计算分布的期望作为
r
r
r的值。
先验
通常我们需要先验来自我们的假设,有时为了便于分析会选择特定的先验分布。
似然
我们对似然的理解非常重要,似然值表示的是在特定的 r r r取值下,观察到数据的可能性,比如在抛硬币时,若硬币向上的概率是0.6,则抛十次硬币,向上次数服从二项分布,而可能性最大是6次。
边缘
边缘密度是通过联合密度积分而来:
P
(
y
N
)
=
∫
r
=
0
r
=
1
p
(
y
N
,
r
)
d
r
P\left(y_{N}\right)=\int_{r=0}^{r=1} p\left(y_{N}, r\right) d r
P(yN)=∫r=0r=1p(yN,r)dr
P
(
y
N
)
=
∫
r
=
0
r
=
1
P
(
y
N
∣
r
)
p
(
r
)
d
r
P\left(y_{N}\right)=\int_{r=0}^{r=1} P\left(y_{N} \mid r\right) p(r) d r
P(yN)=∫r=0r=1P(yN∣r)p(r)dr
点估计
略
后验的期望
略
4. 贝叶斯推理
贝叶斯推理应用在贝叶斯方法中先验和似然不共轭时(实际上在实际情况中,共轭是罕见的),后验不可解析,因此我们需要使用近似的方法。
现在我们以常见的二值相应问题为例(二分类问题):
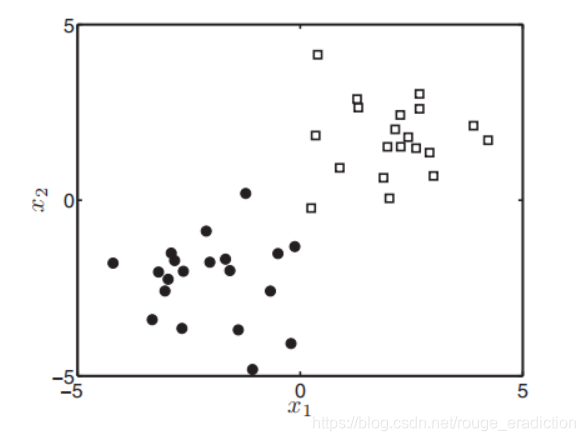
每个对象的属性是(
x
1
,
x
2
x_1,x_2
x1,x2)相应值是
t
,
(
t
=
0
o
r
1
)
t,(t = 0 or 1)
t,(t=0or1),矩阵表示:
x
n
=
[
x
n
1
x
n
2
]
,
w
=
[
w
1
w
2
]
,
X
=
[
x
1
⊤
x
2
⊤
⋮
x
N
⊤
]
\mathbf{x}_{n}=\left[\begin{array}{l} x_{n 1} \\ x_{n 2} \end{array}\right], \mathbf{w}=\left[\begin{array}{c} w_{1} \\ w_{2} \end{array}\right], \mathbf{X}=\left[\begin{array}{c} \mathbf{x}_{1}^{\top} \\ \mathbf{x}_{2}^{\top} \\ \vdots \\ \mathbf{x}_{N}^{\top} \end{array}\right]
xn=[xn1xn2],w=[w1w2],X=⎣⎢⎢⎢⎡x1⊤x2⊤⋮xN⊤⎦⎥⎥⎥⎤
我们需要一个模型依据已知的标签数据,给未知标签的数据
x
n
e
w
x_{new}
xnew打标签
t
n
e
w
t_{new}
tnew,依据贝叶斯定理:
p
(
w
∣
t
,
X
)
=
p
(
t
∣
X
,
w
)
p
(
w
)
p
(
t
∣
X
)
p(\mathbf{w} \mid \mathbf{t}, \mathbf{X})=\frac{p(\mathbf{t} \mid \mathbf{X}, \mathbf{w}) p(\mathbf{w})}{p(\mathbf{t} \mid \mathbf{X})}
p(w∣t,X)=p(t∣X)p(t∣X,w)p(w)
上式做了一些小小的变换和一般的贝叶斯定理不同,请读者自行推导,然后我们要对先验和似然进行讨论。
先验
我们假设为高斯分布(为了讨论方便),先验不是我们的重点,可以表示为:
p
(
w
∣
σ
2
)
p(w|\sigma^2)
p(w∣σ2)
似然
我们首先假设在已知数据中,数据的响应取值是相互条件独立的,并且是依赖于
w
w
w的:
p
(
t
∣
X
,
w
)
=
∏
n
=
1
N
p
(
t
n
∣
x
n
,
w
)
p(\mathbf{t} \mid \mathbf{X}, \mathbf{w})=\prod_{n=1}^{N} p\left(t_{n} \mid \mathbf{x}_{n}, \mathbf{w}\right)
p(t∣X,w)=n=1∏Np(tn∣xn,w)
由于
t
t
t只有两个取值,设为0和1,用0表示这个点的响应在图上的形状是圆圈,若是1则为正方形,那么样本的二重性可以表示为:
{
T
1
=
t
1
,
T
2
=
t
2
,
⋯
,
T
n
=
t
n
}
,
t
i
=
0
o
r
1
\left.\{ T_{1}=t_{1}, T_{2}=t_{2}, \cdots, T_{n}=t_{n}\right\},t_i = 0 or 1
{T1=t1,T2=t2,⋯,Tn=tn},ti=0or1
则有
p
(
t
∣
X
,
w
)
=
∏
n
=
1
N
P
(
T
n
=
t
n
∣
x
n
,
w
)
p(\mathbf{t} \mid \mathbf{X}, \mathbf{w})=\prod_{n=1}^{N} P\left(T_{n}=t_{n} \mid \mathbf{x}_{n}, \mathbf{w}\right)
p(t∣X,w)=n=1∏NP(Tn=tn∣xn,w)
现在我们则需要给定一个先验可能符合的分布,使得在
x
n
x_n
xn,
w
w
w进行线性变化之后得到一个有效的概率,这个概率我们使用sigmoid函数来获得:
P
(
T
n
=
1
∣
x
n
,
w
)
=
1
1
+
exp
(
−
w
⊤
x
n
)
P\left(T_{n}=1 \mid \mathbf{x}_{n}, \mathbf{w}\right)=\frac{1}{1+\exp \left(-\mathbf{w}^{\top} \mathbf{x}_{n}\right)}
P(Tn=1∣xn,w)=1+exp(−w⊤xn)1
现在我觉得先介绍基于sigmoid函数的二分类问题会比较容易理解,有:
P
(
T
n
=
0
∣
x
n
,
w
)
=
1
−
P
(
T
n
=
1
∣
x
n
,
w
)
=
1
−
1
1
+
exp
(
−
w
⊤
x
n
)
=
exp
(
−
w
⊤
x
n
)
1
+
exp
(
−
w
⊤
x
n
)
\begin{aligned} P\left(T_{n}=0 \mid \mathbf{x}_{n}, \mathbf{w}\right) &=1-P\left(T_{n}=1 \mid \mathbf{x}_{n}, \mathbf{w}\right) \\ &=1-\frac{1}{1+\exp \left(-\mathbf{w}^{\top} \mathbf{x}_{n}\right)} \\ &=\frac{\exp \left(-\mathbf{w}^{\top} \mathbf{x}_{n}\right)}{1+\exp \left(-\mathbf{w}^{\top} \mathbf{x}_{n}\right)} \end{aligned}
P(Tn=0∣xn,w)=1−P(Tn=1∣xn,w)=1−1+exp(−w⊤xn)1=1+exp(−w⊤xn)exp(−w⊤xn)
为了让
T
n
T_n
Tn取不同的值时统一表达,有:
p
(
t
∣
X
,
w
)
=
∏
n
=
1
N
P
(
T
n
=
1
∣
x
n
w
)
t
n
P
(
T
n
=
0
∣
x
n
,
w
)
1
−
t
n
=
∏
n
=
1
N
(
1
1
+
exp
(
−
w
⊤
x
n
)
)
t
n
(
exp
(
−
w
⊤
x
n
)
1
+
exp
(
−
w
⊤
x
n
)
)
1
−
t
n
\begin{aligned} p(\mathbf{t} \mid \mathbf{X}, \mathbf{w}) &=\prod_{n=1}^{N} P\left(T_{n}=1 \mid \mathbf{x}_{n} \mathbf{w}\right)^{t_{n}} P\left(T_{n}=0 \mid \mathbf{x}_{n}, \mathbf{w}\right)^{1-t_{n}} \\ &=\prod_{n=1}^{N}\left(\frac{1}{1+\exp \left(-\mathbf{w}^{\top} \mathbf{x}_{n}\right)}\right)^{t_{n}}\left(\frac{\exp \left(-\mathbf{w}^{\top} \mathbf{x}_{n}\right)}{1+\exp \left(-\mathbf{w}^{\top} \mathbf{x}_{n}\right)}\right)^{1-t_{n}} \end{aligned}
p(t∣X,w)=n=1∏NP(Tn=1∣xnw)tnP(Tn=0∣xn,w)1−tn=n=1∏N(1+exp(−w⊤xn)1)tn(1+exp(−w⊤xn)exp(−w⊤xn))1−tn
边缘密度
边缘密度可以写成:
Z
−
1
=
p
(
t
∣
X
,
σ
2
)
=
∫
p
(
t
∣
X
,
w
)
p
(
w
∣
σ
2
)
d
w
Z^{-1}=p\left(\mathbf{t} \mid \mathbf{X}, \sigma^{2}\right)=\int p(\mathbf{t} \mid \mathbf{X}, \mathbf{w}) p\left(\mathbf{w} \mid \sigma^{2}\right) d \mathbf{w}
Z−1=p(t∣X,σ2)=∫p(t∣X,w)p(w∣σ2)dw
似然作为贝叶斯定理右边的分母,是不能通过解析求解获得的,这是由于sigmoid函数与高斯分布的概率分布相乘的形式太过复杂。那么在这种不共轭的情况下,我们有三种方法:
- 与最大似然估计的思维相同,我们可以取使得后验最大的参数 w w w作为对 w w w的估计。
- 通过其他方法近似 p ( w ∣ X , t , σ 2 ) p(w| \mathbf{X}, \mathbf{t},\sigma^2) p(w∣X,t,σ2)
- 知道 g ( w ; X , t , σ 2 ) g(w; \mathbf{X}, \mathbf{t},\sigma^2) g(w;X,t,σ2)的情况下对后验进行采样。
第一种方法——最大后验估计
由于贝叶斯定理的分母与参数
w
w
w没有显式联系,则只与分子成正比,可设:
g
(
w
;
X
,
t
)
=
p
(
t
∣
X
,
w
)
p
(
w
∣
X
,
σ
2
)
g(w; \mathbf{X}, \mathbf{t}) = p(t| \mathbf{X},w)p(w| \mathbf{X},\sigma^2)
g(w;X,t)=p(t∣X,w)p(w∣X,σ2)
进而有:
log
g
(
w
;
X
,
t
)
=
log
p
(
t
∣
X
,
w
)
+
log
p
(
w
∣
σ
2
)
\log g(\mathbf{w} ; \mathbf{X}, \mathbf{t})=\log p(\mathbf{t} \mid \mathbf{X}, \mathbf{w})+\log p\left(\mathbf{w} \mid \sigma^{2}\right)
logg(w;X,t)=logp(t∣X,w)+logp(w∣σ2)
使用之前对似然的推导有:
log
g
(
w
;
X
,
t
)
=
∑
n
=
1
N
log
P
(
T
n
=
t
n
∣
x
n
,
w
)
+
log
p
(
w
∣
σ
2
)
=
∑
n
=
1
N
log
[
(
1
1
+
exp
(
−
w
⊤
x
n
)
)
t
n
(
exp
(
−
w
⊤
x
n
)
1
+
exp
(
−
w
⊤
x
n
)
)
1
−
t
n
]
+
log
p
(
w
∣
σ
2
)
\begin{aligned} \log g(\mathbf{w} ; \mathbf{X}, \mathbf{t})=& \sum_{n=1}^{N} \log P\left(T_{n}=t_{n} \mid \mathbf{x}_{n}, \mathbf{w}\right)+\log p\left(\mathbf{w} \mid \sigma^{2}\right) \\ =& \sum_{n=1}^{N} \log \left[\left(\frac{1}{1+\exp \left(-\mathbf{w}^{\top} \mathbf{x}_{n}\right)}\right)^{t_{n}}\left(\frac{\exp \left(-\mathbf{w}^{\top} \mathbf{x}_{n}\right)}{1+\exp \left(-\mathbf{w}^{\top} \mathbf{x}_{n}\right)}\right)^{1-t_{n}}\right] \\ &+\log p\left(\mathbf{w} \mid \sigma^{2}\right) \end{aligned}
logg(w;X,t)==n=1∑NlogP(Tn=tn∣xn,w)+logp(w∣σ2)n=1∑Nlog⎣⎡(1+exp(−w⊤xn)1)tn(1+exp(−w⊤xn)exp(−w⊤xn))1−tn⎦⎤+logp(w∣σ2)
假设
w
w
w是
D
D
D维的,并且设:
P
n
=
P
(
T
n
=
1
∣
w
,
x
n
)
=
1
1
+
exp
(
−
w
⊤
x
n
)
P_{n}=P\left(T_{n}=1 \mid \mathbf{w}, \mathbf{x}_{n}\right)=\frac{1}{1+\exp \left(-\mathbf{w}^{\top} \mathbf{x}_{n}\right)}
Pn=P(Tn=1∣w,xn)=1+exp(−w⊤xn)1
显然此时有:
∂
P
n
∂
w
=
∂
(
1
+
exp
(
−
w
⊤
x
n
)
)
−
1
∂
(
1
+
exp
(
−
w
⊤
x
n
)
)
∂
(
1
+
exp
(
−
w
⊤
x
n
)
)
∂
w
exp
(
−
w
⊤
x
n
)
(
−
x
n
)
=
−
1
(
1
+
exp
(
−
w
⊤
x
n
)
)
2
x
n
=
exp
(
−
w
⊤
x
n
)
(
1
+
exp
(
−
w
⊤
x
n
)
)
2
x
n
=
1
1
+
exp
(
−
w
⊤
x
n
)
exp
(
−
w
⊤
x
n
)
1
+
exp
(
−
w
⊤
x
)
x
n
=
P
n
(
1
−
P
n
)
x
n
\begin{aligned} \frac{\partial P_{n}}{\partial \mathbf{w}} &=\frac{\partial\left(1+\exp \left(-\mathbf{w}^{\top} \mathbf{x}_{n}\right)\right)^{-1}}{\partial\left(1+\exp \left(-\mathbf{w}^{\top} \mathbf{x}_{n}\right)\right)} \frac{\partial\left(1+\exp \left(-\mathbf{w}^{\top} \mathbf{x}_{n}\right)\right)}{\partial \mathbf{w}} \exp \left(-\mathbf{w}^{\top} \mathbf{x}_{n}\right)\left(-\mathbf{x}_{n}\right) \\ &=-\frac{1}{\left(1+\exp \left(-\mathbf{w}^{\top} \mathbf{x}_{n}\right)\right)^{2}} \mathbf{x}_{n} \\ &=\frac{\exp \left(-\mathbf{w}^{\top} \mathbf{x}_{n}\right)}{\left(1+\exp \left(-\mathbf{w}^{\top} \mathbf{x}_{n}\right)\right)^{2}} \mathbf{x}_{n} \\ &=\frac{1}{1+\exp \left(-\mathbf{w}^{\top} \mathbf{x}_{n}\right)} \frac{\exp \left(-\mathbf{w}^{\top} \mathbf{x}_{n}\right)}{1+\exp \left(-\mathbf{w}^{\top} \mathbf{x}\right)} \mathbf{x}_{n} \\ &=P_{n}\left(1-P_{n}\right) \mathbf{x}_{n} \end{aligned}
∂w∂Pn=∂(1+exp(−w⊤xn))∂(1+exp(−w⊤xn))−1∂w∂(1+exp(−w⊤xn))exp(−w⊤xn)(−xn)=−(1+exp(−w⊤xn))21xn=(1+exp(−w⊤xn))2exp(−w⊤xn)xn=1+exp(−w⊤xn)11+exp(−w⊤x)exp(−w⊤xn)xn=Pn(1−Pn)xn
有:
log
g
(
w
;
X
,
t
)
=
log
p
(
w
∣
σ
2
)
+
∑
n
=
1
N
log
P
n
t
n
+
log
(
1
−
P
n
)
1
−
t
n
=
−
D
2
log
2
π
−
D
log
σ
−
1
2
σ
2
w
⊤
w
+
∑
n
=
1
N
t
n
log
P
n
+
(
1
−
t
n
)
log
(
1
−
P
n
)
\begin{aligned} \log g(\mathbf{w} ; \mathbf{X}, \mathbf{t}) &=\log p\left(\mathbf{w} \mid \sigma^{2}\right)+\sum_{n=1}^{N} \log P_{n}^{t_{n}}+\log \left(1-P_{n}\right)^{1-t_{n}} \\ &=-\frac{D}{2} \log 2 \pi-D \log \sigma-\frac{1}{2 \sigma^{2}} \mathbf{w}^{\top} \mathbf{w} \\ &+\sum_{n=1}^{N} t_{n} \log P_{n}+\left(1-t_{n}\right) \log \left(1-P_{n}\right) \end{aligned}
logg(w;X,t)=logp(w∣σ2)+n=1∑NlogPntn+log(1−Pn)1−tn=−2Dlog2π−Dlogσ−2σ21w⊤w+n=1∑NtnlogPn+(1−tn)log(1−Pn)
求一阶导数:
∂
log
g
(
w
;
X
,
t
)
∂
w
=
−
1
σ
2
w
+
∑
n
=
1
N
(
t
n
P
n
∂
P
n
∂
w
+
1
−
t
n
1
−
P
n
∂
(
1
−
P
n
)
∂
w
)
=
−
1
σ
2
w
+
∑
n
=
1
N
(
t
n
P
n
∂
P
n
∂
w
−
1
−
t
n
1
−
P
n
∂
P
n
∂
w
)
\begin{aligned} \frac{\partial \log g(\mathbf{w} ; \mathbf{X}, \mathbf{t})}{\partial \mathbf{w}} &=-\frac{1}{\sigma^{2}} \mathbf{w}+\sum_{n=1}^{N}\left(\frac{t_{n}}{P_{n}} \frac{\partial P_{n}}{\partial \mathbf{w}}+\frac{1-t_{n}}{1-P_{n}} \frac{\partial\left(1-P_{n}\right)}{\partial \mathbf{w}}\right) \\ &=-\frac{1}{\sigma^{2}} \mathbf{w}+\sum_{n=1}^{N}\left(\frac{t_{n}}{P_{n}} \frac{\partial P_{n}}{\partial \mathbf{w}}-\frac{1-t_{n}}{1-P_{n}} \frac{\partial P_{n}}{\partial \mathbf{w}}\right) \end{aligned}
∂w∂logg(w;X,t)=−σ21w+n=1∑N(Pntn∂w∂Pn+1−Pn1−tn∂w∂(1−Pn))=−σ21w+n=1∑N(Pntn∂w∂Pn−1−Pn1−tn∂w∂Pn)
带入
∂
P
n
∂
w
\frac{\partial P_{n}}{\partial \mathbf{w}}
∂w∂Pn,有:
∂
log
g
(
w
;
X
,
t
)
∂
w
=
−
1
σ
2
w
+
∑
n
=
1
N
(
x
n
t
n
(
1
−
P
n
)
−
x
n
(
1
−
t
n
)
P
n
)
=
−
1
σ
2
w
+
∑
n
=
1
N
x
n
(
t
n
−
t
n
P
n
−
P
n
+
t
n
P
n
)
=
−
1
σ
2
w
+
∑
n
=
1
N
x
n
(
t
n
−
P
n
)
\begin{aligned} \frac{\partial \log g(\mathbf{w} ; \mathbf{X}, \mathbf{t})}{\partial \mathbf{w}} &=-\frac{1}{\sigma^{2}} \mathbf{w}+\sum_{n=1}^{N}\left(\mathbf{x}_{n} t_{n}\left(1-P_{n}\right)-\mathbf{x}_{n}\left(1-t_{n}\right) P_{n}\right) \\ &=-\frac{1}{\sigma^{2}} \mathbf{w}+\sum_{n=1}^{N} \mathbf{x}_{n}\left(t_{n}-t_{n} P_{n}-P_{n}+t_{n} P_{n}\right) \\ &=-\frac{1}{\sigma^{2}} \mathbf{w}+\sum_{n=1}^{N} \mathbf{x}_{n}\left(t_{n}-P_{n}\right) \end{aligned}
∂w∂logg(w;X,t)=−σ21w+n=1∑N(xntn(1−Pn)−xn(1−tn)Pn)=−σ21w+n=1∑Nxn(tn−tnPn−Pn+tnPn)=−σ21w+n=1∑Nxn(tn−Pn)
二阶导数:
∂
2
log
g
(
w
;
X
,
t
)
∂
w
∂
w
T
=
−
1
σ
2
I
−
∑
n
=
1
N
x
n
∂
P
n
∂
w
T
=
−
1
σ
2
I
−
∑
n
=
1
N
x
n
x
n
⊤
P
n
(
1
−
P
n
)
\begin{aligned} \frac{\partial^{2} \log g(\mathbf{w} ; \mathbf{X}, \mathbf{t})}{\partial \mathbf{w} \partial \mathbf{w}^{\mathrm{T}}} &=-\frac{1}{\sigma^{2}} \mathbf{I}-\sum_{n=1}^{N} \mathbf{x}_{n} \frac{\partial P_{n}}{\partial \mathbf{w}^{\mathrm{T}}} \\ &=-\frac{1}{\sigma^{2}} \mathbf{I}-\sum_{n=1}^{N} \mathbf{x}_{n} \mathbf{x}_{n}^{\top} P_{n}\left(1-P_{n}\right) \end{aligned}
∂w∂wT∂2logg(w;X,t)=−σ21I−n=1∑Nxn∂wT∂Pn=−σ21I−n=1∑Nxnxn⊤Pn(1−Pn)
注意到,我们此时令一阶导数等于0是不能计算出
w
w
w的,因为
P
n
P_n
Pn的分布中有
e
−
w
T
x
e^{-w^{T}x}
e−wTx,是无法解析求解的超越方程,此时观察到二阶导数始终是负定的,则一阶导数为0时,后验取得最大值。我们可以用牛顿-拉佛森方法近似求解
w
w
w:
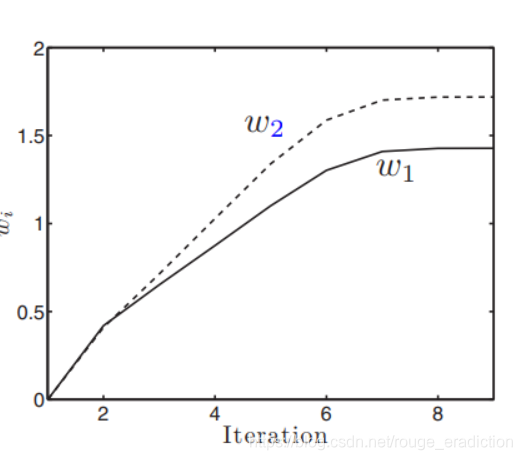
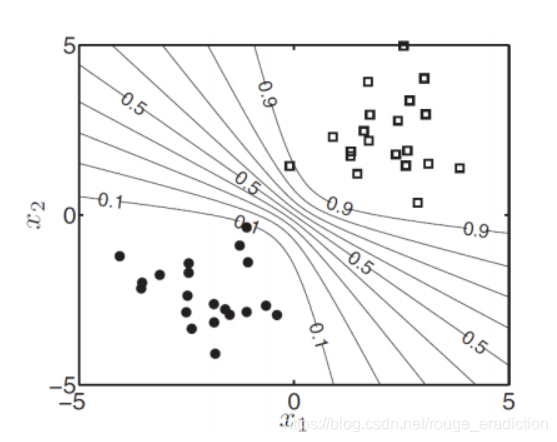
上图是计算机迭代的求解过程,得出结果后,我们可以设定:
- 当 P ( T n e w = 1 ∣ x n e w , w ^ ) > 0.5 P(T_{new} = 1|x_{new},\hat{\textbf{w}})>0.5 P(Tnew=1∣xnew,w^)>0.5,划分为正方形类。
- 当 P ( T n e w = 0 ∣ x n e w , w ^ ) > 0.5 P(T_{new} = 0|x_{new},\hat{\textbf{w}})>0.5 P(Tnew=0∣xnew,w^)>0.5,划分为圆形类
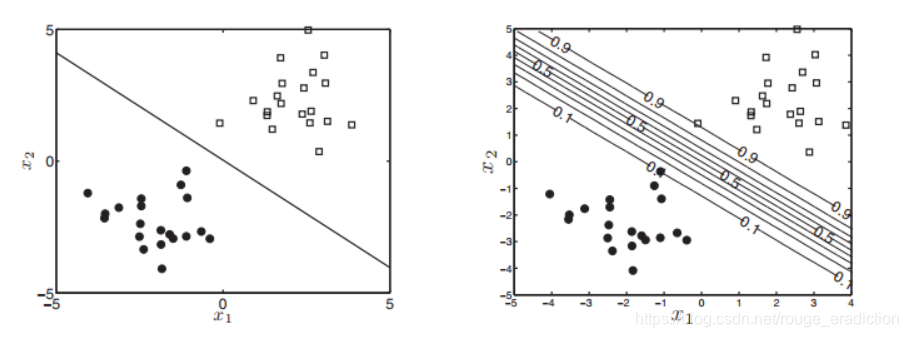
上图左是概率为0.5的决策边界,右边是对不同的概率画的斜线。
这种方法的优点是:
- 很容易找到参数的估计。
- 适用性很广,不管什么形式组合的先验和似然都可以通过这种方法求解。
缺点是:
- 我们很难知道我们通过牛顿法逼近求得的参数是不是全局的最优解。
第二种方法——拉普拉斯近似
拉普拉斯估计的基本思路是,用高斯分布来近似目标分布,即参数的后验分布。鉴于我们可以轻松操纵高斯分布(由于它仅有两个参数唯一确定),这似乎是一个明智的选择。但是,我们应该始终请记住,如果真实的分布确实是高斯分布,那我们的预测会和我们的近似值一样好。如果我们的真实后验不是很高斯,我们的预测将很容易计算但不是很准确。
由于在最大似然估计中我们已经计算出了
w
w
w的估计
w
^
\hat{w}
w^,所以我们只需要知道高斯分布的方差即可。
使用泰勒公式对其展开:
log
g
(
w
;
X
,
t
,
σ
2
)
≈
log
g
(
w
^
;
X
,
t
,
σ
2
)
+
∂
log
g
(
w
;
X
,
t
,
σ
2
)
∂
w
∣
w
^
(
w
−
w
^
)
1
!
+
∂
2
log
g
(
w
;
X
,
t
,
σ
2
)
∂
w
2
∣
w
^
(
w
−
w
^
)
2
2
!
+
…
\begin{aligned} \log g\left(w ; \mathbf{X}, \mathbf{t}, \sigma^{2}\right) & \approx \log g\left(\widehat{w} ; \mathbf{X}, \mathbf{t}, \sigma^{2}\right)+\left.\frac{\partial \log g\left(w ; \mathbf{X}, \mathbf{t}, \sigma^{2}\right)}{\partial w}\right|_{\widehat{w}} \frac{(w-\widehat{w})}{1 !} \\ &+\left.\frac{\partial^{2} \log g\left(w ; \mathbf{X}, \mathbf{t}, \sigma^{2}\right)}{\partial w^{2}}\right|_{\widehat{w}} \frac{(w-\widehat{w})^{2}}{2 !}+\ldots \end{aligned}
logg(w;X,t,σ2)≈logg(w
;X,t,σ2)+∂w∂logg(w;X,t,σ2)∣∣∣∣∣w
1!(w−w
)+∂w2∂2logg(w;X,t,σ2)∣∣∣∣∣w
2!(w−w
)2+…
在
w
^
\hat{w}
w^上,函数的一阶导数为0,二阶导数已经算出,下面我们将使用一种巧妙的数学技巧来近似计算用于拟合
log
g
(
w
;
X
,
t
,
σ
2
)
\log g\left(w ; \mathbf{X}, \mathbf{t}, \sigma^{2}\right)
logg(w;X,t,σ2)高斯分布的方差:
- 注意到虽然高斯分布可以写无穷多项,为了利用前两阶导数,我们只取泰勒展开的前三项。设:
v = − ∂ 2 log g ( w ; X , t , σ 2 ) ∂ w 2 ∣ w ^ v=-\left.\frac{\partial^{2} \log g\left(w ; \mathbf{X}, \mathbf{t}, \sigma^{2}\right)}{\partial w^{2}}\right|_{\hat{w}} v=−∂w2∂2logg(w;X,t,σ2)∣∣∣∣∣w^
可得:
log g ( w ; X , t , σ 2 ) ≈ log g ( w ^ ; X , t , σ 2 ) − v 2 ( w − w ^ ) 2 \log g\left(w ; \mathbf{X}, \mathbf{t}, \sigma^{2}\right) \approx \log g\left(\widehat{w} ; \mathbf{X}, \mathbf{t}, \sigma^{2}\right)-\frac{v}{2}(w-\widehat{w})^{2} logg(w;X,t,σ2)≈logg(w ;X,t,σ2)−2v(w−w )2 - 对于高斯分布的密度:
1 2 π σ exp { − ( w − μ ) 2 2 σ 2 } \frac{1}{\sqrt{2\pi}\sigma}\exp{\{-\frac{(w-\mu)^2}{2\sigma^2}\}} 2πσ1exp{−2σ2(w−μ)2}
取对数:
log ( K ) − 1 2 σ 2 ( w − μ ) 2 \log (K)-\frac{1}{2 \sigma^{2}}(w-\mu)^{2} log(K)−2σ21(w−μ)2
l o g ( K ) log(K) log(K)是常数。 - 与上面的泰勒展开同次数项对应相等。有:
μ = w ^ , Σ − 1 = − ( ∂ 2 log g ( w ; X , t ) ∂ w ∂ w ⊤ ) ∣ w ^ \boldsymbol{\mu}=\widehat{\mathbf{w}}, \quad \mathbf{\Sigma}^{-1}=-\left.\left(\frac{\partial^{2} \log g(\mathbf{w} ; \mathbf{X}, \mathbf{t})}{\partial \mathbf{w} \partial \mathbf{w}^{\top}}\right)\right|_{\widehat{\mathbf{w}}} μ=w ,Σ−1=−(∂w∂w⊤∂2logg(w;X,t))∣∣∣∣w
则有:
p ( w ∣ X , t , σ 2 ) ≈ N ( μ , Σ ) p\left(\mathbf{w} \mid \mathbf{X}, \mathbf{t}, \sigma^{2}\right) \approx \mathcal{N}(\boldsymbol{\mu}, \mathbf{\Sigma}) p(w∣X,t,σ2)≈N(μ,Σ)
现在我们需要讨论的是,为什么对
log
g
(
w
;
X
,
t
,
σ
2
)
\log g\left(w ; \mathbf{X}, \mathbf{t}, \sigma^{2}\right)
logg(w;X,t,σ2)的泰勒展开可以估计
p
(
w
∣
X
,
t
,
σ
2
)
p\left(\mathbf{w} \mid \mathbf{X}, \mathbf{t}, \sigma^{2}\right)
p(w∣X,t,σ2),首先根据拉普拉斯估计的假设,或者说是好处,我们假设后验的真实分布是高斯分布,并且均值是
w
^
\hat{w}
w^,所以为了达到目的,我们只需要计算方差就可以了。此时
log
g
(
w
;
X
,
t
,
σ
2
)
\log g\left(w ; \mathbf{X}, \mathbf{t}, \sigma^{2}\right)
logg(w;X,t,σ2)与后验的差距在于前者没有加上分母即边缘,因为分母是与参数
w
w
w无关的常数,所以在对
g
(
w
;
X
,
t
,
σ
2
)
g\left(w ; \mathbf{X}, \mathbf{t}, \sigma^{2}\right)
g(w;X,t,σ2)取对数之后分母变成了常数项,同时在对后验取对数的时候,我们同样产生了常数项
log
(
K
)
\log(K)
log(K)。不考虑与
w
w
w无关的常数,
w
2
w^2
w2的项对应相等,这是正确的,合理的。 需要注意的是,在多维的情况下,协方差矩阵的逆等于黑森矩阵。
可惜的是,尽管我们使用高斯分布去拟合后验的分布我们还是不能准确的求出估计在后验上的期望:
p
(
T
new
=
1
∣
x
new
,
X
,
t
,
σ
2
)
=
E
N
(
μ
,
Σ
)
{
P
(
T
new
=
1
∣
x
new
,
W
)
}
p\left(T_{\text {new }}=1 \mid \mathrm{x}_{\text {new }}, \mathrm{X}, \mathrm{t}, \sigma^{2}\right)=E_{N(\mu, \Sigma)}\left\{P\left(T_{\text {new }}=1 \mid \mathrm{x}_{\text {new }}, \mathrm{W}\right)\right\}
p(Tnew =1∣xnew ,X,t,σ2)=EN(μ,Σ){P(Tnew =1∣xnew ,W)}
这是由于
w
w
w服从正太分布
N
(
μ
,
Σ
)
N(\mu, \mathbf{\Sigma})
N(μ,Σ),要求:
E
(
s
i
g
m
o
i
d
(
x
n
e
w
)
)
=
E
(
1
−
exp
{
−
w
T
x
n
e
w
}
)
=
∫
P
(
T
new
=
1
∣
x
new
,
w
)
p
(
w
∣
X
,
t
,
σ
2
)
d
w
=
∫
1
2
π
Σ
exp
{
−
(
w
−
w
^
)
2
2
Σ
T
Σ
}
1
−
exp
{
−
w
T
x
n
e
w
}
d
w
E(sigmoid(x_{new})) = E(\frac{1}{-\exp{\{-w^Tx_{new}\}}}) \\ = \int P\left(T_{\text {new }}=1 \mid \mathbf{x}_{\text {new }}, \mathbf{w}\right) p\left(\mathbf{w} \mid \mathbf{X}, \mathbf{t}, \sigma^{2}\right) d \mathbf{w} \\ = \int \frac{1}{\sqrt{2\pi}\mathbf{\Sigma}}\exp{\{-\frac{(w-\hat{w})^2}{2\mathbf{\Sigma}^T\mathbf{\Sigma}}\}}\frac{1}{-\exp{\{-w^Tx_{new}\}}}dw
E(sigmoid(xnew))=E(−exp{−wTxnew}1)=∫P(Tnew =1∣xnew ,w)p(w∣X,t,σ2)dw=∫2πΣ1exp{−2ΣTΣ(w−w^)2}−exp{−wTxnew}1dw
没法积分,我们只能在求得高斯分布上取点求平均作为对期望的估计:
P
(
T
new
=
1
∣
x
new
,
X
,
t
,
σ
2
)
=
1
N
s
∑
s
=
1
N
s
1
1
+
exp
(
−
w
s
⊤
x
new
)
P\left(T_{\text {new }}=1 \mid \mathbf{x}_{\text {new }}, \mathbf{X}, \mathbf{t}, \sigma^{2}\right)=\frac{1}{N_{s}} \sum_{s=1}^{N_{s}} \frac{1}{1+\exp \left(-\mathbf{w}_{s}^{\top} \mathbf{x}_{\text {new }}\right)}
P(Tnew =1∣xnew ,X,t,σ2)=Ns1s=1∑Ns1+exp(−ws⊤xnew )1
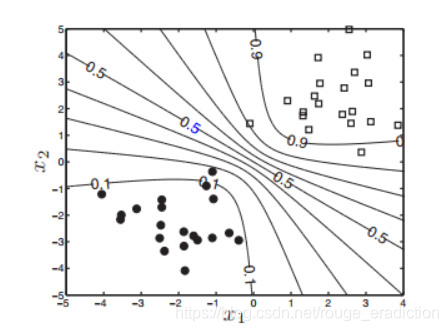
上图是拉普拉斯估计得到的边界图,显然与MAP估计相比,不同概率的决策边界不再是直线,这从直观上要更合理一些,但是本方法也存在一些缺点:
12. 近似的步骤太多,包括求
w
^
\hat{w}
w^本身是使用牛顿法近似,泰勒展开忽略了后面的残差项,用高斯分布近似后验等等。导致最后求得的参数不准确。
13. 待探索
第三种方法——抽样方法
通过第二种方法我们知道,即使我们得到了后验的近似,我们也难以直接积分计算期望:
p
(
T
new
=
1
∣
x
new
,
X
,
t
,
σ
2
)
=
E
N
(
μ
,
Σ
)
{
P
(
T
new
=
1
∣
x
new
,
W
)
}
p\left(T_{\text {new }}=1 \mid \mathrm{x}_{\text {new }}, \mathrm{X}, \mathrm{t}, \sigma^{2}\right)=E_{N(\mu, \Sigma)}\left\{P\left(T_{\text {new }}=1 \mid \mathrm{x}_{\text {new }}, \mathrm{W}\right)\right\}
p(Tnew =1∣xnew ,X,t,σ2)=EN(μ,Σ){P(Tnew =1∣xnew ,W)}
所幸我们可以通过得到的分布抽样,但是这样未免太过拐弯抹角,我们想直接跳过近似的过程直接抽样,来计算:
p
(
T
new
=
1
∣
x
new
,
X
,
t
,
σ
2
)
=
E
N
(
μ
,
Σ
)
{
P
(
T
new
=
1
∣
x
new
,
W
)
}
=
∫
P
(
T
new
=
1
∣
x
new
,
w
)
p
(
w
∣
X
,
t
,
σ
2
)
d
w
p\left(T_{\text {new }}=1 \mid \mathrm{x}_{\text {new }}, \mathrm{X}, \mathrm{t}, \sigma^{2}\right)=E_{N(\mu, \Sigma)}\left\{P\left(T_{\text {new }}=1 \mid \mathrm{x}_{\text {new }}, \mathrm{W}\right)\right\}\\ = \int P\left(T_{\text {new }}=1 \mid \mathbf{x}_{\text {new }}, \mathbf{w}\right) p\left(\mathbf{w} \mid \mathbf{X}, \mathbf{t}, \sigma^{2}\right) d \mathbf{w}
p(Tnew =1∣xnew ,X,t,σ2)=EN(μ,Σ){P(Tnew =1∣xnew ,W)}=∫P(Tnew =1∣xnew ,w)p(w∣X,t,σ2)dw
并且
P
(
T
=
1
∣
x
new
,
X
,
t
,
σ
2
)
≃
1
N
s
∑
−
0
N
s
P
(
T
new
=
1
∣
x
new
,
w
s
)
P\left(T=1 \mid \mathbf{x}_{\text {new }}, \mathbf{X}, \mathbf{t}, \sigma^{2}\right) \simeq \frac{1}{N_{s}} \sum_{-0}^{N_{s}} P\left(T_{\text {new }}=1 \mid \mathbf{x}_{\text {new }}, \mathbf{w}_{s}\right)
P(T=1∣xnew ,X,t,σ2)≃Ns1−0∑NsP(Tnew =1∣xnew ,ws)
下面我们介绍Metropolis-Hastings算法,该算法期望生成一系列
w
i
w_i
wi,直到收敛到一个合适的
w
w
w。方法如下:
对上一个抽样样本
w
s
−
1
w_{s-1}
ws−1,我们以一定的步幅生成
w
s
w_{s}
ws:
p
(
w
~
s
∣
w
s
−
1
,
Σ
)
=
N
(
w
s
−
1
,
Σ
)
p\left(\tilde{\mathbf{w}}_{\mathrm{s}} \mid \mathbf{w}_{\mathrm{s}-1}, \Sigma\right)=N\left(\mathbf{w}_{\mathrm{s}-1}, \Sigma\right)
p(w~s∣ws−1,Σ)=N(ws−1,Σ)
这个过程称作随机游走,方差
Σ
\Sigma
Σ就是游走的步幅。然后我们要判断这个新生成的
w
s
w_{s}
ws是否能够使用:
首先计算如下的比例
r
r
r:
r
=
p
(
w
~
s
∣
X
,
t
,
σ
2
)
p
(
w
s
−
1
∣
X
,
t
,
σ
2
)
p
(
w
s
−
1
∣
w
~
s
,
Σ
)
p
(
w
~
s
∣
w
s
−
1
,
Σ
)
=
g
(
w
~
s
;
X
,
t
,
σ
2
)
g
(
w
s
−
1
;
X
,
t
,
σ
2
)
=
p
(
w
~
s
∣
σ
2
)
p
(
w
s
−
1
∣
σ
2
)
p
(
t
∣
w
~
s
,
X
)
p
(
t
∣
w
s
−
1
,
X
)
\begin{aligned} r &=\frac{p\left(\tilde{\mathrm{w}}_{\mathrm{s}} \mid \mathrm{X}, \mathrm{t}, \sigma^{2}\right)}{p\left(\mathrm{w}_{\mathrm{s}-1} \mid \mathrm{X}, \mathrm{t}, \sigma^{2}\right)} \frac{p\left(\mathrm{w}_{\mathrm{s}-1} \mid \tilde{\mathrm{w}}_{\mathrm{s}}, \Sigma\right)}{p\left(\tilde{\mathrm{w}}_{\mathrm{s}} \mid \mathrm{w}_{\mathrm{s}-1}, \Sigma\right)} \\ &=\frac{g\left(\tilde{\mathrm{w}}_{\mathrm{s}} ; \mathrm{X}, \mathrm{t}, \sigma^{2}\right)}{g\left(\mathrm{w}_{\mathrm{s}-1} ; \mathrm{X}, \mathrm{t}, \sigma^{2}\right)}=\frac{p\left(\tilde{\mathrm{w}}_{\mathrm{s}} \mid \sigma^{2}\right)}{p\left(\mathrm{w}_{\mathrm{s}-1} \mid \sigma^{2}\right)} \frac{p\left(\mathrm{t} \mid \tilde{\mathrm{w}}_{\mathrm{s}}, \mathrm{X}\right)}{p\left(\mathrm{t} \mid \mathrm{w}_{\mathrm{s}-1}, \mathrm{X}\right)} \end{aligned}
r=p(ws−1∣X,t,σ2)p(w~s∣X,t,σ2)p(w~s∣ws−1,Σ)p(ws−1∣w~s,Σ)=g(ws−1;X,t,σ2)g(w~s;X,t,σ2)=p(ws−1∣σ2)p(w~s∣σ2)p(t∣ws−1,X)p(t∣w~s,X)
由于所有的变量都已知,上式可以显式计算。
不难理解由于对称性:
p
(
w
s
−
1
∣
w
~
s
,
Σ
)
p
(
w
~
s
∣
w
s
−
1
,
Σ
)
=
1
\frac{p\left(\mathrm{w}_{\mathrm{s}-1} \mid \tilde{\mathrm{w}}_{\mathrm{s}}, \Sigma\right)}{p\left(\tilde{\mathrm{w}}_{\mathrm{s}} \mid \mathrm{w}_{\mathrm{s}-1}, \Sigma\right)} =1
p(w~s∣ws−1,Σ)p(ws−1∣w~s,Σ)=1
你可能很好奇为什么对两个后验之比能够转化为
g
(
w
~
s
;
X
,
t
,
σ
2
)
g
(
w
s
−
1
;
X
,
t
,
σ
2
)
\frac{g\left(\tilde{\mathrm{w}}_{\mathrm{s}} ; \mathrm{X}, \mathrm{t}, \sigma^{2}\right)}{g\left(\mathrm{w}_{\mathrm{s}-1} ; \mathrm{X}, \mathrm{t}, \sigma^{2}\right)}
g(ws−1;X,t,σ2)g(w~s;X,t,σ2)之比,这是由于在贝叶斯定理中,等式右边的分母与
w
w
w无关只与
X
,
t
,
σ
2
\mathbf{X},t,\sigma^2
X,t,σ2有关,所以可以消掉。计算之后按照:
- 如果 r > = 1 r>=1 r>=1,则 w s = w ~ s \mathrm{w}_s = \tilde{\mathrm{w}}_s ws=w~s,接受 w ~ s \tilde{\mathrm{w}}_s w~s。
- 如果 r < 1 r<1 r<1,则依概率接受,按照均匀分布随机产生一个 u u u,如果 r > = u r>=u r>=u,则接受;泛指则不接受。
如果抽样的数量足够多,我们就可以依据抽样的结果估计后验的分布,就是通过样本的平均值作为其期望的估计。下面我们论述MH算法的可行性:
首先要明白我们的目的不是求出最大的后验,而是依概率逼近整个后验的分布。因此MH算法采用了控低不控高的做法,详细来说,当
w
s
w_s
ws漂移时,如果后验大,则接受,即不对大的进行控制;如果小则要依概率进行控制,使得抽烟的结构较为符合计算得到的后验之比。从而在足够多的样本之后可以得到逼近后验的分布。
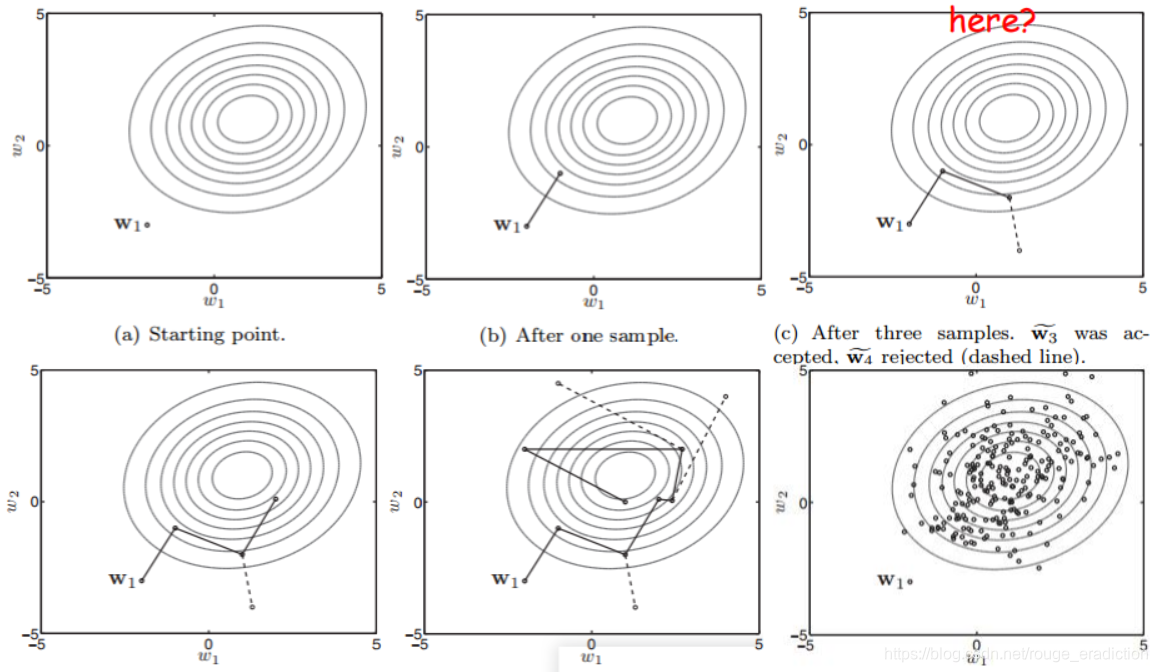
使用该算法解决二值响应问题:
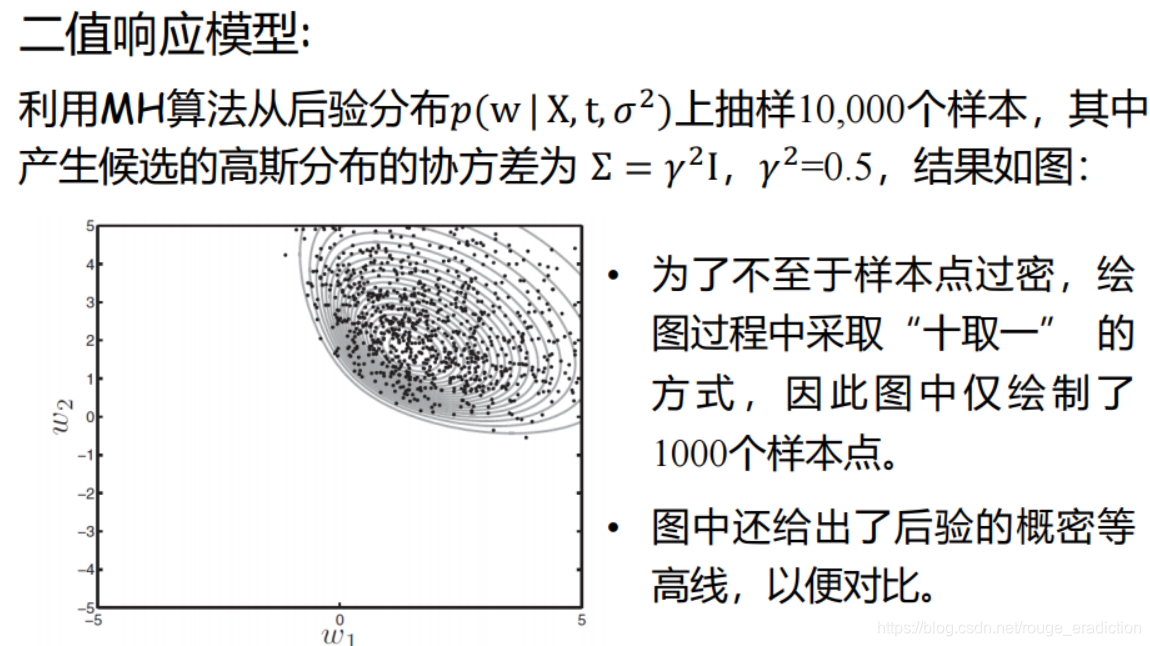
最后结果:
总结
当我们学习完贝叶斯方法,贝叶斯定理,朴素贝叶斯分类器之后,我们再回想一下贝叶斯方法的好处:
它提供了显式表达先验和后继样本输入的方法。先验数据就是我们已经知道的标签的数据,它通过先验函数体现,先验函数的构造,参数的获取本身也是一个学习的过程,是对所有已知样本学习的结果。理解先验对理解贝叶斯方法十分重要。
对于不同的问题,对所有已知样本的学习方式(先验的计算方法)是不同的:
第一抛硬币问题
似然满足二项分布,在计算后验时,有:
p
(
r
∣
y
N
)
=
P
(
y
N
∣
r
)
p
(
r
)
P
(
y
N
)
p\left(r \mid y_{N}\right)=\frac{P\left(y_{N} \mid r\right) p(r)}{P\left(y_{N}\right)}
p(r∣yN)=P(yN)P(yN∣r)p(r)
P
(
y
N
∣
r
)
=
[
(
N
y
N
)
r
y
N
(
1
−
r
)
N
−
y
N
]
P\left(y_{N} \mid r\right)=\left[\left(\begin{array}{c} N \\ y_{N} \end{array}\right) r^{y_{N}}(1-r)^{N-y_{N}}\right]
P(yN∣r)=[(NyN)ryN(1−r)N−yN]
在抛硬币中,已知抛了
N
N
N次,有
y
n
y_n
yn正面朝上,后验表示为二项分布取
y
n
y_n
yn的概率。
第二二值响应问题
为了得到统一的后验,将
t
n
t_n
tn的两种取值情况统一在一起:
p
(
t
∣
X
,
w
)
=
∏
n
=
1
N
P
(
T
n
=
1
∣
x
n
w
)
t
n
P
(
T
n
=
0
∣
x
n
,
w
)
1
−
t
n
=
∏
n
=
1
N
(
1
1
+
exp
(
−
w
⊤
x
n
)
)
t
n
(
exp
(
−
w
⊤
x
n
)
1
+
exp
(
−
w
⊤
x
n
)
)
1
−
t
n
\begin{aligned} p(\mathbf{t} \mid \mathbf{X}, \mathbf{w}) &=\prod_{n=1}^{N} P\left(T_{n}=1 \mid \mathbf{x}_{n} \mathbf{w}\right)^{t_{n}} P\left(T_{n}=0 \mid \mathbf{x}_{n}, \mathbf{w}\right)^{1-t_{n}} \\ &=\prod_{n=1}^{N}\left(\frac{1}{1+\exp \left(-\mathbf{w}^{\top} \mathbf{x}_{n}\right)}\right)^{t_{n}}\left(\frac{\exp \left(-\mathbf{w}^{\top} \mathbf{x}_{n}\right)}{1+\exp \left(-\mathbf{w}^{\top} \mathbf{x}_{n}\right)}\right)^{1-t_{n}} \end{aligned}
p(t∣X,w)=n=1∏NP(Tn=1∣xnw)tnP(Tn=0∣xn,w)1−tn=n=1∏N(1+exp(−w⊤xn)1)tn(1+exp(−w⊤xn)exp(−w⊤xn))1−tn
已知所有点的分类,将所有的似然值乘在一起。
第三文本分类问题
在文本分类的问题中,我们已知的标签数据是十万条已经被分好类的新闻,我们要估计的参数似乎不是那么明显,实际上我们要估计的参数是每一类新闻的词概率向量
q
\mathbf{q}
q。由于新闻的分类有20类,这样就不能用像在二值响应问题中使用数学技巧将它们写在一起了,我们的处理方式是对每一类新闻都求参数
q
\mathbf{q}
q。写出每一类的似然函数:
L
=
∏
n
=
1
N
c
P
(
X
n
=
x
n
)
=
∏
n
=
1
N
c
[
(
S
n
!
∏
m
=
1
M
x
n
m
!
)
∏
m
=
1
M
q
m
x
n
m
]
L=\prod_{n=1}^{N_c}P(X_n=\mathbf{x}_n)=\prod_{n=1}^{N_c}[(\frac{S_n !}{\prod_{m=1}^{M} x_{nm} !}) \prod_{m=1}^{M} q_{m}^{x_{nm}}]
L=n=1∏NcP(Xn=xn)=n=1∏Nc[(∏m=1Mxnm!Sn!)m=1∏Mqmxnm]
这里的
x
n
\mathbf{x}_n
xn是指的某一类(假设是
c
c
c)的所有新闻的文本向量。自然,这里的
N
c
N_c
Nc指的是
c
c
c类的新闻的数量。
为了求解参数我们使用了两种方法,第一是最大似然方法,第二是贝叶斯方法。这给了在机器学习中挣扎的我们很重要的启示。似乎所有的能使用贝叶斯方法求参数的问题,都可以基于似然使用最大似然方法求解。比如抛硬币的问题,我们就可以将点估计
r
=
y
N
N
r=\frac{y_N}{N}
r=NyN作为我们对参数的估计。第二,你可能现在对贝叶斯方法中“一切皆随机”有了新的认识,不同于最大似然估计中将参数视为静止不变的量,贝叶斯方法中,增加了能动的可能。
这个能动似乎就是指后继的数据,那么后继的数据是如何在贝叶斯定理中发挥作用的呢?

















 8389
8389

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









