




 本文介绍了约束型策略优化(CPO),一种在强化学习中确保智能体在训练过程中满足安全约束的算法。CPO通过近似强制执行约束条件,使智能体的学习不会超出预设的成本限制。实验表明,CPO在多个任务中能有效学习策略并保持约束的近似满足。
本文介绍了约束型策略优化(CPO),一种在强化学习中确保智能体在训练过程中满足安全约束的算法。CPO通过近似强制执行约束条件,使智能体的学习不会超出预设的成本限制。实验表明,CPO在多个任务中能有效学习策略并保持约束的近似满足。
如有错误,欢迎指正
本文翻译为机翻,仅作初步了解学习使用,需要用到的时候再回来整理。
如有侵权,请私信本人。
约束型策略优化算法
Joshua Achiam(UC Berkeley)
原为链接:https://arxiv.org/pdf/1705.10528.pdf
参考链接:https://www.sohu.com/a/155588306_465975
源码:https://github.com/jachiam/cpo
我们的方法——约束型策略优化(Constrained Policy Optimization——CPO),可以确保智能体在学习过程中的每一步都满足约束条件。具体来说,我们尝试满足成本方面的约束:设计者会给智能体应该避免的每一个结果都分配一个成本(cost)和一个限制(limit),而且智能体则会学着去使它的所有成本都保持在限制之下。
为什么我们需要安全性约束?
强化学习智能体的训练目标是最大化奖励信号,人类必须事先指定设计这一过程的范围。如果奖励信号没有被正确设计,智能体就会去学习非计划中的甚至是有害的行为。如果设计奖励函数很容易,这将不是问题,但不幸的是从根本上来讲,奖励函数设计很有挑战性;这就是采用约束(constraint)的关键动机所在。
CPO:约束型强化学习的本地策略搜索
CPO 是一个用于约束型强化学习的信任区域方法,它在每一次策略更新中都近似地强制执行约束条件。它使用约束的近似值来预测,在任意给定的更新之后,约束成本会改变多少,接着选择会最大化提升性能并能够将约束成本保持在其限制之下的更新方式。
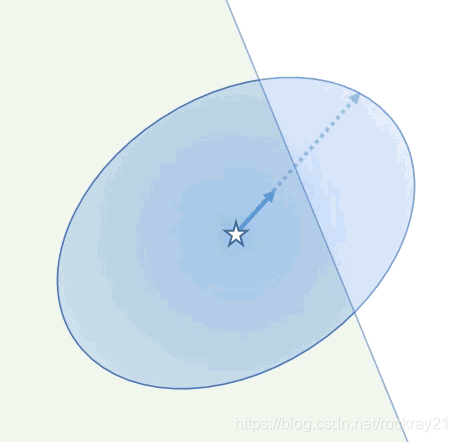
我们也有一些不错的理论成果来补足实践的算法:我们推导出了一个平均 KL -散度近似值质量的新界限。这使得我们得以证明一般性信任区域方法有效性,解释了其效果有多好,并使我们确定了在 CPO 更新之后有可能发生的约束违规的下限。

关于实际性能:我们发现 CPO 卓有成效。同时在圆圈任务(上文已讨论)和一个更复杂的收集任务中(其中智能体要收集绿色苹果,并被约束以避开红色炸弹),CPO 学到了很好的策略,并在整个训练中都近似地满足约束。
摘要:
我们提出了约束策略优化(CPO),这是第一个用于约束强化学习的通用策略搜索算法,在每次迭代中保证近似约束满足。我们证明了两种策略的预期收益与它们之间的平均差异之间的关系。
introduction
解决了高维连续控制的约束问题
与以前的工作相比,我们的方法是CMDPs的第一个策略搜索算法,它1)在整个训练过程中保证约束满足,2)适用于任意策略类(包括神经网络)。
algorithm
下面的算法是用近似的方法给出了求解过程,核心还是要求解式(10)
将目标的梯度表示为g,约束i的梯度表示为bi,KL散度的Hessian表示为H,并定义ci= Jci(πk)-di

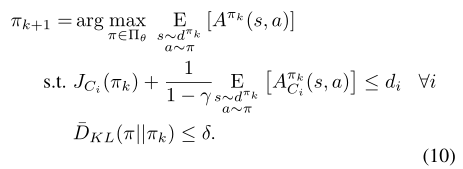
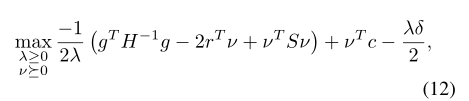
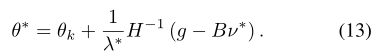
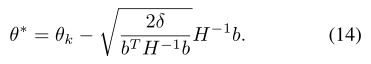
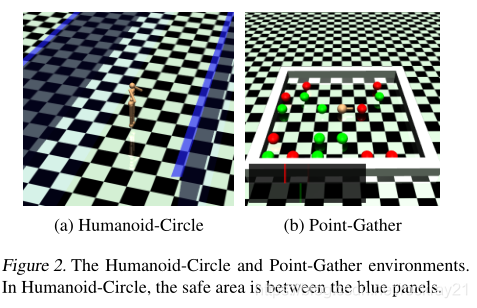
experiment
跑操场,躲着炸弹吃苹果
结果:
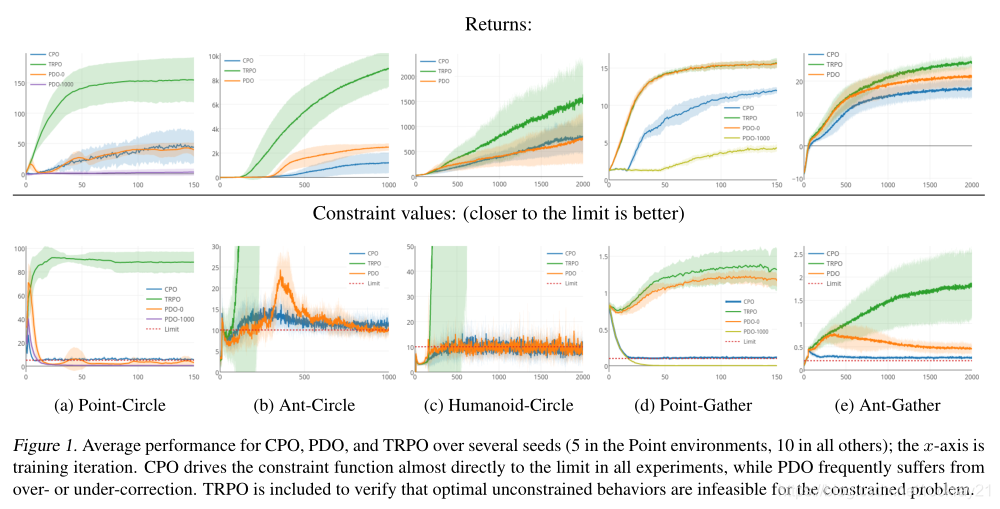
TRPO用来证明环境的最优无约束行为是违法约束的。
CDO和PDO的核心区别是更新方式,PDO无法保证中间策略满足约束条件。

















 587
587

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









