






 论文提出TransCAM模型,通过Transformer的注意力权重细化CNN的类激活映射,解决弱监督分割中对象部分激活的问题。TransCAM结合Conformer网络,利用Transformer的全局特性改进CAM生成,提高伪标签的质量,从而提升弱监督语义分割的性能。
论文提出TransCAM模型,通过Transformer的注意力权重细化CNN的类激活映射,解决弱监督分割中对象部分激活的问题。TransCAM结合Conformer网络,利用Transformer的全局特性改进CAM生成,提高伪标签的质量,从而提升弱监督语义分割的性能。
分享一篇阅读的用于弱监督分割的论文
论文标题:
TransCAM: Transformer Attention-based CAM Refinement for Weakly Supervised Semantic Segmentation
作者信息:

代码地址:
https://github.com/liruiwen/TransCAM
Abstract
大多数现有的WSSS方法都是基于类激活映射(CAM)来生成像素级的伪标签,用于监督训练。但是基于CNN的WSSS方法只是凸出最具有区别性的地方,即CAM部分激活而不是整体对象。作者提出了TransCAM模型,它基于Conforme的backbone结构,利用transformer的attention权重来细化CNN分支的CAM。
Introduction
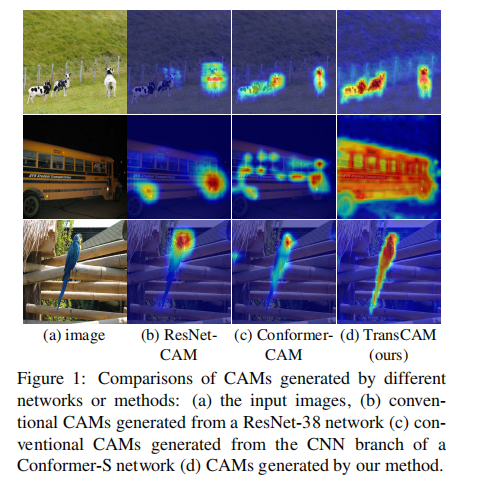
现有的方法: 基于CNN训练分类网络的激活CAM,然后训练一个完整的监督网络。
现有方法的缺点:主要是部分激活问题,由类模型生成的CAM倾向于突出对象中最具区别性的部分而不是整体(如图1所示)。作者认为这个根本是CNN造成的,它的局部性质的接受阈只捕获小范围的特征依赖性。(就是说CNN还是感受野小了,偏向Local).
作者的motivation: 和CNN相比,Transformer更加具备整体性,利用多头自注意和多层感知器来捕获远程语义关联。并且Transformer不太注重局部细节信息,这都比较利好WSSS任务。
作者的方法: 使用Conformer作为主干网络(一种结合CNN和Transformer的结构)。原本的Conformer仅仅通过隐形的方式(FCU结构)对transformer分支的注意力权重进行调整,导致WSSS任务表现不佳。作者提出了TransCAM模型,直接利用transformer的注意力权重微调cnn分支生成CAM。另外Transformer也跟CNN类似,低层次block和高层次block各有其特点,具体方法上,作者通过对所有的多头注意力权重值进行平均,进而构建同时embedding低level和高level特征affinity的注意图。
Methodology
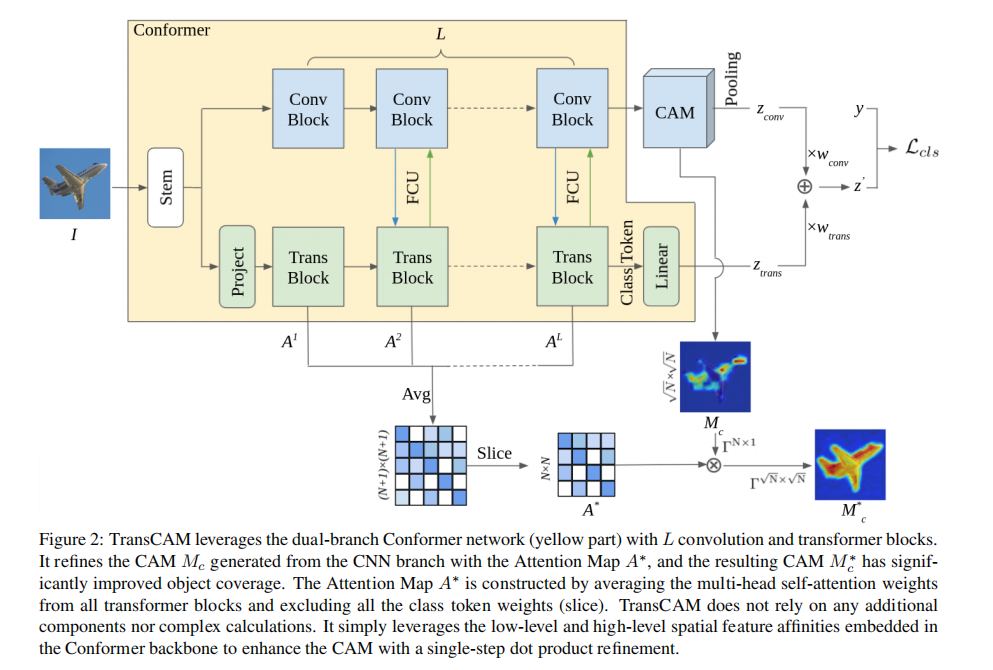
3.1. Preliminaries
The Conformer network: 一个由CNN和trasformer组成的双主干网络(主要结构见figure2红色部分),上方是resnet,下方是vit,中间通过FCU模块继进行连接。
Class Activation Map: 常规的CAM方法,计算公式如下:
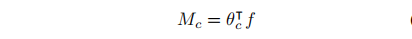
3.2. CAM Generation from Conformer
先通过CNN的分支,获得初始的CAM,记为
M
M
M。
(作者分析了这种CAM比一般的单backbone的强,因为有transformer分支提供的fcn进行隐形的调节,没有充分利用注意权重的特征亲和信息进行定位。
3.3. Attention Map Generation
首先计算第
l
l
l层transformer block的attention权重,公式如下:

其实就是Q跟K的点集加上softmax(常规attention计算中,除了v的其他部分),然后在这个基础上,对每个head取平均值,然后再在多个transformer block上也求平均值(浅层block和深层block都一起算)
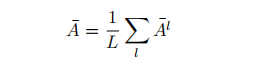
同时这里剔除transformer中的cls token,因为后面用不到,即:
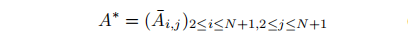
3.4. Attention-based CAM refinement
利用前面计算的attention权重,对初始的CAM进行refine。利用矩阵的乘法即可:
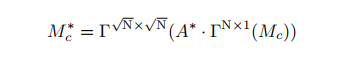
后面这个操作是reshape,让feature map重塑到相当的尺寸。
3.5 Training and Pseudo Label Generation
模型的分类的logits是由cnn分支和transformer分支共同作用输出的(见figrue2),即:
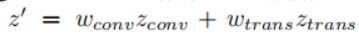
模型仅有分类损失函数,计算方法为:
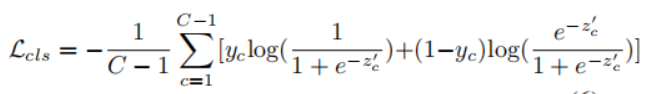
其余设置和常规的WSSS任务一样,给背景手动设置score:
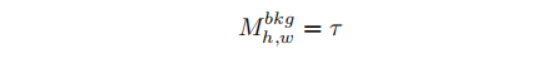
使用argmax获得伪标签:
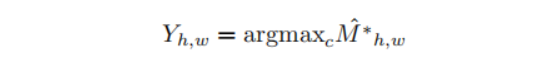
Experiments
消融实验


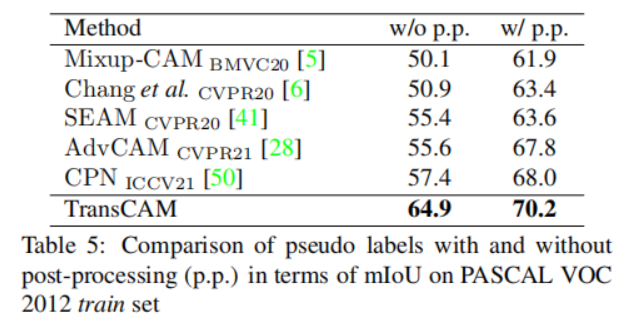
一阶段的结果:
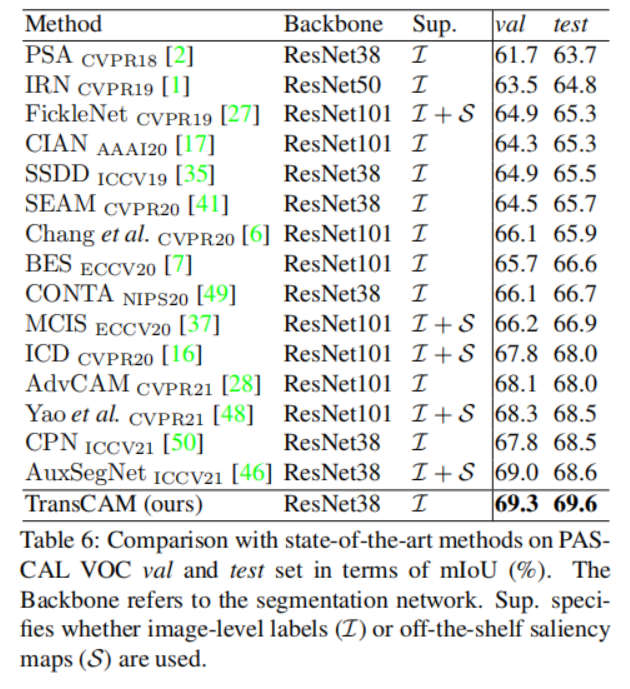
二阶段的结果:

















 6212
6212

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









