






一篇弱监督分割领域的论文,其会议版本为:
(ICCV2019)Integral Object Mining via Online Attention Accumulation
论文标题:
Online Attention Accumulation for Weakly Supervised Semantic Segmentation
作者信息:

代码地址:
https://github.com/PengtaoJiang/OAA
Abstract
1.在不同的训练阶段,网络对关注于目标的不同区域。基于此作者提出了Online Attention Accumulation(OAA)方法,利用不同阶段的训练注意力来获得更多完整的目标区域。
2.由于某些目标在训练阶段注意力的特征变化不大,作者在Online Attention Accumulation加入了attention drop层(相当于遮挡一部分),去"扩大"网络在训练过程中注意力的运动范围。
3.作者还使用了Attention Accumulation后的map辅助进行像素级label的训练,进一步帮助网络发现更多完整的目标区域。
Introduction

(相关工作及其缺点)
CAM具有发掘像素位置信息的能力,被广发用于WSSS领域,用于生成初始的class-specific object regions。但是原始的CAM通常集中于语义对象的一小部分,限制了分割网络学习更丰富的像素级语义知识的能力。
Adversarial erasing strategies等方法用于扩大discriminative regions,但是随着训练的进行,会使一些不希望的背景内容被误预测为语义区域。
(作者工作的motivation)前面的工作都只采用了最终的分类器模型来生成注意力,作者的工作则用到了训练的中间部分。
网络在不同的训练阶段,对于目标的注意力的区域(discriminative regions)总在改变的(如图1),直到网络收敛。主要原因是:
- 1.分类网络总是在寻找一些比较强的或者common的pattern,以保证所有图像都能够很好的被识别。但网络一般先会学习简单的pattern,后面随着训练的进行,再慢慢的学习比较难的pattern。那些难以正确分类的训练样本将驱动网络在选择common pattern时做出改变,导致 discriminative regions的持续移动,直到网络达到收敛。
- 2.在训练过程中,当前分类模型的attention map主要受到先前输入图像的影响。不同内容的图像和训练图像的输入顺序会导致训练过程中discriminative regions的变化。
(作者工作的总览)(和Abstract中基本一致,不写了):…
Methodology
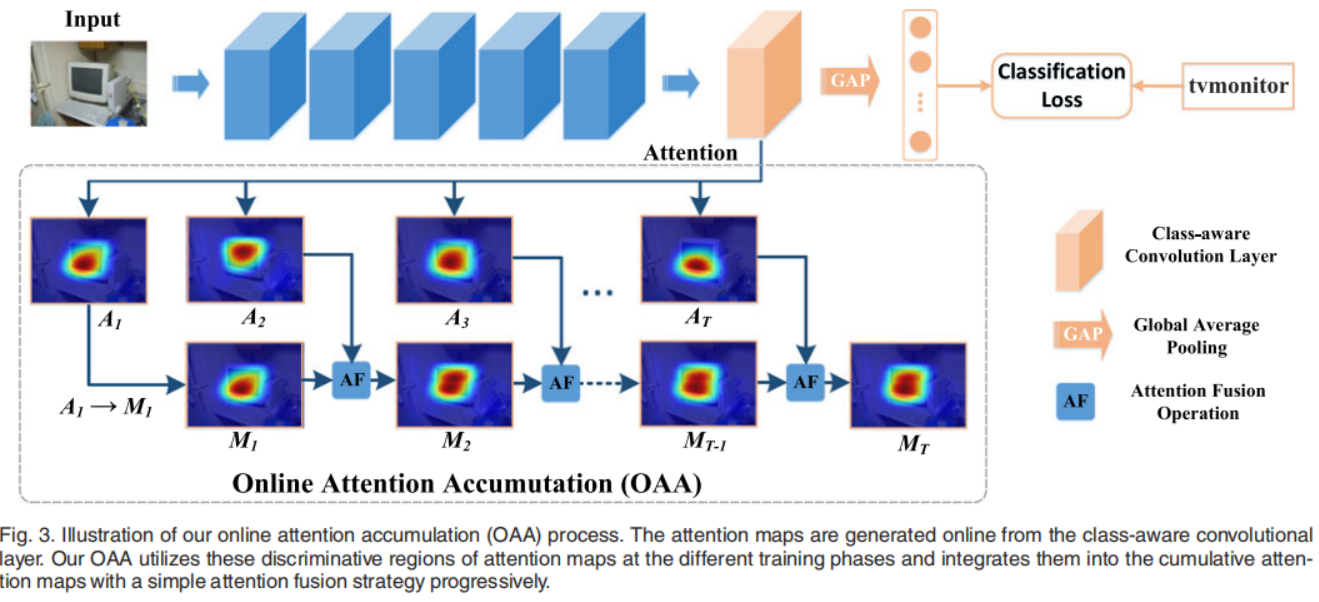
3.1 Attention Generation
(常规的生成CAM的方法)
backbone网络是VGG-16,在网络最终的attention层采用GAP获得class的类别
p
c
p^c
pc:
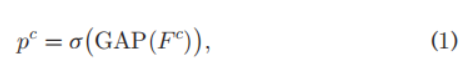
然后获得normlalize的CAM:
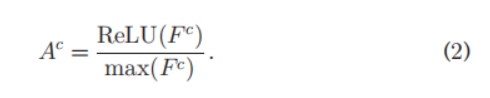
3.2 Online Attention Accumulation
作者提出了一种online attention accumulation(OAA)策略来在训练中充分利用attention map。OAA将在不同训练时期生成的任何训练图像的attention map累积成一个累积的attention map。
首先,根据开始训练(第一个epoch)生成的attention map
A
1
c
A_1^c
A1c,直接得到第一个cumulative attention map
M
1
c
M_1^c
M1c.(后面为例简化描述,省略了字母c)。
之后,当图像第二次输入网络时(第二个epoch),通过下列公式在
M
1
c
M_1^c
M1c和
A
2
c
A_2^c
A2c的基础上更新得到
M
2
c
M_2^c
M2c:
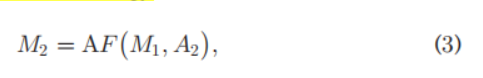
这里的
A
F
AF
AF是一种融合策略(attention fusion)。以此向下递归,对于每一个attention map
A
t
A_t
At,都使用上一个获得的cumulative attention map
M
t
−
1
M_{t-1}
Mt−1,生成
M
t
M_{t}
Mt,即:
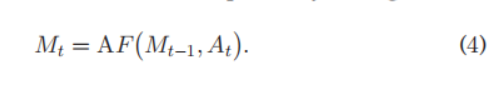
持续上述这个过程直到最终的训练网络收敛。
其中这个融合策略(attention fusion)要求能够尽可能保留这些中间过程的discriminative regions对应的attention map。针对这一点采用element-wise maximum operation,即:
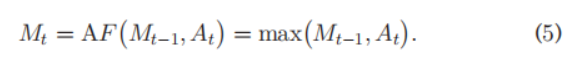
(作者也尝试了使用平均的方法,但是效果不如max的好)
在最开始训练时,分类模型是没有精度的,这个时候无法确定是否要做cumulation,作者设置一个条件,通过判断正在训练的网络的正确率是否达到了目标正确,来觉得是否进行cumulation。
3.3 Integrating an Attention Drop Layer
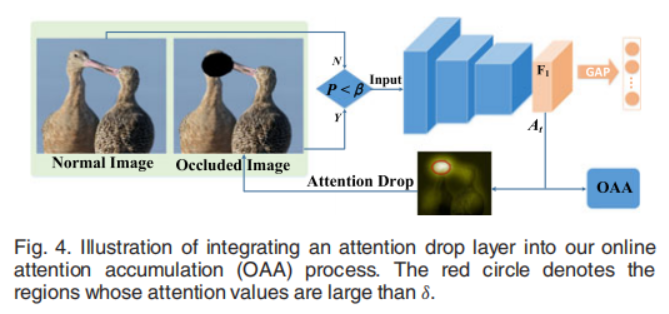
作者发现有些图像在训练中的,它的attention在并不会在目标上发生较大规模的移动。(一些文献通过遮挡attention区域来时网络focus on其他的部分),作者利用这个扩大注意力转移的范围,积累更多未被发现的物体区域,获得完整的物体区域。
具体来说作者设计了一个the attention drop layer,并定义系数
δ
\delta
δ来控制drop的力度(扔掉值大于
δ
\delta
δ的部分),来模拟类似图4中的遮挡效果,同时设置阈值
β
\beta
β来决定是否进行drop。
设计算法如图所示:

(总结来说就是就是控制
β
\beta
β概率的,将原始图像
I
I
I输入到 drop layer
S
(
.
)
S(.)
S(.) 中去,drop层中遮挡住值大于
δ
\delta
δ的部分)
3.4 Towards Integral Attention Learning
仅使用OAA模型的标签级训练监督太弱了,很难处理处理物体attention值比较低的区域。作者将前面cumulation的获得作为监督信号,重新进行监督训练,进一步改善OAA模型,记为OAA+。
具体来说,OAA输出的CAM作为soft label,去训练normalized cumulative attention maps,若采用交叉熵损失,则公式如下:
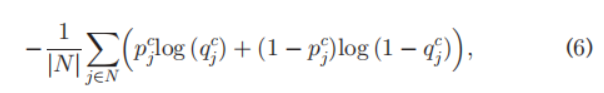
其中
q
j
c
q_j^c
qjc是soft label,由 CAM中的
F
^
\hat{F}
F^产生,
q
j
c
=
σ
(
F
^
j
c
)
q_j^c=\sigma(\hat{F}_j^c)
qjc=σ(F^jc)。而
p
j
c
p_j^c
pjc则表示由normalized cumulative
attention maps经同样手段产生的值。(用总输出CAM训练cumulative attention maps)。
这个公式对图像区域中attention的值较小的区域有也显著的惩罚作用,因为有
1
−
p
j
c
1-p_j^c
1−pjc的存在
p
j
c
p_j^c
pjc极大或者极小都有很大的加权,即给与这两种情况较大的惩罚。
作者在这个基础上进一步进行了改进,根据cumulative attention map的值分别设计不同的损失函数,具体的,将其分为enhance regions
N
+
c
N_+^c
N+c和soft constraint regions
N
−
c
N_-^c
N−c,其中
N
−
c
N_-^c
N−c主要包含像素对应类别值为0的部分,即
p
j
c
=
0
p_j^c=0
pjc=0,而
N
+
c
N_+^c
N+c则包含其他部分,对于
N
+
c
N_+^c
N+c区域有:
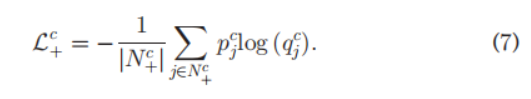
(对这些
N
+
c
N_+^c
N+c区域并不会惩罚
p
j
c
p_j^c
pjc小的,但是我不太理解作者说的(we use
p
j
c
p_j^c
pjc as the ground-truth label instead of 1)是啥意思,以及为啥这么做.)
对于
N
−
c
N_-^c
N−c区域有:
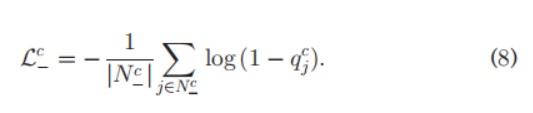
总的损失函数记为这两者的和。
Experiments
(大家自己搜论文看表格吧)
总结
OAA的这种训练方式挺少见的,而且这种自监督(知识蒸馏)的方式在弱监督论文里面很常见。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









