



一篇弱监督分割领域的论文,发表在ICCV2021上:
论文标题:
Leveraging Auxiliary Tasks with Affinity Learning for Weakly Supervised Semantic Segmentation
作者信息:

代码地址:
https://github.com/xulianuwa/AuxSegNet
Abstract
弱监督分割是一项比较有挑战性的任务,仅依赖于图像级标签的CAM方法不足以提供完整的监督。
1.作者提出了AuxSegNet,利用显著性检测(saliency detection)和多标签分类辅助改进WSSS任务。
2.作者提出一种从显著reprentation和分割reprentation中学习cross-task global pixel level affinity 的方法,affinity 为显著性检测和CAM提供伪标签以refine其结果。
Introduction
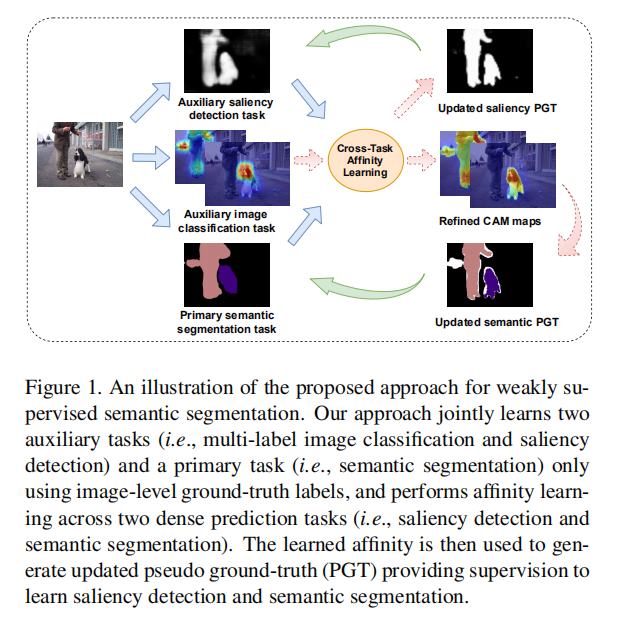
(WSSS的发展中的问题)1.CAM是产生伪分割标签的一种非常关键的技术,但是通过简单的CAM获得的区域非常稀疏,边界也很粗糙。
2.一些通过引入现有的显著map和CAM做结合,来确定可靠的背景区域和目标定位信息,但是它们仅仅用来提供二值化的简单信息,并没有参与网络权重的训练和更新(使用方式单一),导致效果上不来。
(作者的方法)1.作者提出一种网络结构,利用显著性检测和多标签图像分类作为辅助任务,帮助学习语义分割的主要任务。
其中显著性检测主要是用于区分前景和背景,保持分割的输出和显著性检测的一致;多分类则是获取目标本身特征。
2.作者提出了从显著性特征和分割特征中学习 global pixel-level pair-wise affinities的方法,先计算本身的affinity,然后获得一个 cross-task affinity map,利用这个map作者设置了相关的约束条件,去refine saliency predictions and CAM maps,并为其提供伪标签。
Approach
(下图是整体网络的流程架构,感觉蛮复杂的)
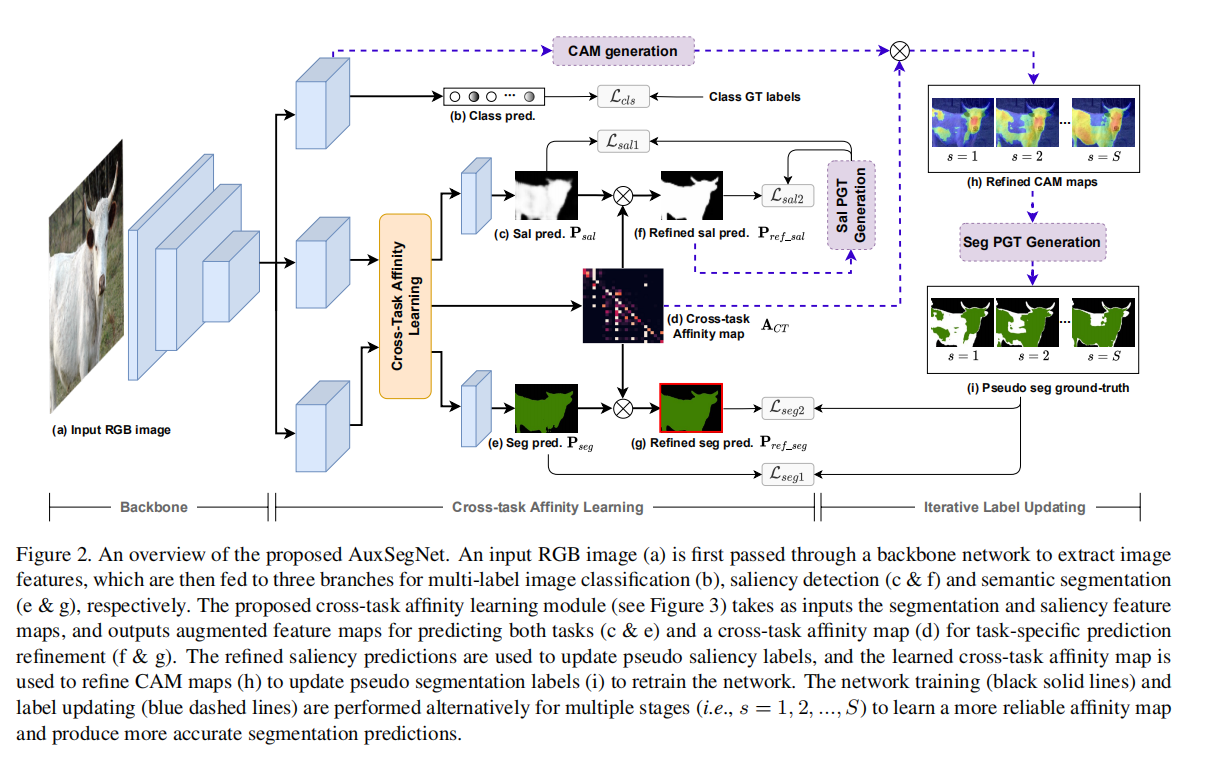
Overview
首先图像输入到一个共享的backbone,然后分成三个branch对应分类、显著性检测、分割任务。显著性检测、分割任务两者任务输入Cross Task Affinity Learning中,先获得各自独立的affinity map,然后学习cross-task affintiy map,这个map用于对显著性检测、分割任务进行refine,同时也用于生成其监督过程中伪标签。
3.1. Multi-Task Auxiliary Learning Framework
Auxiliary supervised image classification
(辅助监督图像分类任务)
完全常规的类别训练和生成CAM的方法:对于backbone中的特征层
F
F
F,先采用GAP层,然后全连接训练,然后:
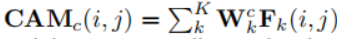
Auxiliary weakly supervised saliency detection with label updating
(辅助显著性检测任务)
对于backbone中的特征,先做两层不同膨胀速率的空洞卷积,获得输入特征
F
s
a
l
−
i
n
F_{sal-in}
Fsal−in。
然后
F
s
a
l
−
i
n
F_{sal-in}
Fsal−in输入到作者提出的cross-task affinity 模块中获得
A
C
T
A_{CT}
ACT和
F
s
a
l
−
o
u
t
F_{sal-out}
Fsal−out。
F
s
a
l
−
o
u
t
F_{sal-out}
Fsal−out(refine feature maps)有
D
D
D个通道,通过1×1卷积和sigmoid得到初步的显著预测图
P
s
a
l
P_{sal}
Psal。
另一边,
F
s
a
l
−
o
u
t
F_{sal-out}
Fsal−out和
A
C
T
A_{CT}
ACT共同获得进一步的显著预测图
P
r
e
f
−
s
a
l
P_{ref-sal}
Pref−sal。
(显著检测部分的refine是需要监督的,作者介绍了伪标签的生成方式:)
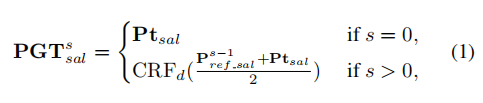
式子中,
s
s
s表示训练阶段,
P
t
s
a
l
Pt_{sal}
Ptsal表示有显著检测模型输出的初始结果。该试表示在训练开始阶段使用显著检测模型输出的初始结果
P
t
s
a
l
Pt_{sal}
Ptsal作为初始伪标签,在训练后的其他阶段使用CRF处理的
P
r
e
f
−
s
a
l
P_{ref-sal}
Pref−sal和
P
t
s
a
l
Pt_{sal}
Ptsal的均值作为伪标签。
(这种生成伪标签的方式感觉很奇怪)
Primary weakly supervised semantic segmentation with label updating
(辅助弱监督分割任务)
和上面的内容详细,同样将对于backbone中的特征,先做两层不同膨胀速率的空洞卷积,提取task-specific features
F
s
e
g
−
i
n
F_{seg-in}
Fseg−in。
F
s
e
g
i
n
F_{seg_in}
Fsegin具有D个通道,输入到作者提出的cross-task affinity 模块中获
A
C
T
A_{CT}
ACT和
F
s
e
g
−
o
u
t
F_{seg-out}
Fseg−out。
F
s
e
g
−
o
u
t
F_{seg-out}
Fseg−out通过1×1卷积和sigmoid得到初步的显著预测图
P
s
e
g
P_{seg}
Pseg。另一边,
F
s
e
g
−
o
u
t
F_{seg-out}
Fseg−out和
A
C
T
A_{CT}
ACT共同获得进一步的显著预测图
P
r
e
f
−
s
e
g
P_{ref-seg}
Pref−seg。
(生成伪标签的方式)
选择CAM中的对象区域和显著性模型的背景区域获得伪标签,具体的第一次用直接获得CAM,其他用经过
A
C
T
A_{CT}
ACT优化后的CAM(这里没看到作者介绍如何使用
A
C
T
A_{CT}
ACT优化CAM)。
3.2. Cross-task Affinity Learning
(下图为cross-task-affinity的主要结构)
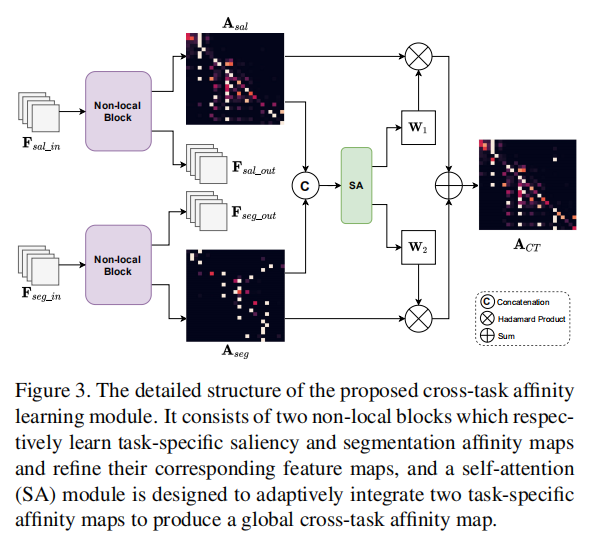
作者认为
F
s
e
g
F_{seg}
Fseg和
F
s
a
l
F_{sal}
Fsal语义关系密切,都是密集型预测任务且包含互补的上下文信息,作者希望利用这些去refine CAM。
Cross-task affinity
首先,作者提出了一个基于自注意力机制的Non-Local模块,通过语义affinity来分别捕获
F
s
e
g
F_{seg}
Fseg和
F
s
a
l
F_{sal}
Fsal中feature vectors of any two positions的语义关联(说白了就是对自身做自注意力),Non-Local模块的输入输出如下:
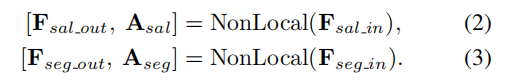
以
F
s
a
l
−
i
n
F_{sal-in}
Fsal−in为例,NonLocal中首先使用1×1卷积,将特征转化为
(
Q
,
K
,
V
)
(Q,K,V)
(Q,K,V)组,每个都是
H
W
×
D
HW×D
HW×D。为了得到pair-wise affinity,作者将
Q
Q
Q和
K
K
Kdot product,得到显著性affinity matrix
A
s
a
l
A_{sal}
Asal,其中的每一行表示一个空间位置和其他位置的相似性值,接着使用Softmax将这些值化为0到1之间。下面进一步refine这些affinity,得到attented 特征图,将它们和输入的特征做add后获得
F
s
a
l
o
u
t
F_{sal_out}
Fsalout。
(attented 特征图具体怎么做,原文是:Each position of the input feature maps is then modified by attending to all positions and taking the sum of the product of all positions with their corresponding affinity values associated to the given position in the feature space.这里我没看懂)
同样的对 F s e g − i n F_{seg-in} Fseg−in操作后可以获得 F s e g o u t F_{seg_out} Fsegout和 A s e g A_{seg} Aseg。
进一步的,作者又设计了SA模块用于整合这两个独立的affinity,其包含两层卷积和一个Softmax,它的输出是两个权重值,记为
W
1
W_1
W1和
W
2
W_2
W2。使用这两个权重值对
A
s
e
g
A_{seg}
Aseg和
A
s
a
l
A_{sal}
Asal加权求和,得到最终的
A
C
T
A_{CT}
ACT,如下:
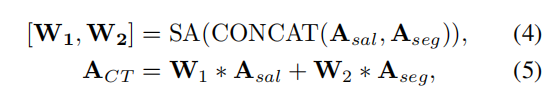
Multi-task constraints on cross-task affinity
(通过
A
C
T
A_{CT}
ACT对显著性检测任务和分割任务进行refine)
通过如下公式进行refine:
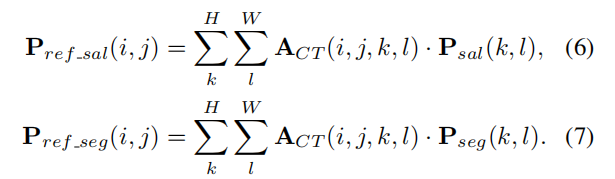
(就是依次对每个像素乘上
A
C
T
A_{CT}
ACT,没看出来哪里用到了constraints )
3.3. Training and Inference
Overall optimization objective
作者为整体网络加入了很多监督过程,主要包括:
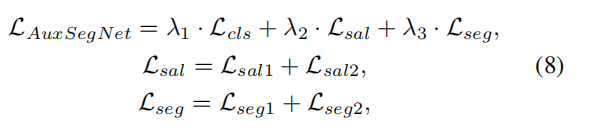
其中
L
s
e
g
L_{seg}
Lseg和
L
s
a
l
L_{sal}
Lsal的监督过程均在figure2中给出,主要是计算binary cross entropy losses在predic\refine和伪标签的salency或者segment上进行计算。其余几个为权重参数。
Stage-wise training:
(网络整体的训练流程):1.先训练分类网络15个epoch。2.利用这个参数初始化并继续训练整体网络AuxSegNet。3.每训练10个epoch作为一个stage,每个stage更新显著性检测和分割的伪标签。
Experiments
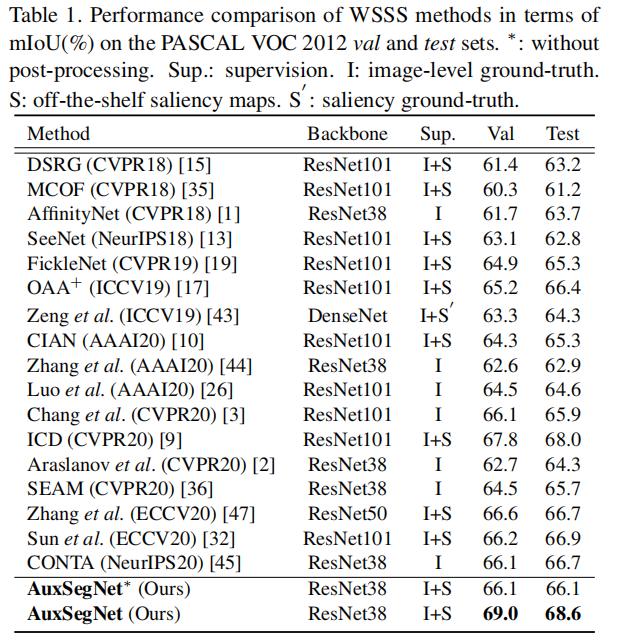
(一些和其他方法的对比)
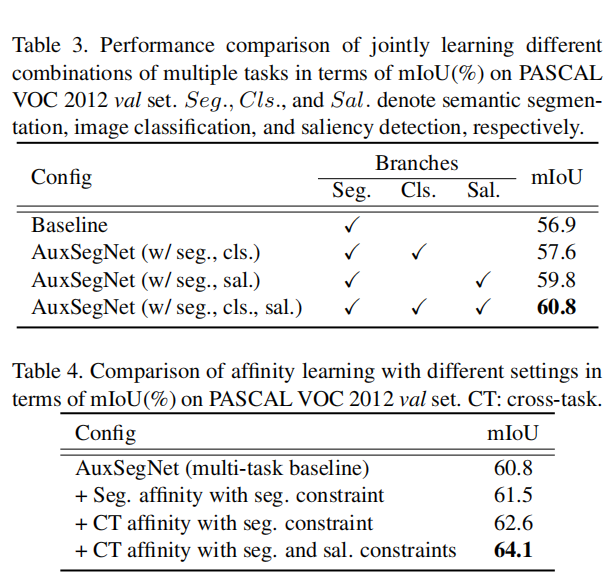
(一些消融性实验对比)
总结
深度利用到了显著性检测任务去进行辅助WSSS,但是感觉并没有太多affinity的东西,和做像素级别的affinity的论文感觉还是有很大不同:
1.Learning Affinity From Attention End-to-End Weakly Supervised Semantic Segmentation With Transformers(CVPR2022)
2.Learning Pixel-Level Semantic(CVPR2018)
另外这个流程好复杂。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









