



 文章讲述了正则表达式中的各种选项,如icase(忽略大小写)、nosubs(不显示子表达式)、optimize(优化匹配)和collate(本地化字符范围),以及ECMAScript、basic、extended、awk、grep和egrep等不同文法的选择和使用方法。
文章讲述了正则表达式中的各种选项,如icase(忽略大小写)、nosubs(不显示子表达式)、optimize(优化匹配)和collate(本地化字符范围),以及ECMAScript、basic、extended、awk、grep和egrep等不同文法的选择和使用方法。
常量
| 值 | 效果 |
icase | 应当以不考虑大小写进行字符匹配。 |
nosubs | 进行匹配时,将所有被标记的子表达式 (expr) 当做非标记的子表达式 (?:expr)。不将匹配存储于提供的 std::regex_match 结构中,且 mark_count() 为零。 |
optimize | 指示正则表达式引擎进行更快的匹配,带有令构造变慢的潜在开销。例如这可能表示将非确定有限状态机转换为确定有限状态机。 |
collate | 形如 "[a-b]" 的字符范围将对本地环境敏感。 |
multiline (C++17) | 如果选择 ECMAScript 引擎,那么指定 ^ 应该匹配行首,而 $ 应该匹配行尾。 |
ECMAScript | 使用改 ECMAScript 正则表达式文法 |
basic | 使用基本 POSIX 正则表达式文法(文法文档)。 |
extended | 使用扩展 POSIX 正则表达式文法(文法文档)。 |
awk | 使用 POSIX 中 awk 工具所用的正则表达式文法(文法文档)。 |
grep | 使用 POSIX 中 grep 工具所用的正则表达式文法。这等效于 basic 选项附带作为另一种分隔符的换行符 '\n'。 |
egrep | 使用 POSIX 中 grep 工具带 -E 选项所用的正则表达式文法。这等效于 extended 附带 '|' 之外的作为另一种分隔符的换行符 '\n'。 |
最多只能选取 ECMAScript、basic、extended、awk、grep 和 egrep 中的一个文法选项。如果不选取文法选项,那么设定为选取 ECMAScript。其他选项作为修饰符工作,从而
std::regex("meow", std::regex::icase)
等价于
std::regex("meow", std::regex::ECMAScript|std::regex::icase)
icase:这个词语通常出现在正则表达式中,表示忽略大小写。例如,在awk或grep中,可以使用-i选项实现这一点。nosubs:这个词语通常出现在awk命令中,表示不输出匹配的子串。optimize:这个词语通常用于描述对代码或算法的优化,以提高其性能或效率。collate:这个词语通常用于指对文本进行排序或整理的操作。在awk和grep等工具中,可以使用sort命令进行此类操作。ECMAScript:这是一种用于网页浏览器的脚本语言,通常与HTML和CSS一起使用,由欧洲计算机制造商协会(ECMA)制定和维护。basic和extended:这两个词语通常用于描述正则表达式的特性。basic模式只包含基本的正则表达式元素,而extended模式则包含更多的高级元素和功能。awk:这是一种用于处理文本数据的命令行工具,具有强大的数据处理和报告生成能力。grep:这也是一种用于处理文本数据的命令行工具,用于搜索和匹配文本中的特定模式。egrep:这是增强版的grep,结合了基本正则表达式和扩展正则表达式的功能。
regex库默认使用的ECMAScript文法的表达式
如果想要更改为其它文法,只需要在regex构造函数中最后一位填入对应文法即可,例如:
regex r("<.*?>(.*)<.*?>", regex_constants::grep);
当然除了选择文法,还可以选择其它标志,只需要将他们用符号 | 连接起来即可
如忽略大小写匹配可以写为
regex r("<.*?>(.*)<.*?>", regex_constants::grep|regex_constants::icase);
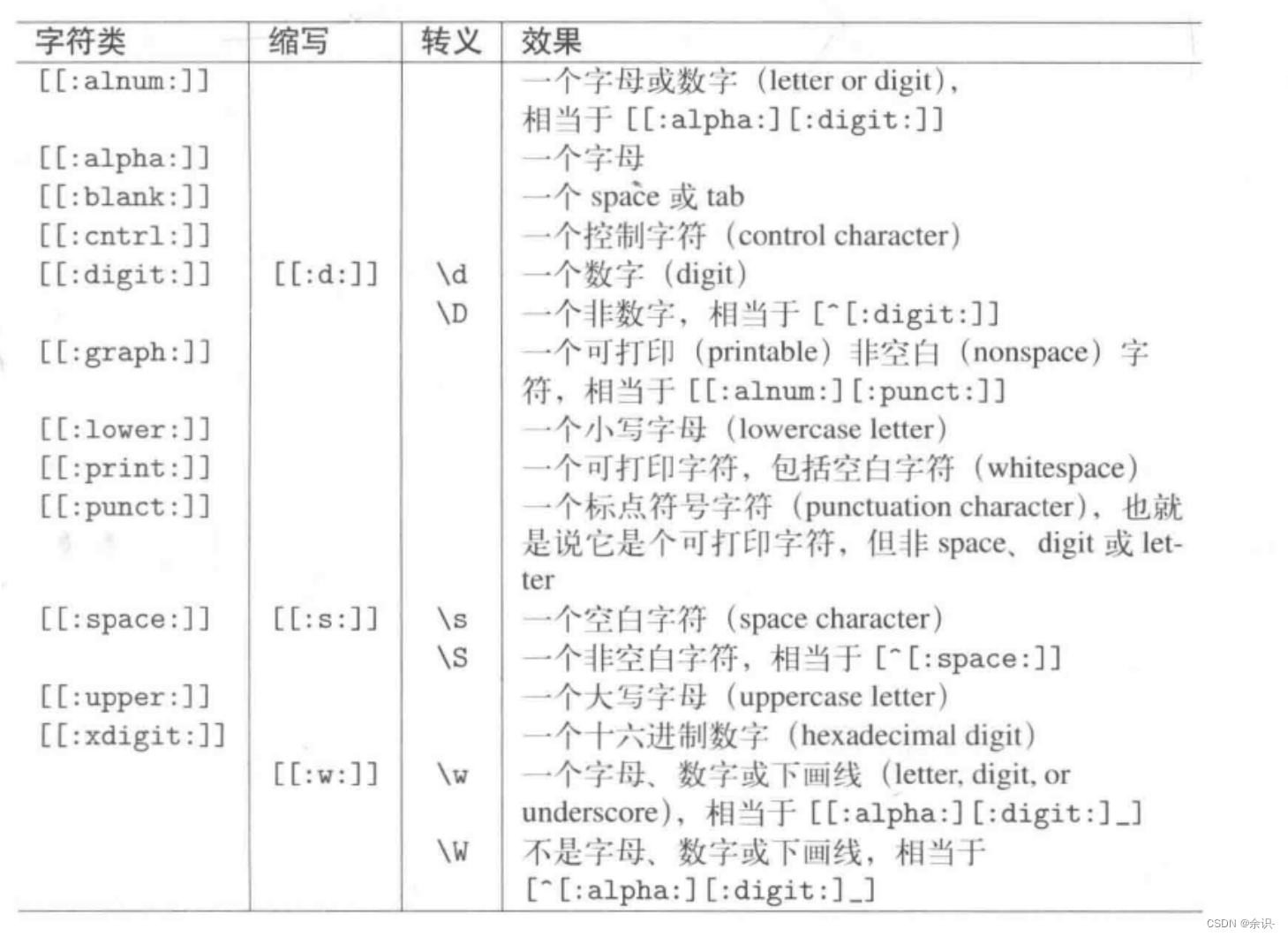
可以看到,其实这些可选项都在regex_constants中,还有其它可选项如下: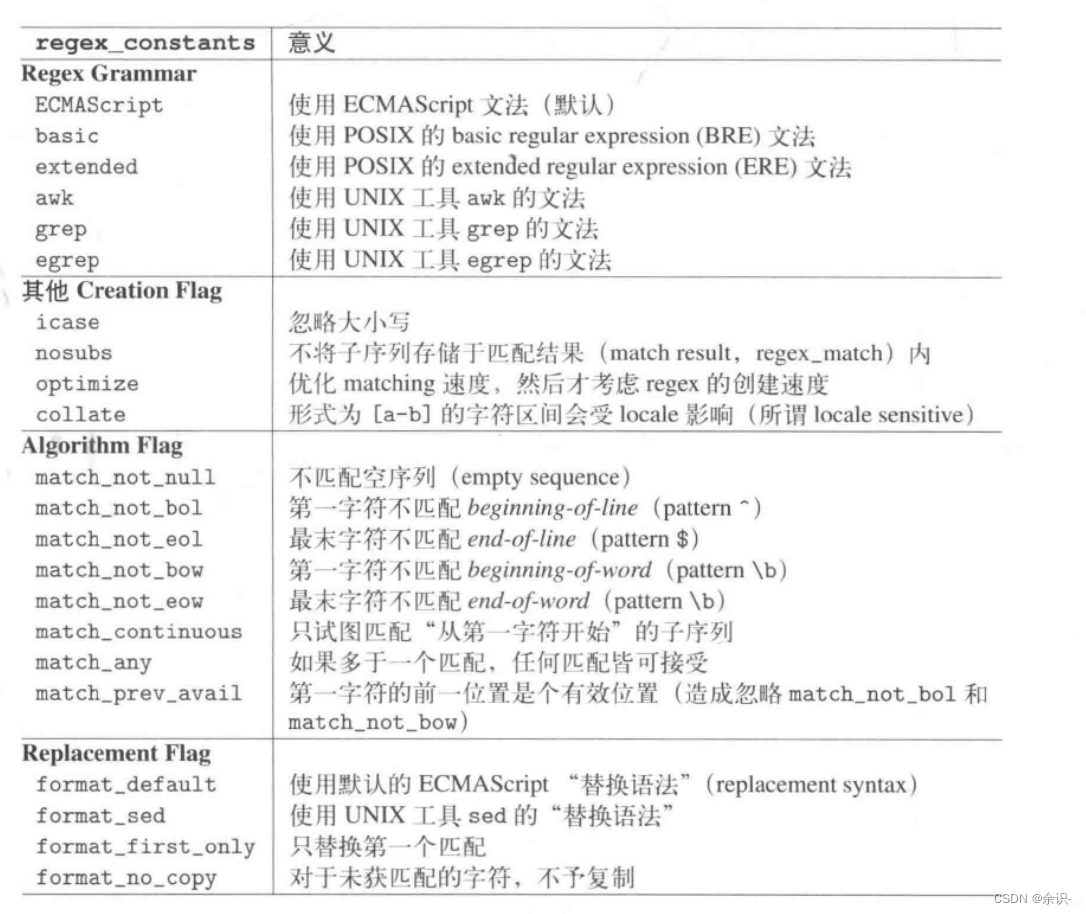
不同文法之间的差异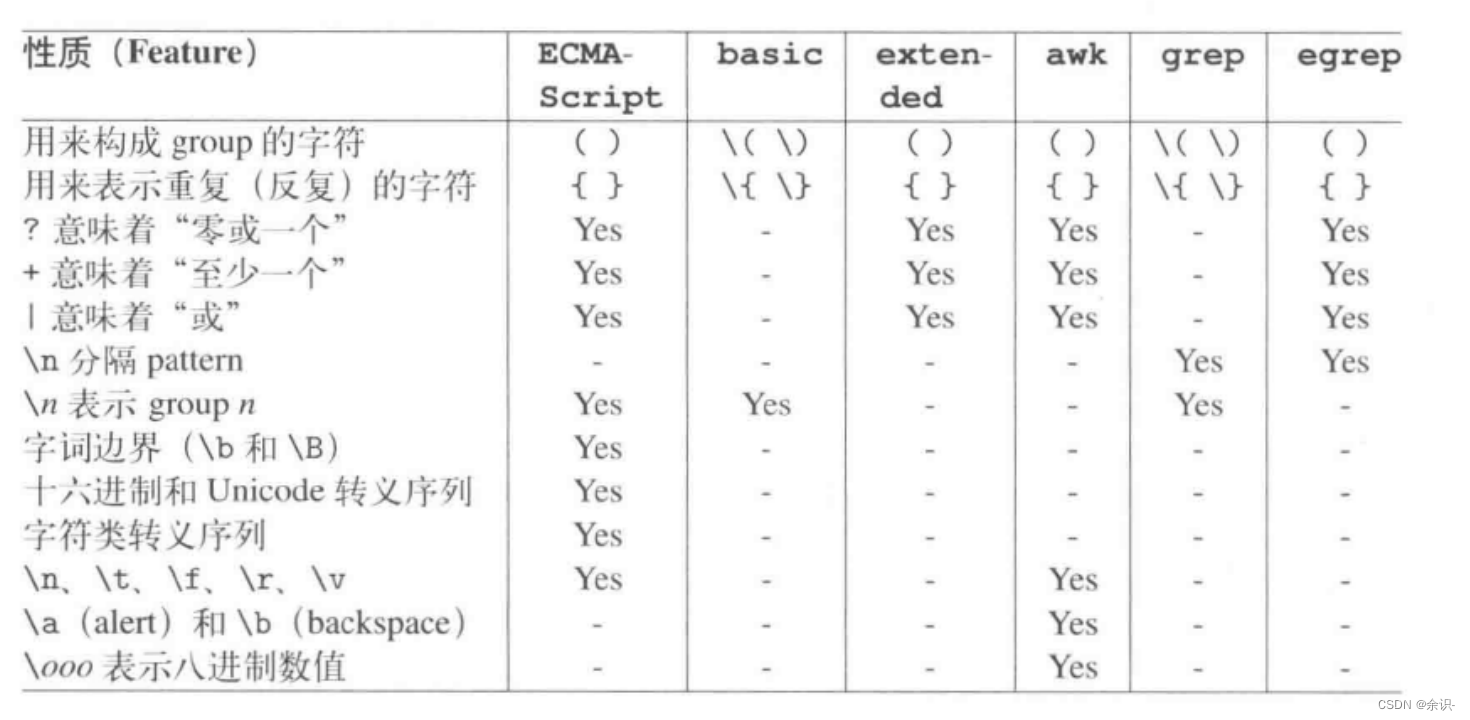
还需要注意的是,C++中许多字符需要添加\ 符号进行转义才能使用,过于麻烦,所以C++11之后,出现了如下写法:
R"dem(内容)dem"
使用该写法就可以不再转义即可使用,其中dem为任意字符,但要求前后一致即可,其它为固定写法.

















 689
689

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









