






一个下午,我折腾出了一个 Code Review 的 Skill
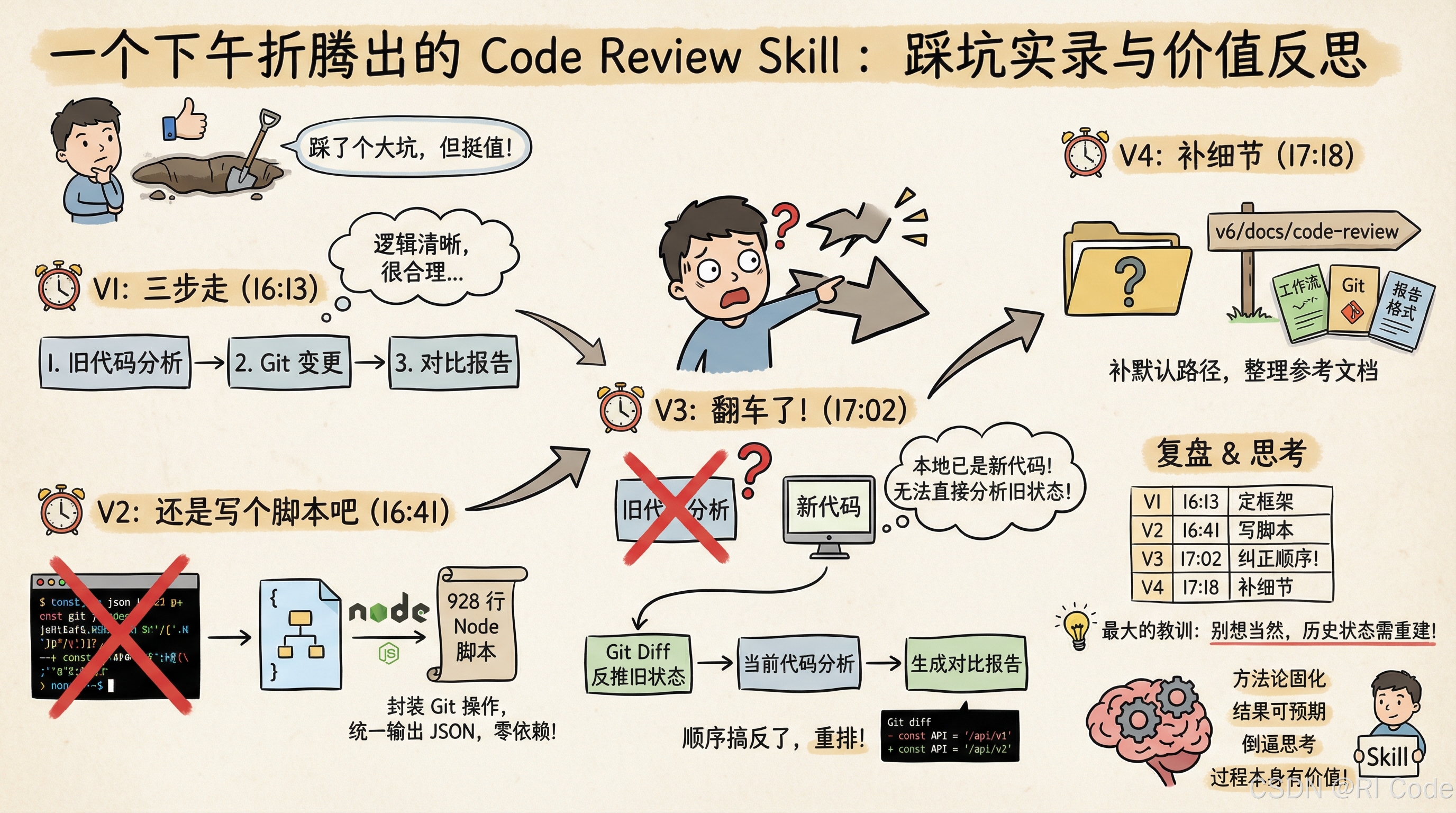
踩了个大坑,但挺值
起因
事情是这样的。
我手头有两个之前写的小工具:一个能分析代码里的 API 调用流程,画成时序图;另一个能从 Git 里捞变更内容。某天下午我突然想到,这俩拼一块儿,不就能做代码审查了吗?
不是那种"帮我看看有没有 bug"的审查——那个 Claude 本来就能干。我想要的是:告诉我这次改动到底改了哪些调用链,影响了哪些依赖,风险在哪。
想想就挺美,动手吧。
第一版:三步走,很合理(16:13)
我的设计很朴素:
第一步:分析变更前的代码,生成基准报告
第二步:用 Git 拿到变更内容
第三步:对比一下,出报告
嗯,逻辑清晰,无懈可击。
我还顺手规划了报告的样式——用 Mermaid 画图,绿色表示新增的,黄色表示改过的,红色虚线表示删掉的。脑子里已经在预演最终效果了。
用 /skill-creator 初始化好目录结构,写完 SKILL.md,感觉良好。
第二版:还是写个脚本吧(16:41)
开始实现第二步的时候,我犹豫了一下。
让 Claude 直接跑 Git 命令?比如:
git diff --name-status
git show abc123
git diff main..feature
想了想,还是算了。这些命令的输出格式乱七八糟,有的带颜色,有的不带;文件名要是有空格或者中文,又得特殊处理;diff 太长还会截断… 让 Claude 去解析这些乱麻,不太靠谱。
干脆自己写个 Node 脚本,把 Git 操作封装一下,统一输出成 JSON。这样 Claude 拿到的就是干干净净的结构化数据,省心。
给自己定了几个约束:
- 用 Node 18+,能用原生 API 就不引依赖
- 零
npm install,拿来就能跑 - 输出必须是 JSON,方便后续处理
最后这脚本写了 928 行。支持六种模式:看工作区变更、看暂存区、看某个 commit、和某个分支比、看最近 N 次提交、比较两个 commit 之间… 基本够用了。
{
"metadata": { "gitMode": "branch:main", "currentBranch": "feature/xxx" },
"summary": { "added": 2, "modified": 3, "deleted": 1 },
"files": [
{ "path": "src/hooks/useAuth.ts", "status": "modified", "diff": "..." }
]
}
到这儿为止,一切都挺顺的。
第三版:翻车了(17:02)
然后我实际跑了一遍。
跑完愣住了。
我设计的第一步是"分析变更前的代码"对吧?但问题是——当我执行这个 Skill 的时候,本地的代码已经是改完之后的代码了啊!
所以第一步分析出来的根本不是"变更前"的工作流,而是"变更后"的。整个对比的前提就是错的。
我盯着屏幕想了几秒,有点想笑。这 bug 属于"设计时觉得很合理,跑起来才发现根本不是那么回事"的典型。
怎么办?
想了一会儿,发现 Git diff 里其实啥都有:
- const API = '/api/v1/user'
+ const API = '/api/v2/user'
减号开头的是原来的,加号开头的是现在的。也就是说,我可以从 diff 反推出变更前的状态。
那就把顺序换一下:
第一步:先拿 Git diff(这里面有变更前后的全部信息)
第二步:分析当前代码的工作流(这是"变更后"的状态)
第三步:根据 diff 反推"变更前"的工作流,然后生成对比
这才对。当前能直接分析的是"变更后","变更前"得靠 diff 倒推。之前的设计完全搞反了。
改完之后顺畅多了。
第四版:补个默认值(17:18)
最后跑了一遍 git diff --stat,发现文档里漏了一个东西:报告默认输出到哪?
这种细节不写清楚,用的时候肯定要问。补上:
默认输出目录:v6/docs/code-review
顺手整理了一下三份参考文档,一份管工作流分析,一份管 Git 变更检测,一份管报告格式。各管各的,以后好维护。
复盘
整个过程大概一个半小时,改了四版。
| 版本 | 时间 | 干了啥 |
|---|---|---|
| v1 | 16:13 | 定了三步走的框架 |
| v2 | 16:41 | 写了个 Node 脚本处理 Git |
| v3 | 17:02 | 发现顺序错了,重排 |
| v4 | 17:18 | 补文档细节 |
最大的教训是 v3 那个坑。
画流程图的时候,很容易想当然地觉得"旧版本"和"新版本"都能直接拿到。但实际跑起来,你手头只有当前状态,历史状态得自己想办法重建。
这个道理说出来谁都懂,但设计的时候真的很容易忘。
最终长这样
skills/code-review/
├── SKILL.md # 主文档
├── scripts/
│ └── git-change-collector.js # Git 脚本(928 行)
└── references/
├── analyze-codeflow.md # 工作流分析
├── git-change-detection.md # Git 变更检测
└── change-report-format.md # 报告格式
用起来大概这样:
# 看看工作区改了啥
node scripts/git-change-collector.js --mode diff --source src/modules/user
# 和 main 分支比一下
node scripts/git-change-collector.js --mode branch:main
# 看最近 3 次提交
node scripts/git-change-collector.js --mode last:3
输出的报告会有时序图对比、依赖图对比、每处变更的影响评估,还有个验证清单告诉你该测哪些东西。所有节点都有编号,讨论的时候可以直接说"S3 这个调用有问题",不用来回描述。
为什么要写成 Skill
有人可能会说:直接让 Claude 审查不就行了,干嘛非得搞个 Skill?
我是这么想的:Skill 就是把一套方法论固化下来。
每次审查都用同样的分析框架、同样的输出格式,结果是可预期的。下次再审查,不用重新解释一遍"帮我看看 API 调用链有没有变化",直接调就行。
而且写 Skill 的过程会逼着你把事情想清楚。那个"顺序搞反了"的 bug,如果不是认真设计工作流,可能就一直藏着,每次审查的结果都是错的还不自知。
工具会倒逼你思考。这个过程本身就挺有价值的。


















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











