




 本文综述了视频实例分割领域的前沿技术,包括FusionSeg、SegFlow、PointRend等算法,详细解析了各算法的网络结构、创新点及应用效果,为研究者提供了全面的技术参考。
本文综述了视频实例分割领域的前沿技术,包括FusionSeg、SegFlow、PointRend等算法,详细解析了各算法的网络结构、创新点及应用效果,为研究者提供了全面的技术参考。
此处最后粗略解读更新时间:2020-2-26
11. 论文:FusionSeg
我的印象:一个中规中矩的利用了光流图片的网络
- 效果:
一般,让人感觉边缘分割相对粗糙


- 网络结构:
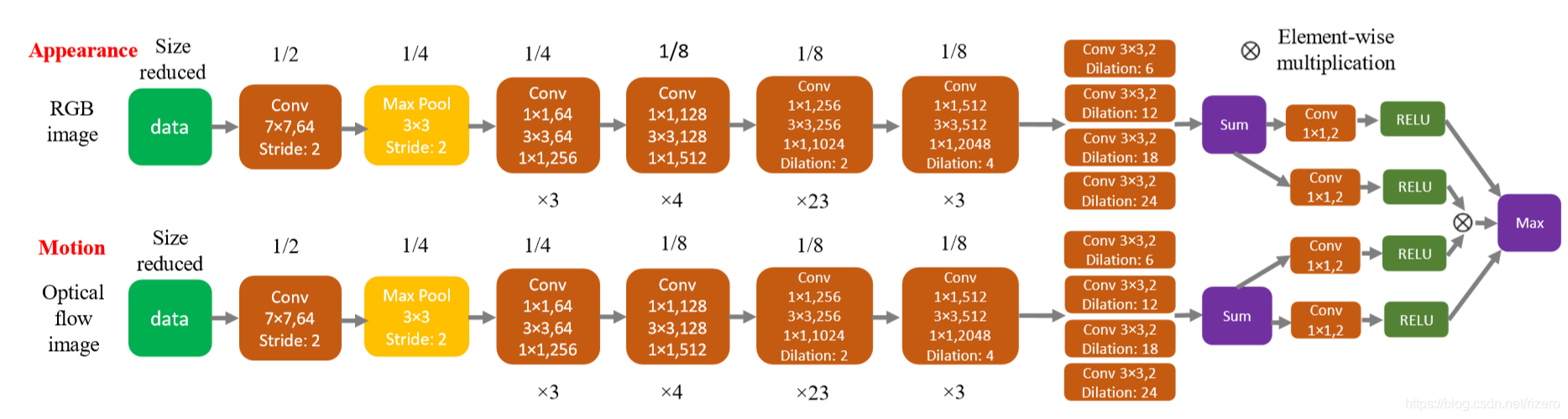
- 思想:
网络包含两个分支(两个Resnet101,都是深层神经网络),一个学习RGB图片表观特征,一个学习光流特征(注意,光流特征输入的是光流图片,光流图片外部生成,用FlowNet),最后输出单个分割结果。 - 成功原因:
FSEG使用了深层神经网络进行图像特征学习,利用了光流图片(不是光流数据)给出运动物体产生的残影,这是一种比较初级的应用(我也有过直接利用光流图片的想法)。两个Resnet101的特征结合方法也是比较常规。相当于对每一帧都把网络跑一次进行分割,帧间关系只靠光流图片维持,这个方法中规中矩。靠深层网络学特征(这是静态分割的经典路线),然后加上了使用光流图片进行每帧辅助分割的部分。
10. 论文:SegFlow
我的印象:充分利用帧间光流信息和静态分割的优秀分割网络
-
效果:
很好,主要看做右边那列和最左边那列的对比,明显对一些细节有注意

-
网络结构:
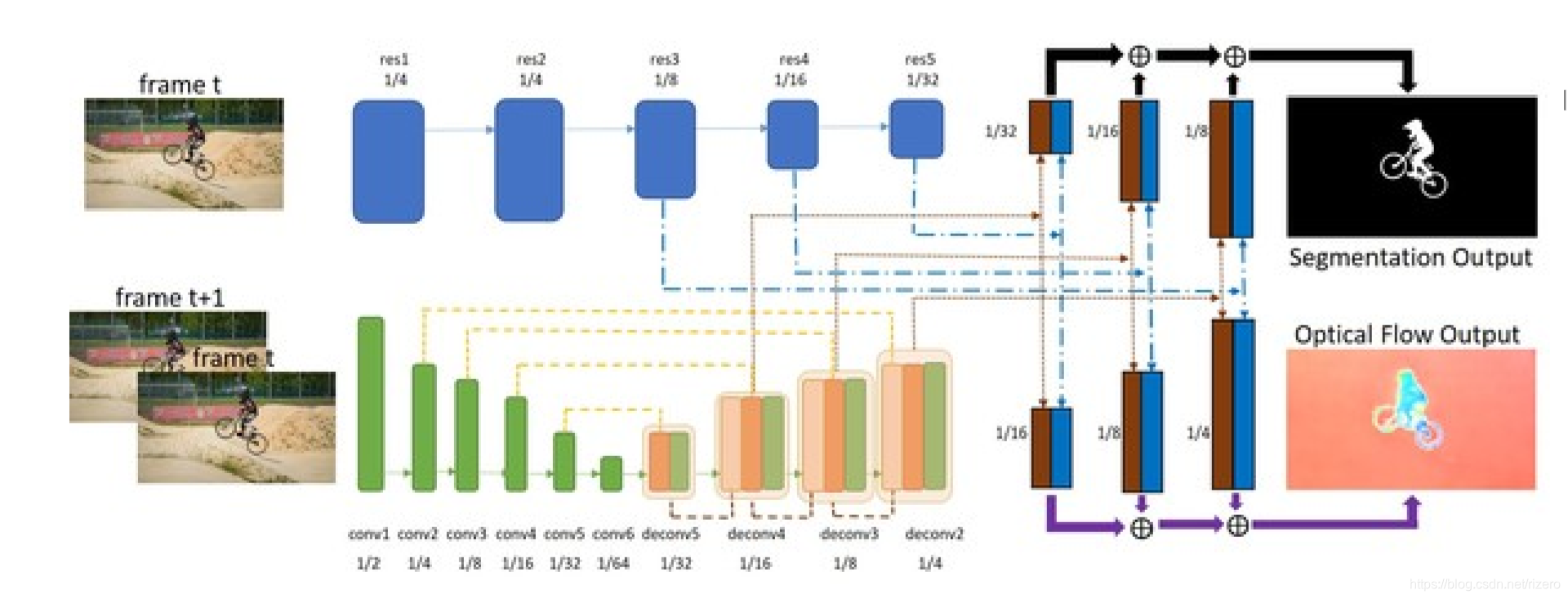
首先,在光流计算的网络里面他用了编码器解码器的结构,就是我们之前看的Inet和Pnet那种结构。
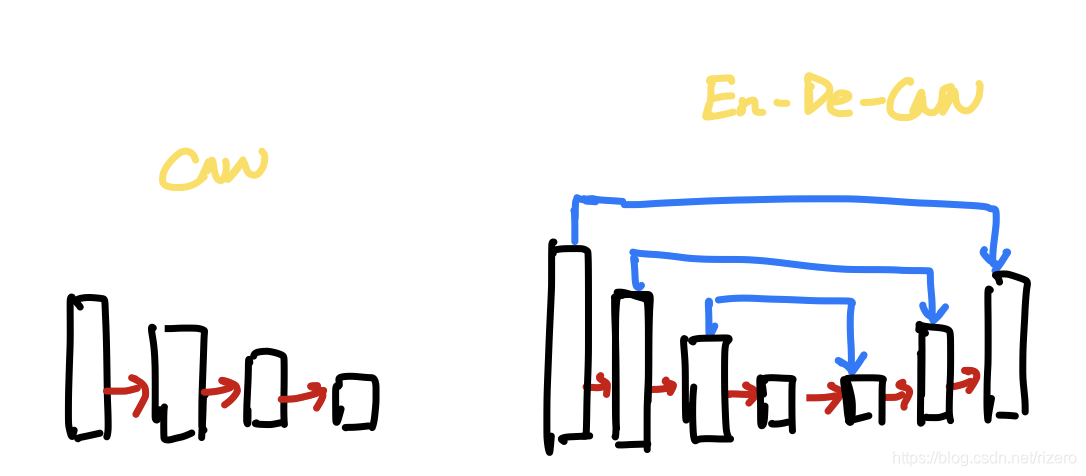
这种结构的好处在于能够把一些浅层丢失的信息找回来,由于像原生的Resnet101深层网络在直线传播的时候不断卷积难免会有信息丢失,使用编码解码的结构会帮助学习到更多特征信息。
传统CNN和典型的编码器解码器套路示意图:
留意他的双层网络,上层使用单一的RGB特征蒙版学习,是直线传播过去的,没有用编码解码的结构,和《1.论文:FusionSeg》里面的RGB网络结构一致,估计这种方法对于RGB蒙版静态分割是有效的,所以大家才会有这个共通之处。
最后看下他的特征聚合方法:
聚合用到了共享特征的方法以此输出两个结果(一个蒙版结果,一个光流结果),后面特征聚合的棕色的各层数据来自于下层光流网络第二次之后每一层解码的数据,蓝色来自于上层RGB特征学习网络的每一层。这样一来,他的网络很好的把单帧的数据的特征和两帧之间的光流数据充分考虑了。 -
学到的架构套路:
(1)来自于基本同层次的数据使用cat拼接
(2)来自不同层次的数据使用逐元素分权相加或者二次卷积
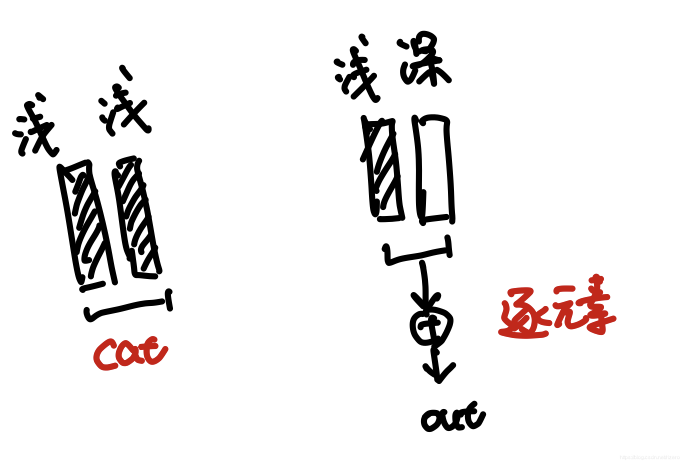
注:他在这篇文章使用的光流网络是FlownetS,来自于Flownet2.0那篇文章,输出的光流数据是非常好的,他在这里也提到为什么输出两个结果,论文说经过和蒙版配合训练得到的光流数据也得到了优化,结果两边都好,蒙版效果提升了,光流结果也提升了。
9. 论文:PointRend
我的印象:用于修复边缘的部件
- 效果:
对边缘的结果的修复看起来非常不错,分辨率越高的修复结果越好。
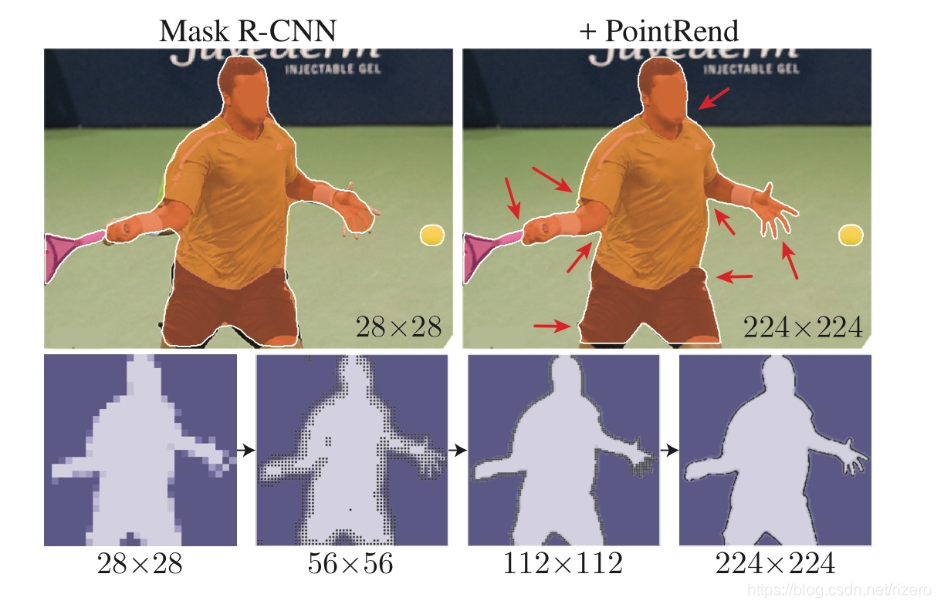
- 核心算法解释(我个人看法)
算法本质是提升上采样算法的质量。
背景前提:
因为在cnn的backbone降采样次数实在太多了,文中提到的Mask-R-cnn(也是何凯明的作品),预测出来的mask只有28x28,这是由resnet本身的结构决定的,网络越深就意味着你输出的分辨率越低。从28*28恢复到正常的图片大小边缘难免会出现偏差,一些细节就丢失了。
算法步骤:
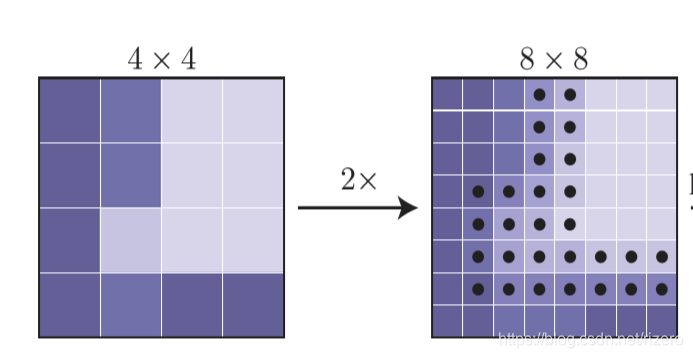
- 第一步:我们手上拿到了根据深层网络预测的蒙版,假设他只有4x4吧
- 第二步:我们首先对蒙版做一次2倍的双线性插值上采样得到8*8,说白了就是传统的图像resize的算法。
- 第三步:挑选出 N 个“黑点”,即结果很有可能和周围点不一样的点(比如边缘):
如图(第二三步合在一起了):
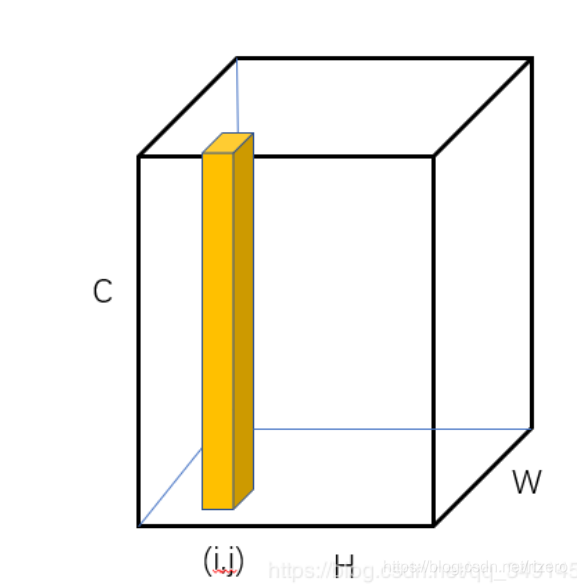
- 第四步:对于每个黑点,获取其“表征向量”,“表征向量”由两个部分组成,其一是低层特征,在进行双线性插值的特征,其二是高层特征,由步骤 1 获得,就是CNN-backbone深层细粒度的特征图。
- 第五步:给出预测,留下一些是边缘可能性大点,删掉可能性小的点,然后重复刚才的2-5步,逐渐从4x4→\rightarrow→ 8x8 →\rightarrow→ 16x16 →\rightarrow→ 32x32
现在,问题在于怎样选,留下和删掉的标准到底是什么,这时候我们利用ML来完成,文章提到说,开始更加偏向于随机采样的标准,我猜测这个训练的部分是可以放在网络训练里面,但是至于怎样放,文章并没有给出图。
8. 论文:FEELVOS
我的印象:提出新的描述两个像素相似的标准和充分利用了时序信息
- 效果:

- 算法步骤:
这是多目标分割但仍然由值得我们借鉴的地方。
- 先用静态图像分割DeepLabv3+(去除最后的输出层)获得特征信息,在最顶层加上一个embeeding层用来提取embedding 向量。
- 根据embedding向量,通过global matching和 local matching得到两个distance map。
- 将两个distance map,DeepLabv3+提出的特征,前一帧的预测结果一共四个成分当做输入,送入到一个dynamic segmentation head中,这个头网络本质是4个深度分离卷积的stack。然后得到预测结果。
- 以上过程对帧中的每一个实例都进行一次,所以所用时间是随着实例的数目线性增加的。
- embedding向量
该向量是通过在DeepLabv3+(移除输出层)上再加了一个embedding层得到的。
这个层的向量用来描述像素的类别向量。
(1)如果两个像素是同一类的,那么这两个像素对应的embedding向量之间的距离会很接近。
(2)如果两个像素不属于同一类,那么这两个像素对应的embedding向量的距离很远。
然后我们设计标准描述两个像素的相似定义:
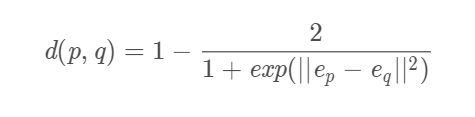
epe_pep是对应于像素p的embedding向量,d(p,q)就是像素p到q在embedding空间的距离。距离越小,说明p和q是属于一类,反之亦然。
对于相同类别的像素,我们可以很轻松的求出d的值应该很接近0或者为0;对弈不同类别的像素,d接近1或者为1。
这里p和q来自不同的输入。其中一个像素,我们假设为q,q可能来自第一帧的embedding 像素,也可能来自前一帧的embedding像素;而另一个p,则是来自当前帧的embedding像素。根据q的不同,计算两种distance map:Global distance map和 Local distance map,分别用到global matching和local matching。
- Global matching:(全局特征匹配)
第一帧送进网络仅仅是为了获得它的embedding向量,作为reference map,我们并不需要对第一帧做预测,因为第一帧的结果是已知的。
当前帧送进deeplabv3+得到embedding向量。我们先约定符号:
(1)PtP_tPt 记作第t帧的所有像素集合。
(2)Pt,oP_{t,o}Pt,o记作,第t帧中属于类别O的像素集合。
(3)p 记作当前帧中的一个像素。
(4)Gt,o(p)G_{t,o}(p)Gt,o(p) 记作p这个像素对应的global matching distance map的值
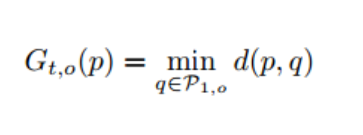
所以想要得到完整的global matching distance map,需要把当前帧所有的像素点的embedding向量,都和第一帧中属于同一类的embedding向量用之前定义的向量距离公式计算,然后取最小的距离值。
这个过程其实相当费时间。论文中网络输入大小为465x465,即便经过deeplabv3+得到减少4倍的特征图,计算量仍然很大,虽然最终能跑0.5秒一帧。
- Local previous Frame Matching(局部特征匹配)
现在p属于前一帧的像素。计算公式仍然和全局匹配距离图的方法很相似
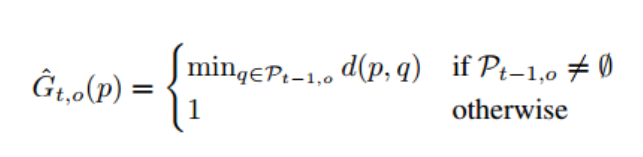
注意到前一帧可能没有目标的,所以有个otherwise选项。如果前一帧没有目标,那么得到的map都是1。
但是前一帧和当前帧中目标的移动一般是很小的,没有必要还去用当前embedding feature的一个向量对所有的第一帧的embedding向量计算距离。受到Flownet的启发,仅仅在一个k邻域的大小中计算距离。也就是用一个2*k+1的窗口约束q的位置。所以实际上使用的是下面的公式:
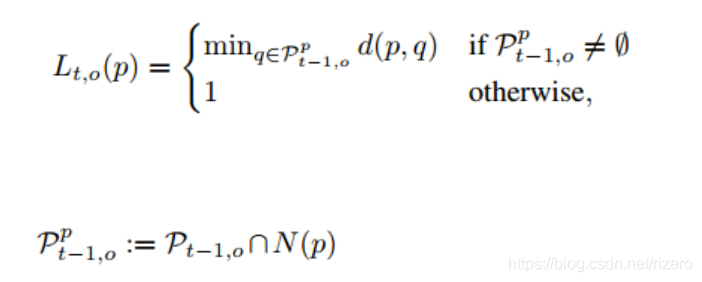
N是在p的x和y方向上至多k个像素距离的像素集合,q则是前一帧的像素。
- 网络结构
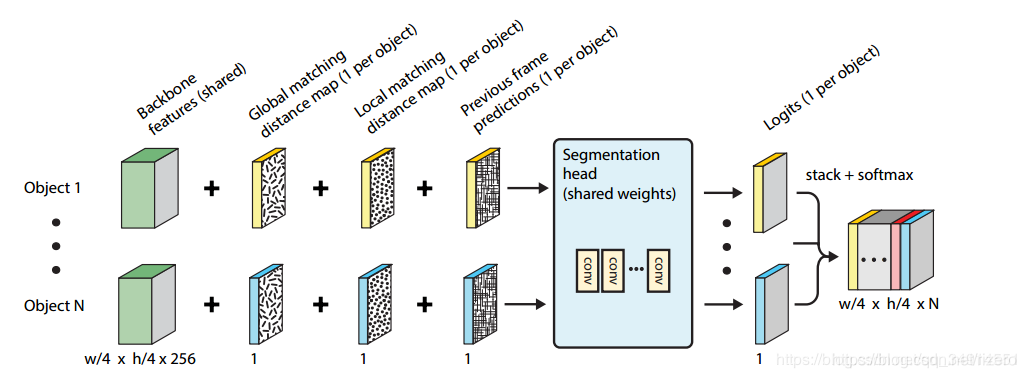
网络输入有四样:两个distance map,前一帧的预测结果,当前帧的deeplabv3+的输出特征图(不含embedding layer)
这个头网络结构简单,有四个深度分离卷积组成,产生一个一维的feature map用来预测类别,注意这个map仅仅为一个目标预测类别 logits,所有实例目标都要经过这样的网络流程。所以每个实例都会得到一个一维的feature map,将它们stack一起,使用softmax,用一个交叉熵和label训练。
文章关于利用时序信息和衡量像素相似的评价标准还是由值得学习的地方。
7. 论文:经典的 Mask R-CNN
我的印象:通过目标检测来降低整体难度
-
效果
虽然他是用来多对象实例分割的,但他的思想仍有值得学习的地方。因为多实例分割任务能完成,就意味着他也能完成单实例分割的任务。

实例分割的难点在于:需要同时检测出目标的位置并且对目标进行分割,所以这就需要融合目标检测(框出目标的位置)以及语义分割(对像素进行分类,分割出目标)方法。在Mask R-CNN之前,Faster R-CNN在目标检测领域表现较好,同时FCN在语义分割领域表现较好。所以很自然的方法是将Faster R-CNN与FCN相结合。 -
网络结构
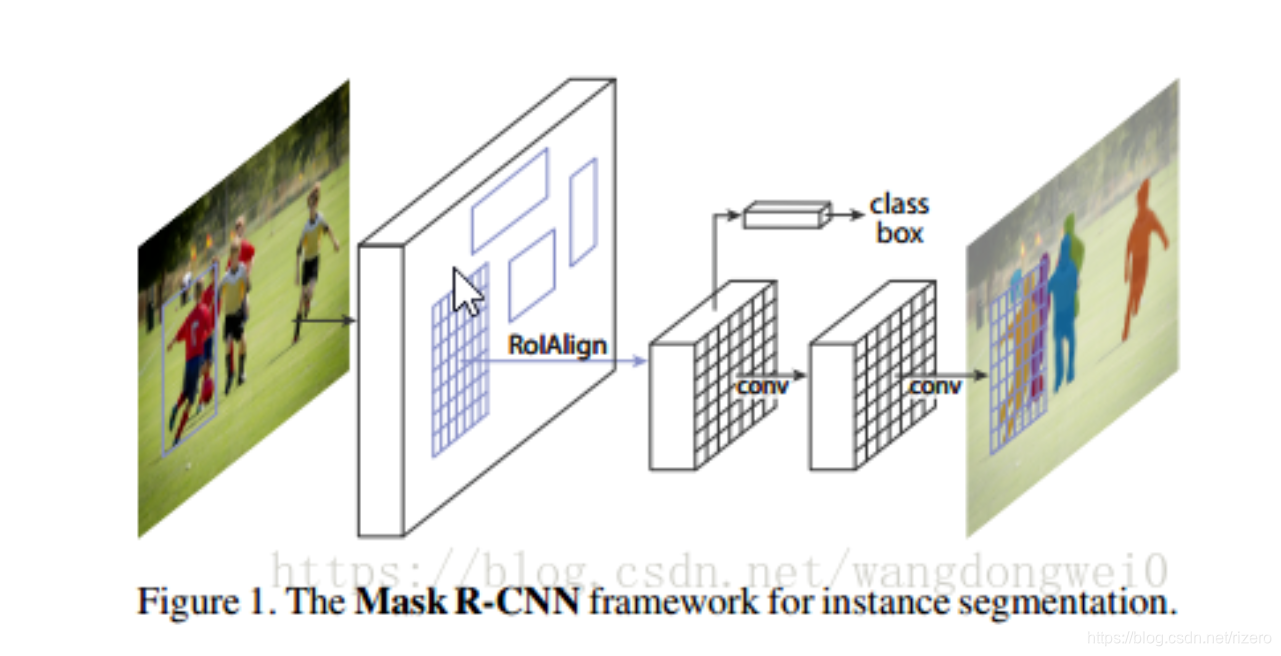
实现步骤其实很简单,首先先用Faster-R-CNN目标检测出ROI Align,然后在ROI区域里面进行像素分类。
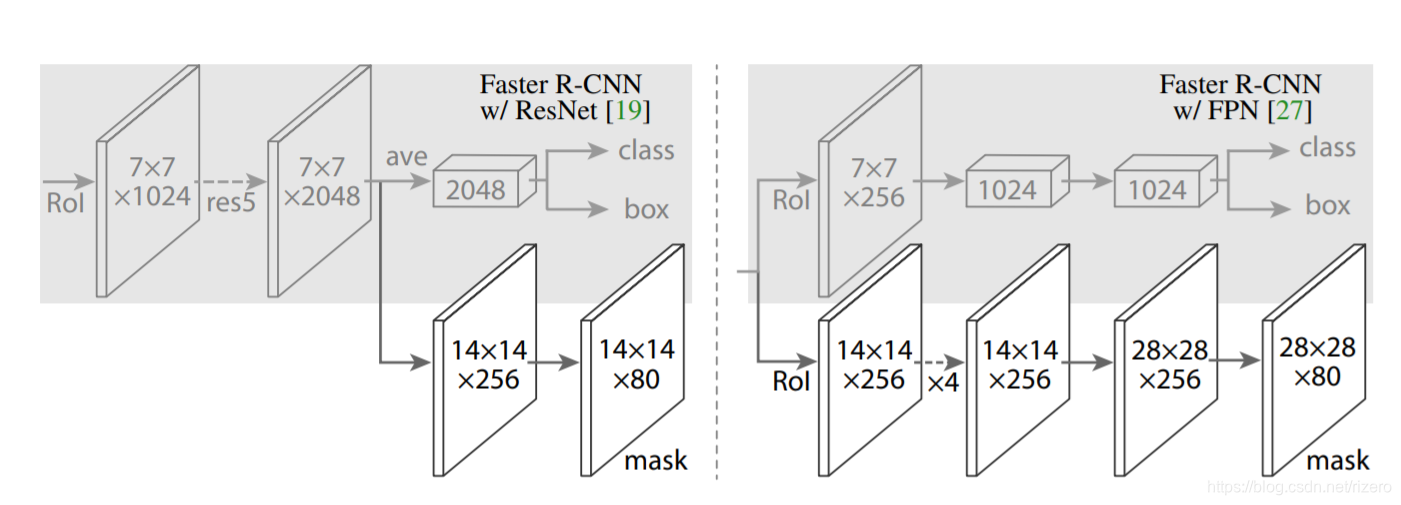
文中对使用resnet和FPN进行像素分割的效果做了比较,发现FPN更好。
6. 论文:Mask Scoring R-CNN(Mask-R-CNN的改进版)
我的印象:
- 网络结构:
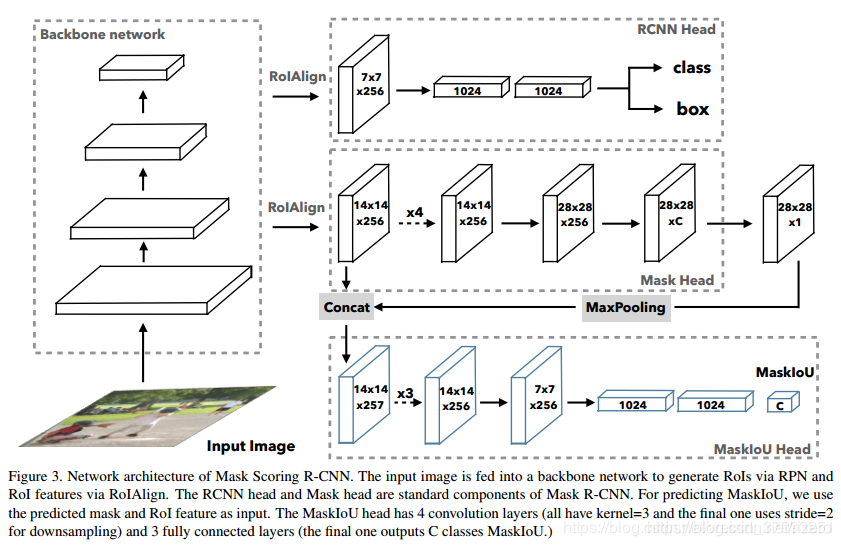
- 解释:
上面整体上还是Mask-R-CNN的东西,下面把Iou也作为训练的对象,也就是说网络同时完成多了一个预测输出Mask和ground Truth的Iou值预测。
5. 论文:Hybrid Task Cascade
我的印象:引入了级联优化策略
方法用于静态图像分割
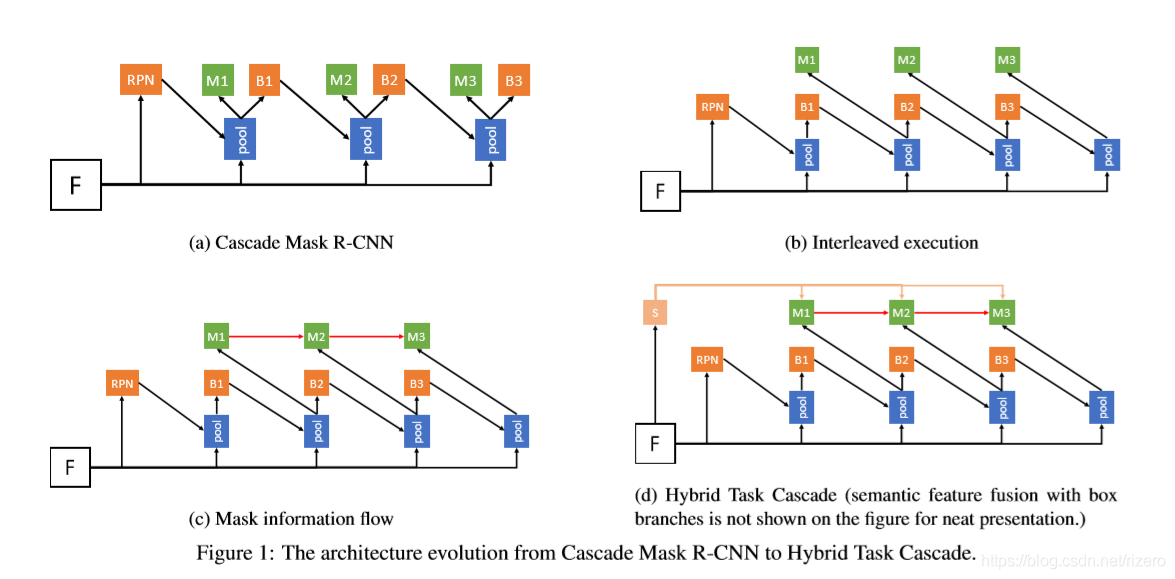
这个图看起来实在不舒服,B代表背景,F代表图像,M代表中间结果的蒙版。他不断通过级联筛选出背景信息以达到更好的分割效果。
4. 论文:RVOS-Recurrent Network
我的印象:对每一帧都用一次静态分割,但他能完成多实例分割任务
- 效果
- 网络结构:
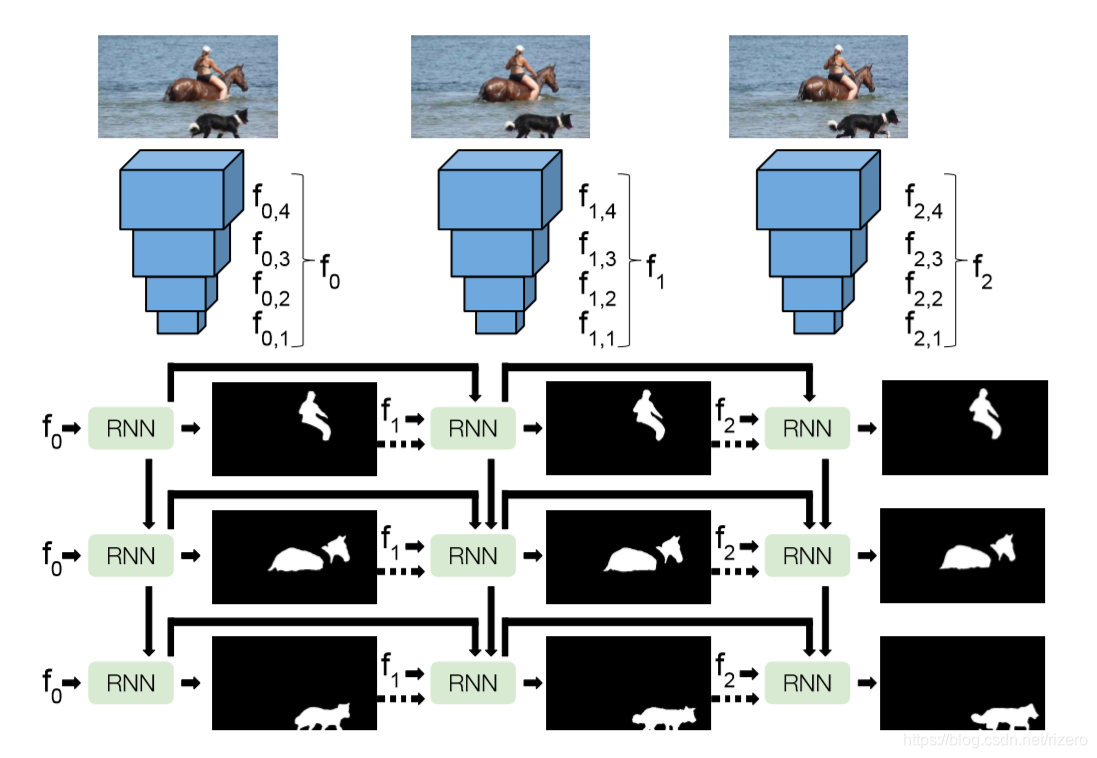
思想:对每一帧都用用一次RNN静态分割,然后把上一帧的蒙版也作为网络输入。
3. 论文:S4Net
我的印象:把负的背景信息保留在网络训练
属于单帧图像分割任务
-效果:

- 网络结构:
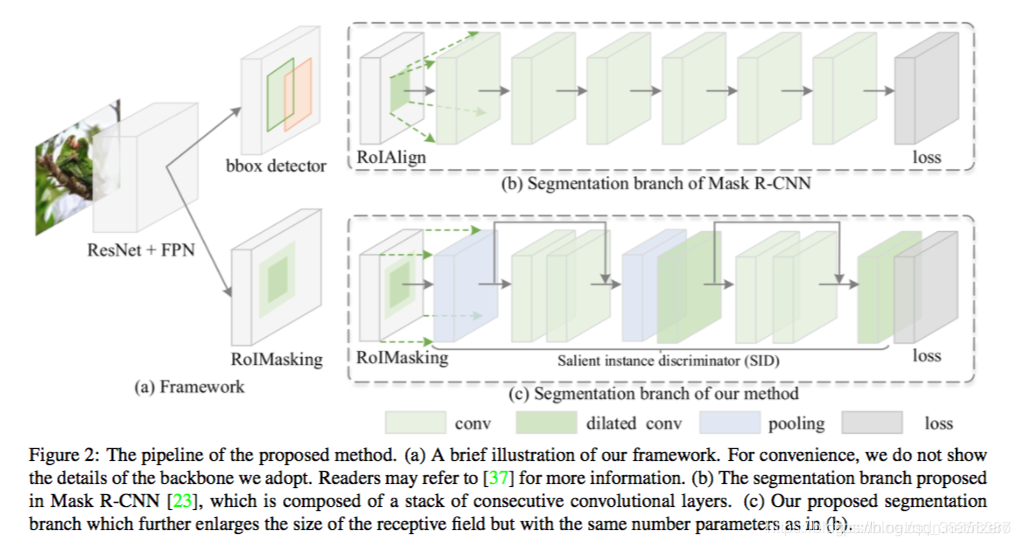
上面是mask-r-cnn,下面是s4net,他的最大特点在于ROImasking,并没有像mask-R-cnn把背景信息删掉只留下ROI,而是把背景作为”负“影响继续留存在网络当中。
这种方法属于目标检测方向的实例分割的一种分支。
2. 论文:Interactive Full Image Segmentation
我的印象:把交互信息变成连点预测边缘
- 效果:
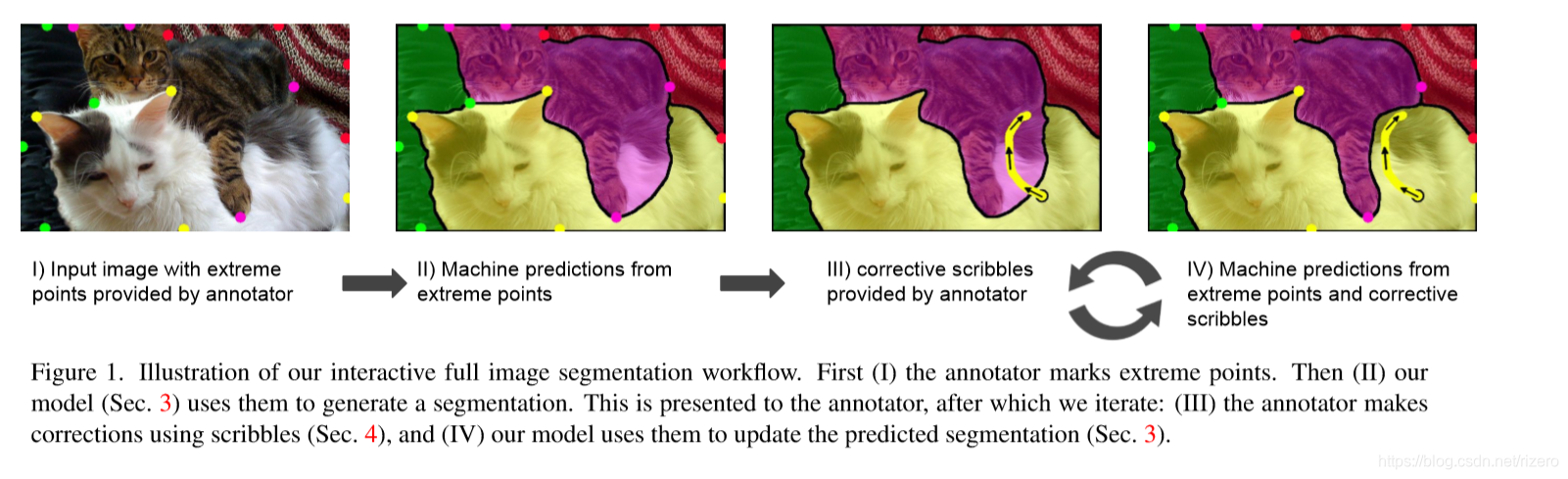
- 网络结构
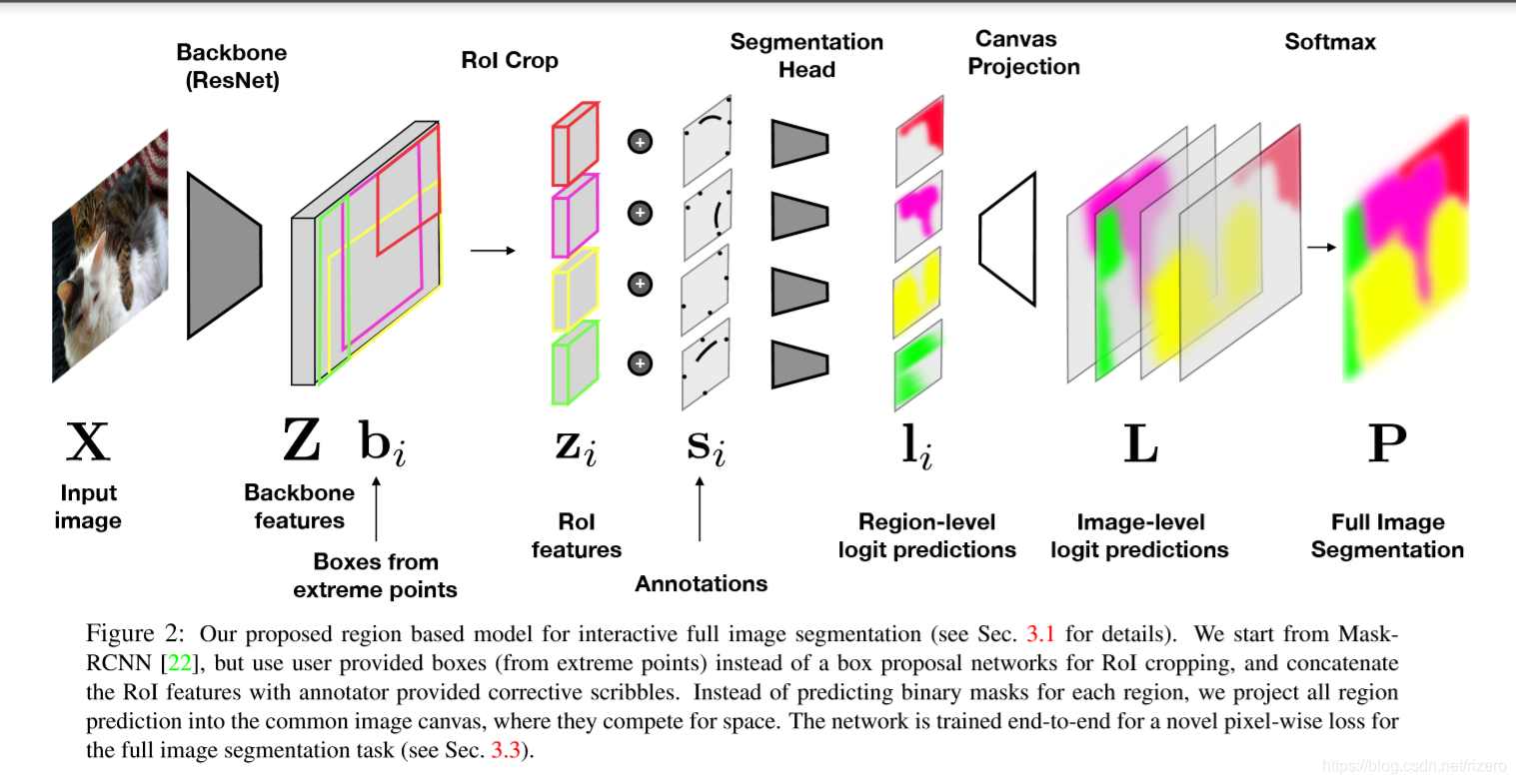
实际上,要求用户给出在边缘分割点的交互信息,就变成了一个连线预测问题。
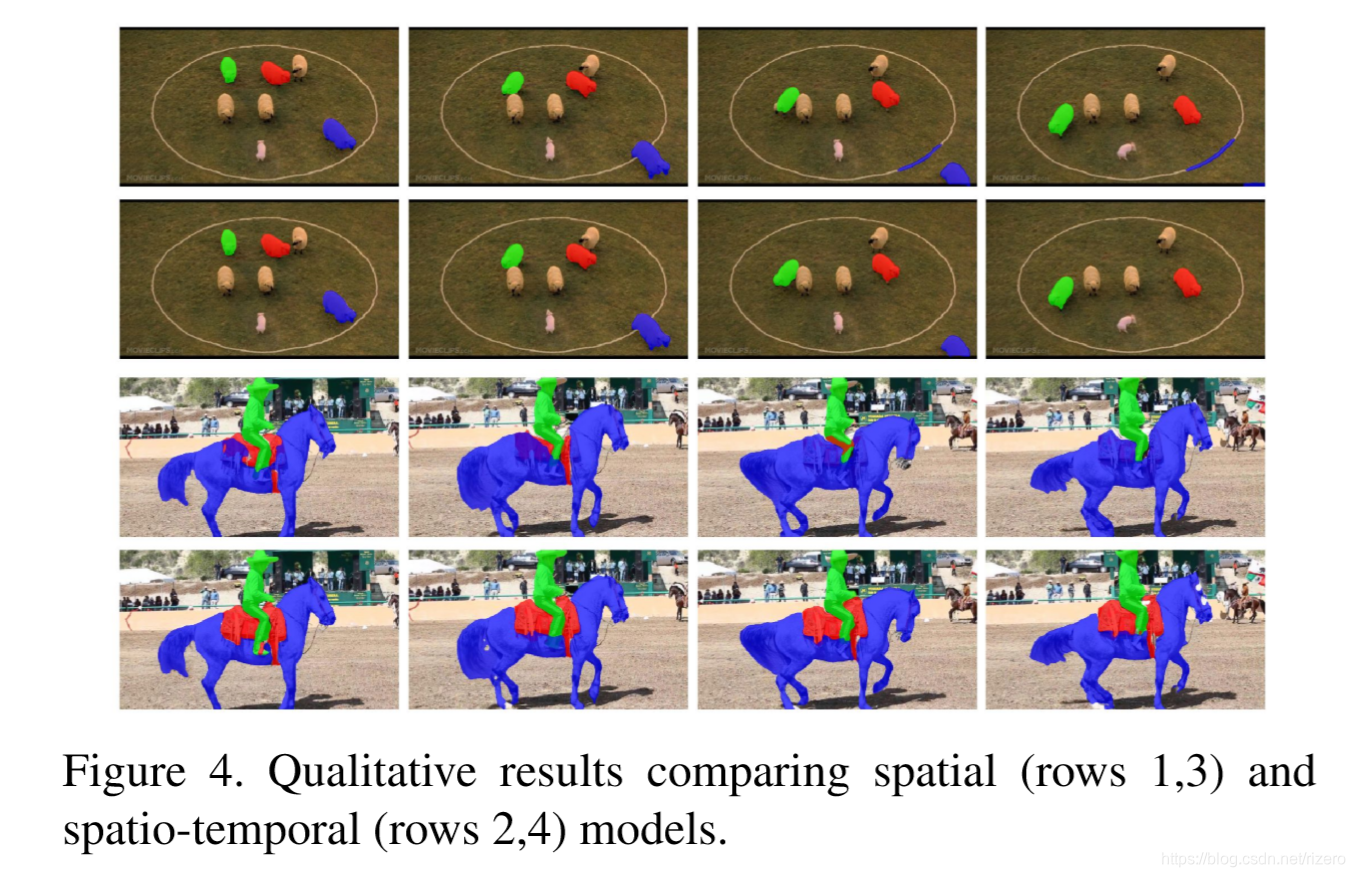
1. 论文:Spatiotemporal CNN
我的印象:对细节表现非常不错
- 效果:

注意这个效果:


- 网络结构:
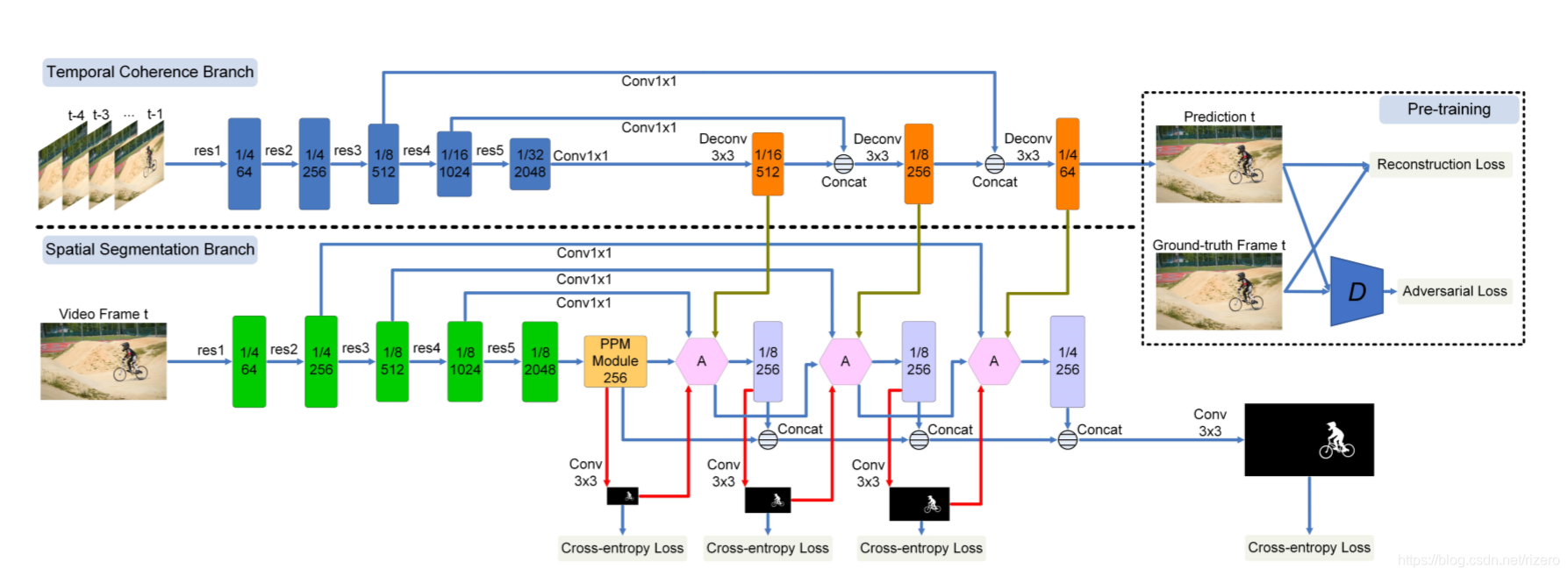
虚线上方的部分是时间相干分支,虚线下方的部分是空间分割分支。 红线表示模型中使用的注意力机制,六边形表示注意力模块。 每个卷积层之后是批处理归一化层和ReLU层。
…
(未写完。。。。) - 六边形注意力模块
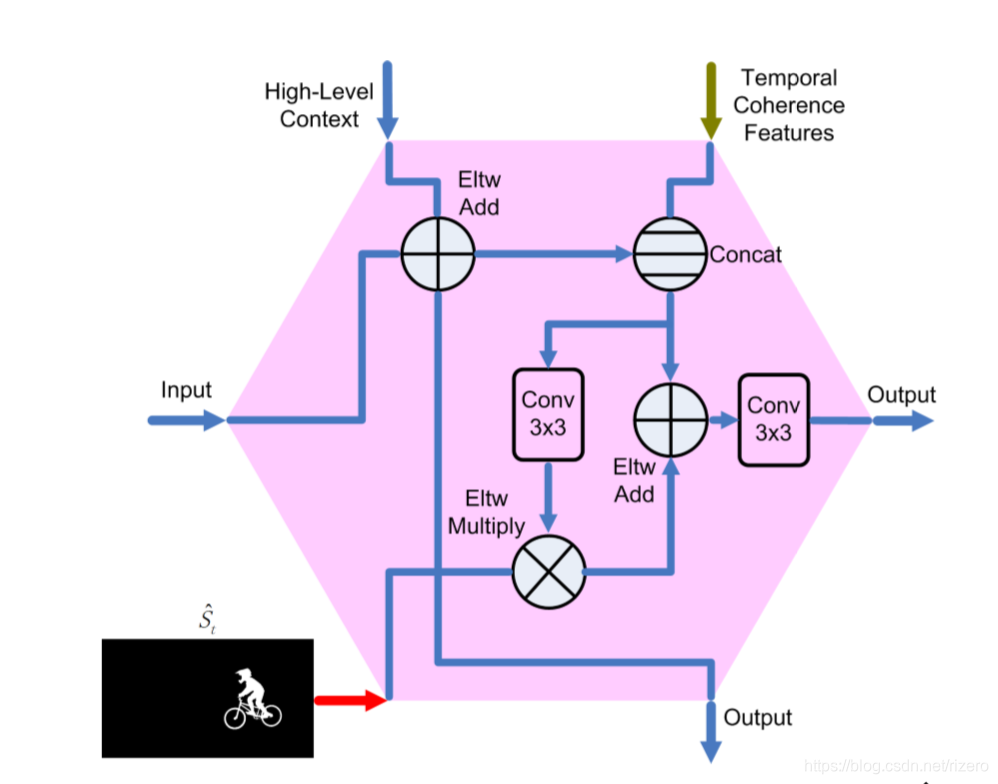
未完待续。。。

















 7688
7688




 到【灌水乐园】发言
到【灌水乐园】发言







