




 本文深入探讨了逻辑回归在二分类问题中的应用,解释了为何线性分类器表现不佳,并介绍了Sigmoid函数如何确保预测值在0和1之间。文章还详细解析了分类问题的损失函数,以及使用高级优化器如BFGS和L_BFGS的优势。最后,讨论了如何将多分类问题转化为多个二分类问题。
本文深入探讨了逻辑回归在二分类问题中的应用,解释了为何线性分类器表现不佳,并介绍了Sigmoid函数如何确保预测值在0和1之间。文章还详细解析了分类问题的损失函数,以及使用高级优化器如BFGS和L_BFGS的优势。最后,讨论了如何将多分类问题转化为多个二分类问题。
二分类问题
我们所说的逻辑回归问题实际上是分类问题的一种,并不是回归问题,这是历史遗留原因
y∈y\iny∈ {0,1}
Negative class 和Positive class
为什么线性分类器在分类问题表现不好?
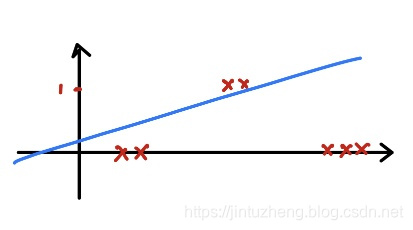
引入逻辑回归模型
我们需要满足:
0≤h(θ)≤10 \leq h(\theta)\leq10≤h(θ)≤1
而我们之前设置的回归假设函数:Z=θXZ=\theta XZ=θX
引入一个特别的函数模型:Sigmoid 函数模型:G(z)=11+e−zG(z)=\frac{1}{1+e^{-z}}G(z)=1+e−z1
图像:
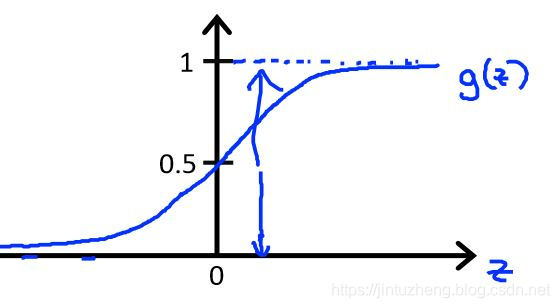
这样就能满足 0≤h(θ)≤10 \leq h(\theta)\leq10≤h(θ)≤1 了。
分类问题的损失函数
由于我们所使用的Sigmoid函数是非线性函数,假如使用我们之前的那个损失函数会导致出现多个局部谷点,难以收敛,我们必须为其重新设计一个。根据统计学的极大似然统计得到有一个函数
Cost(hθ(x),y)=−ylog(hθ(x))−(1−y)log(1−hθ(x))Cost(h_\theta(x),y)=-ylog(h_\theta(x))-(1-y)log(1-h_\theta(x))Cost(hθ(x),y)=−ylog(hθ(x))−(1−y)log(1−hθ(x))
因为我们的 y 只有两种值,要不就是0 和 1。
实际上这个函数可以分为:
Cost(hθ(x),y)={−log(hθ(x))if y=1−log(1−hθ(x))if y=0 Cost(h_\theta(x),y)= \begin{cases} -log(h_\theta(x)) & \text{if } y=1 \\ -log(1-h_\theta(x)) & \text{if } y=0 \end{cases} Cost(hθ(x),y)={−log(hθ(x))−log(1−hθ(x))if y=1if y=0
示例:当 y=1 的图像 Cost(hθ(x),y)=−log(hθ(x))Cost(h_\theta(x),y)=-log(h_\theta(x))Cost(hθ(x),y)=−log(hθ(x))
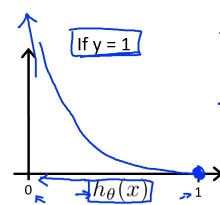
一旦误判足够严重,惩罚会非常大。 hθ(x)→0,Cost→+∞h_\theta(x)\rightarrow0,Cost\rightarrow+\inftyhθ(x)→0,Cost→+∞
梯度下降算法外的高级优化器
我们之前学习到的梯度下降算法都是我们手动选择学习率,但像:
- Conjugate gradient
- BFGS
- L_BFGS
这些算法无需手动选择学习率,使用这些高级算法进行优化将会收敛更快。不要自己手动尝试去实践这些算法。
多分类问题
我们只需要把多分类问题转化成多个二分类问题即可,比如我们需要分出3类,那么我们将使用3个二分类器。
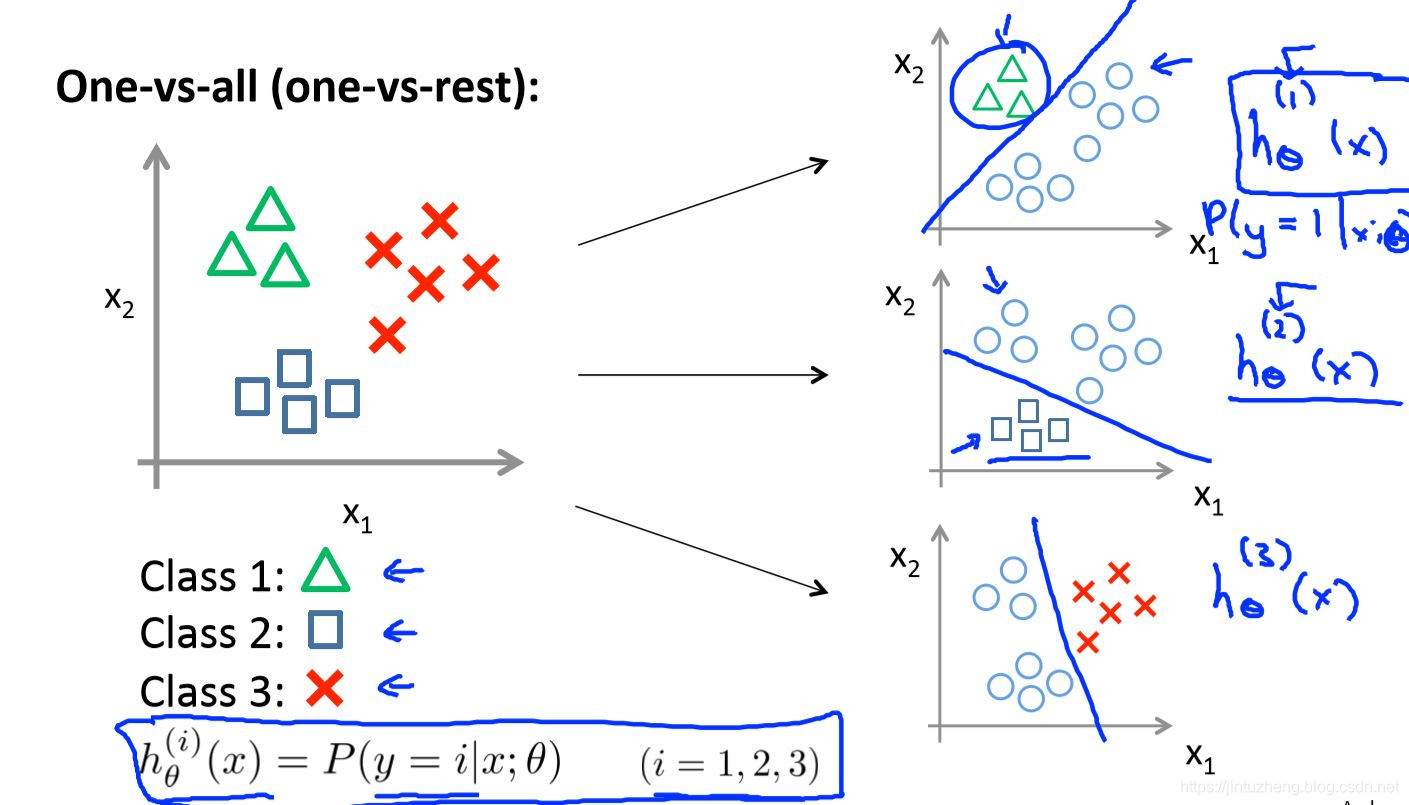
输入XinputX_{input}Xinput ,只需要选择 maxihθi(X)\max_{i}h^{i}_\theta(X)maxihθi(X) 作为预测输出即可。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









