




文章目录
一、项目简介
获取项目源码方式:关注公众号《英博的AI实验室》,回复deepresearch即可
一句话总结:Deepresearch Fullstack LangGraph Quickstart 是基于gemini-deepresearch项目的二次开发项目,采用 React 前端与 LangGraph 智能体后端的全栈应用示例。该项目展示了如何利用自有或公开大模型与LangGraph 框架,构建具备“研究增强”能力的对话式 AI 系统。其核心亮点在于:智能体能够动态生成搜索词,自动调用 Google Search 进行网络检索,反思结果、发现知识缺口,并多轮迭代直至给出带有引用的高质量答案。
项目适合开发者快速上手 LangGraph 智能体开发、理解前后端协作模式,以及探索 LLM 在自动化研究场景下的应用。
- 项目展示

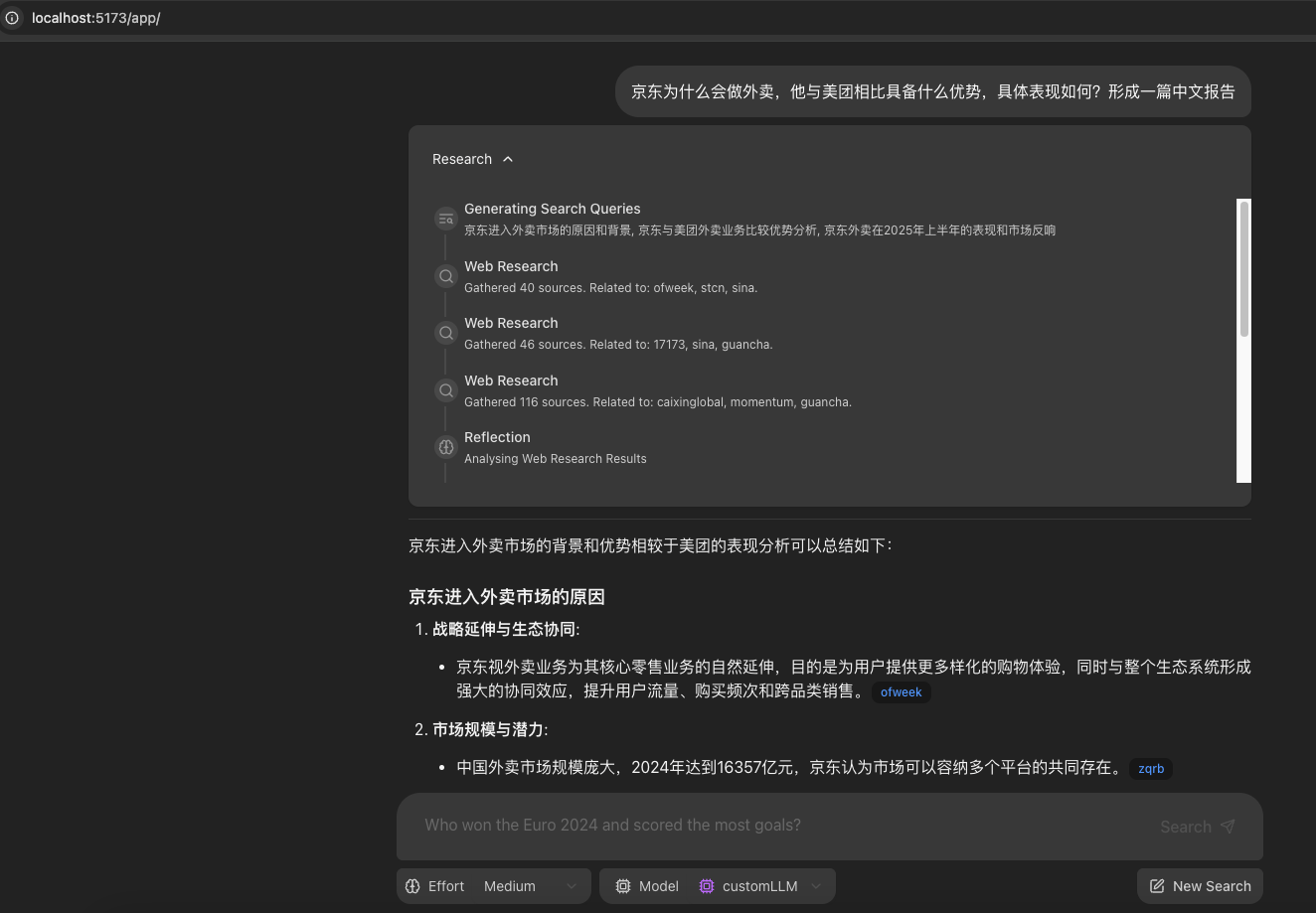
二、核心功能与特性
- 💬 前后端分离的全栈架构(React + LangGraph/FastAPI)
- 🧠 LangGraph 智能体驱动,具备复杂推理与多轮研究能力
- 🔍 LLM 动态生成搜索词,自动调用 Google Search API
- 🌐 网络检索与知识反思,自动发现并弥补知识盲区
- 📄 生成带引用的高质量答案
- 🔄 后端支持任意大模型接入,并适配langgraph-llm的接口,实现私有化定制,支持Langsmith动态跟踪调试
- 🔄 前端同步支持任意大模型接入,与后端协同,以热加载的形式实现部署,提升开发效率
- 🐳 支持 Docker 一键部署,生产环境可用
三、项目结构与架构设计
项目采用典型的前后端分离架构:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 304
304

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









