



快手 TWIN
研究动机
长期行为序列建模的方法采取一种两阶段的范式:GSU和ESU。两阶段的方法面临的主要问题是阶段一致性问题,即一阶段筛选出的行为,并不一定是二阶段所认为的高度相关的行为。如果一阶段不能精确的筛选行为,那么无论二阶段如何设计良好的attention机制,其效果也只能是次优的
这篇论文就提出了两阶段一致的终身行为序列建模方法,称为TWIN
解决方案
TWIN解决一致性问题的思路是如何提升MHTA的计算效率,减少计算量,从数百个序列长度扩展到数万个序列长度
提升Multi-Head Target Attention计算效率的一个思路是能否减少其计算量,将其中的一些计算提前算好并进行存储?MHTA涉及到Q、K、V的计算,以及Q、K的attention的计算,以及attention和V的计算几个过程。那么我们来分析下哪些是线上推理可以减少的计算过程。
1)Q的计算依赖于target item,这块肯定是线上推理所必须的,不可减少,但只用计算一次。
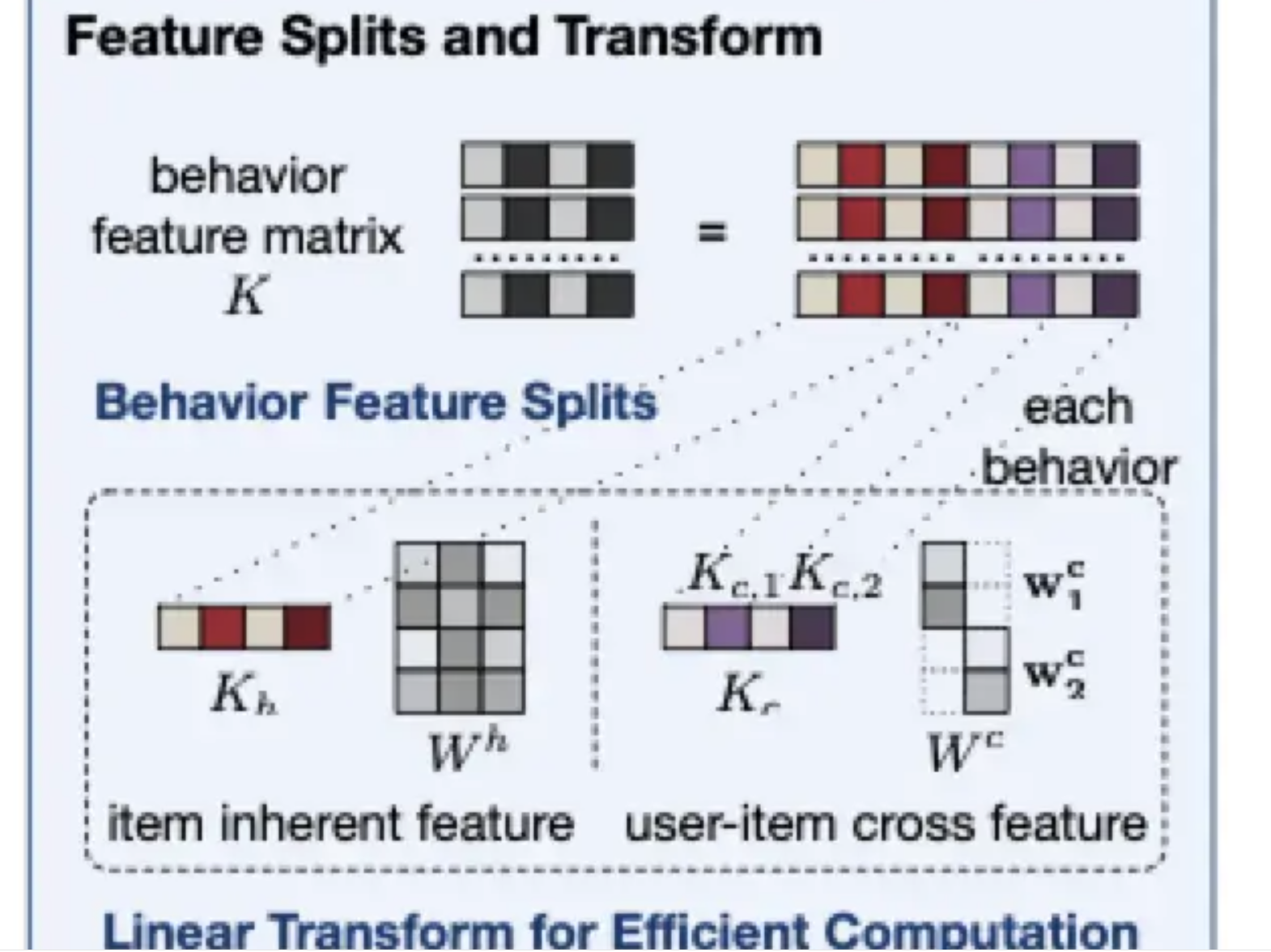
2)K的计算如果包含一些用户相关的特征如user-item的交叉特征等,是不能减少其线上推理计算量的,但如果特征中全是item自身的特征,不包含用户以及上下文信息,那么这块是可以提前计算并进行存储的,线上直接抽取即可。从这个角度出发,论文提出了特征拆分的思路。
3)V的计算可以放在attention计算之后,即放在ESU阶段,只对attention score最高的top行为计算即可,同时无需进行特征拆分。
4)attention计算:内积的方式,这部分耗时其实和SIM-soft是一样的
5)attention和V计算的到用户兴趣表示:ESU阶段计算,暂不考虑。从上述分析可以看出,主要的优化思路是,通过特征拆分和线性映射,快速计算Q和K的attention score。
特征拆分和线性映射
特征拆分的主要思路是将item的特征拆解为item的固有属性Kh如item id、作者、主题等和item-user交叉特征Kc如用户的观看时长等。对于固有属性,可以提前计算KhWh并进行存储,线上推理不再进行额外计算;对于交叉特征,通过简单的线性映射,作为偏置项加入到最终的attention score中。特征拆分和attention score的计算如下:
通过上述的两部分来计算attention score,兼顾了相关性和用户的兴趣程度:
1)对于target item,只能拿到固有属性信息,而user-item的交互信息属于穿越特征,线上无法获取。因此第一部分只使用固有属性信息,这可以看作是从相关性角度计算attention score,如品类、作者是否相同。
2)第二部分偏置项可以看作是从用户的兴趣程度出发,计算attention score,如两个相关性相同的视频(如作者、时长、类型相同),用户观看时间长的视频是更感兴趣的,那么优先筛选观看时间长的视频。
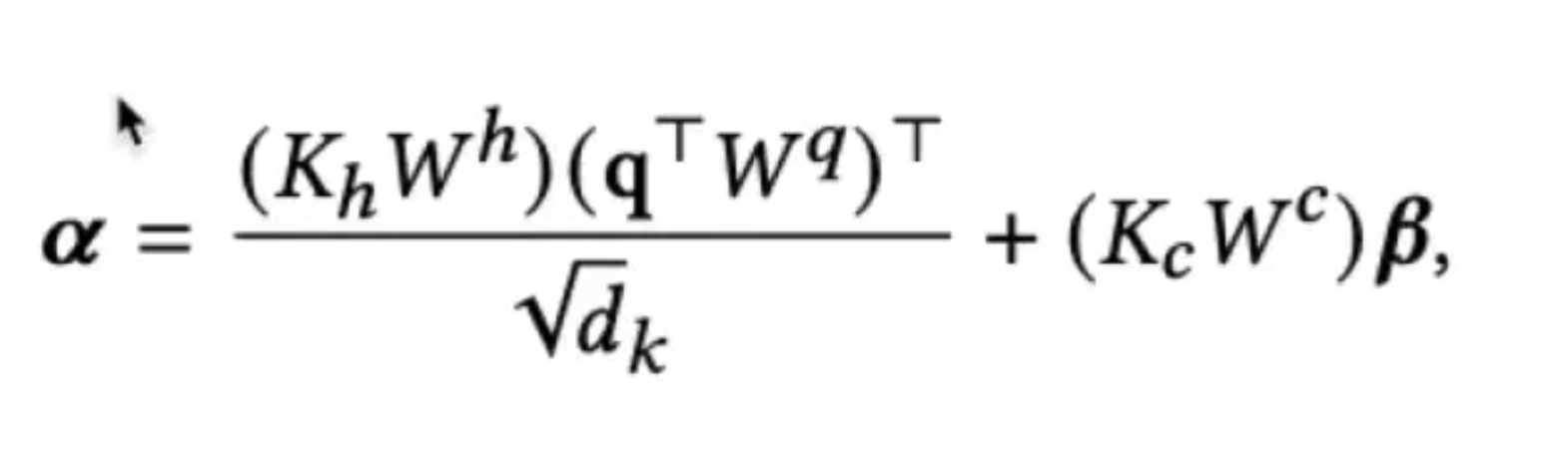
快手 TWIN V2
同样采用两阶段的范式,TWIN-V2(TWIN的增强版本),通过聚类来压缩长期行为序列的长度,并发现更准确和多样化的用户兴趣。
在离线阶段,分层聚类方法将长期行为序列中相似的item分到一个簇中。通过限制簇的大小,可以将行为序列长度压缩,以便于GSU检索中的在线推理
聚类感知的target attention提取用户的长期兴趣,从而使最终的推荐结果更加准确和多样化
TWIN-v2包括离线和在线两部分,主要关注行为建模部分,由于整个生命周期的行为对于在线推断来说太长了
在离线阶段压缩长期行为序列。用户行为通常包括许多类似的视频,因为用户经常浏览他们喜欢的主题。因此,采用分层聚类将每个用户历史中具有相似兴趣的item聚合到同一个聚类中
首先根据完播率将item分为不同的组(作者实际使用时是M=5组)
递归地对每个组的长期交互行为进行聚类,直到每个聚类中的item数量不超过gamma
将每个聚类压缩成一个向量表征,对于数值特征取均值,对于类别型特征,采用距离聚类中心最近的item的特征
在线推断使用这些聚类及其表征向量来捕捉用户的长期兴趣。在在线推理过程中,首先,使用GSU从聚类行为中检索与目标item相关的(对)前100个聚类,然后使用ESU从这些聚类中提取长期兴趣
这部分也采用TWIN中的特征拆分和线性映射 实现QK的快速计算
由于不同聚类簇中的item个数并不相同,拥有更多item的聚类是更重要的,

















 943
943

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









