




 本文详细介绍了DICOM通讯中的Worklist交互过程,包括A-ASSOCIATE-req和A-ASSOCIATE-ac的建立连接,以及C-FIND-RQ和C-FIND-RSP的C-FIND服务请求与响应。通过Wireshark抓包并设置过滤条件,展示了如何解析PDU和PDVs。关键词涉及:DICOM, TCP/IP, A-ASSOCIATE, C-FIND, PDV, 数据流, wireshark
本文详细介绍了DICOM通讯中的Worklist交互过程,包括A-ASSOCIATE-req和A-ASSOCIATE-ac的建立连接,以及C-FIND-RQ和C-FIND-RSP的C-FIND服务请求与响应。通过Wireshark抓包并设置过滤条件,展示了如何解析PDU和PDVs。关键词涉及:DICOM, TCP/IP, A-ASSOCIATE, C-FIND, PDV, 数据流, wireshark
下文中的worklist交互的测试数据,请在资源中下载,需要wireshark将文件打开,并且加入过滤条件ip.addr == 192.168.2.193 and tcp.port == 104 ,并且选择dicom协议。
1 DICOM通讯概要介绍
DICOM通讯和TCP IP的设计原理别无二致。从用户数据发送到网络上的数据的过程中,要经历多层协议处理,每经一层,就会加入用来描述当前层含义的数据字段,例如,我们熟悉的TCP层,会在用户的数据流前,加入目标端口,源端口,TCP层用来模拟链接通道的Sequence Number和Acknowlegment Number等的字段。
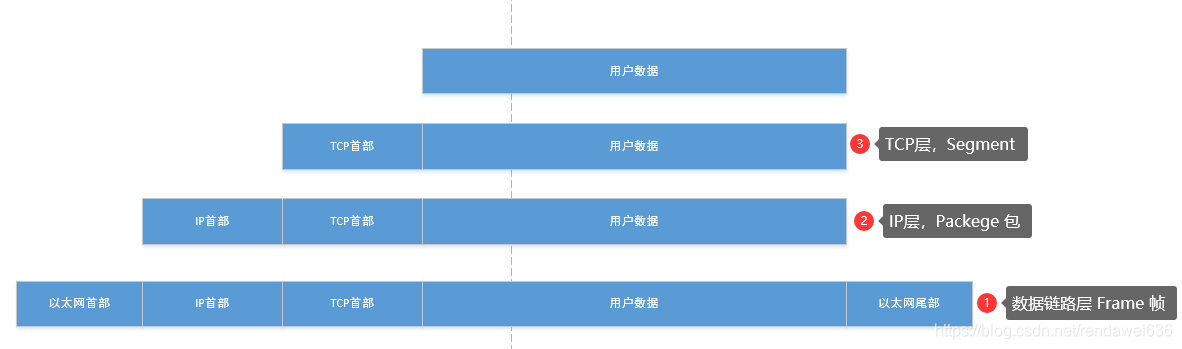
在DICOM通讯中,当数据通过TCP层后,数据流就进入了DICOM的会话层(ACSE),详细介绍可在标准第8章中。ACSE(Association Control Service Element),包含了7种类型的协议数据单元,分别是A-ASSOCIATE-RQ PDU(Protocol Data Units),A-ASSOCIATE-AC PDU,A-ASSOCIATE-RJ PDU,P-DATA-TF PDU,A-RELEASE-RQ PDU,A-RELEASE-RP PDU,A-ABORT PDU。这些服务数据单元构成了ACSE服务组。解析数据流时,当第一个字节的值是4的时候,就代表PDU是一个P-DATA类型,应当由DIMSE层来处理;相反,如果是其他值,就属于a-associate-rq, a-associate-rj, a-associate-ac, a-release-rq, a-release-rsp, a-abort6种类型PDU中的一种,直接在ACSE层内进行处理。具体的解析过程,第二章节中,以一个Modality Worklist(C-Find)的例子来介绍。
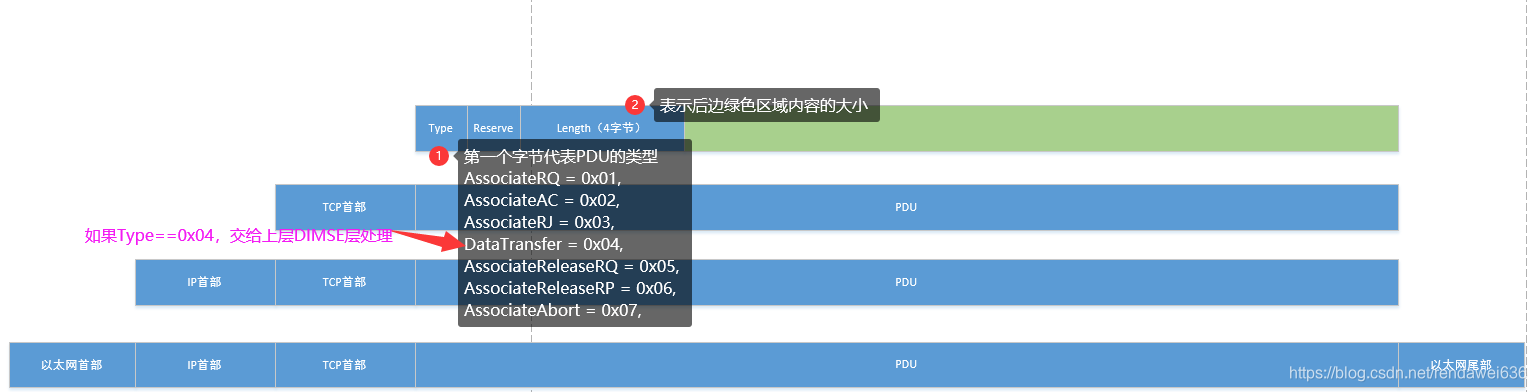
当会话层接收到PDU,并且PDU的Type是4的时候,ACSE层协议,擦掉PDU头信息,将信息流变为PDVs(Presentation Data Values )后,将数据流交给表示层来解析。详细介绍,可参考第七章。在表示层DIMSE层中,提供了C-Find, C-Store, C-Move, C-Get, C-Echo, N-EVENT-R
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6260
6260






 到【灌水乐园】发言
到【灌水乐园】发言







