







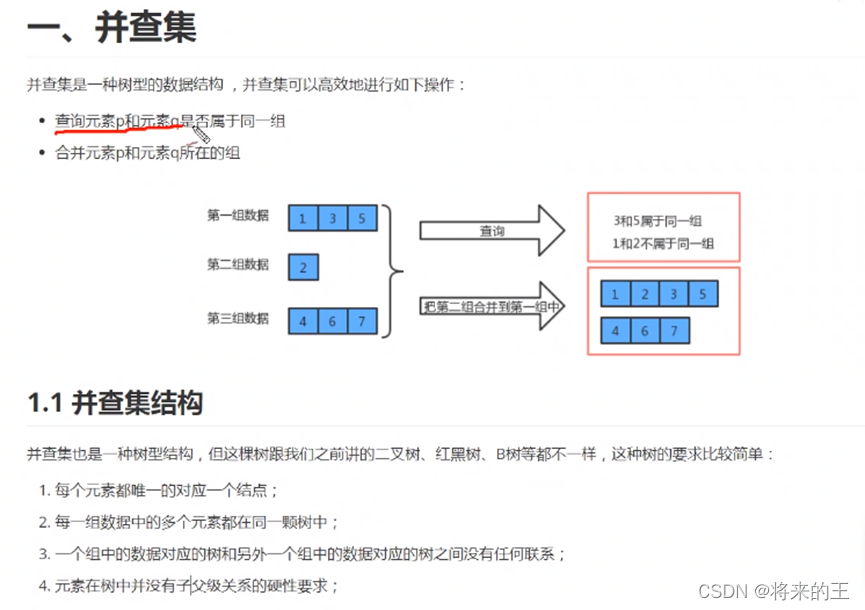
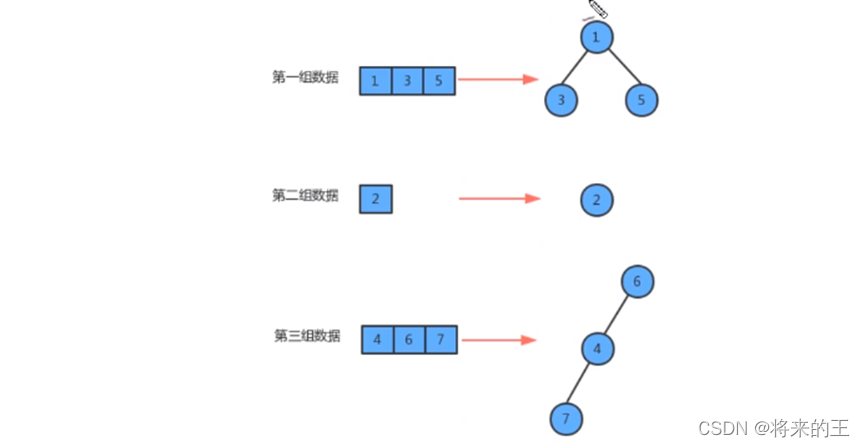
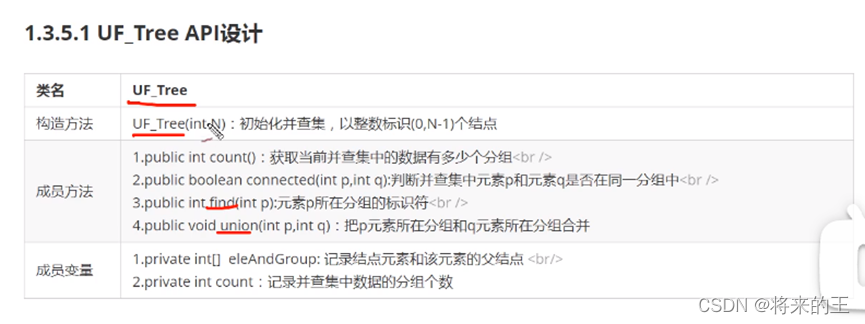
1.知识储备:
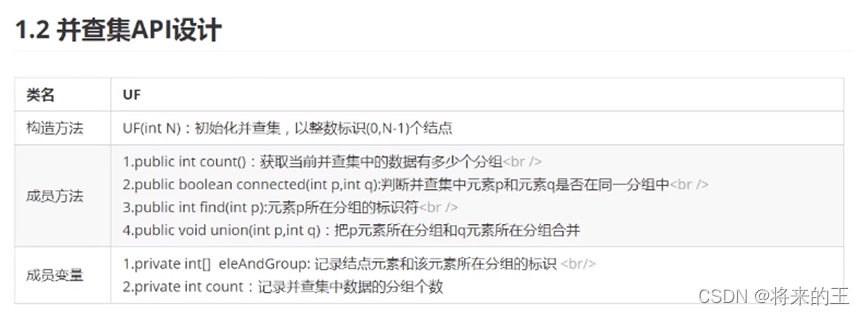
2.API设计:

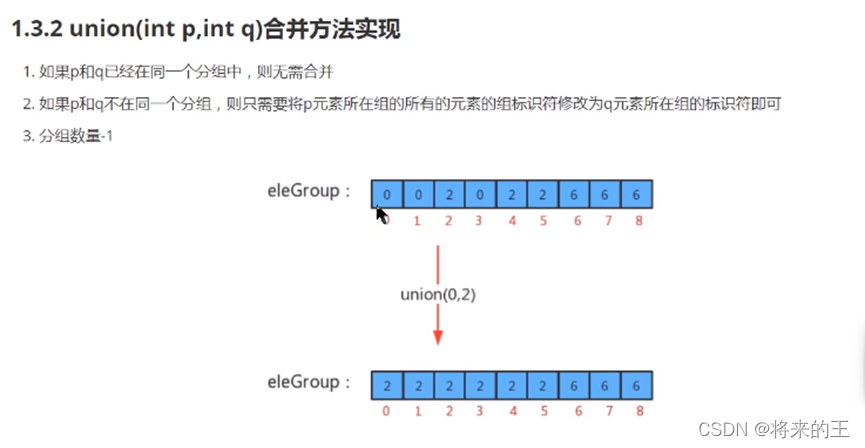
3.实现代码:
package UnionFindAsseble;
public class UF {
//记录节点元素和该元素所在的分组标识
private int[] eleAndGroup;
//记录并查集中元素的分组个数
private int count;
//初始化并查集
public UF(int N) {
// TODO Auto-generated constructor stub
//初始化分组数量,默认情况下有N个数组
this.count=N;
//初始化eleAndGroup数组
this.eleAndGroup=new int[N];
//初始化eleAndGroup中的元素极其所在的数组标识符,让eleAndGroup数组的索引作为并查集的每个节点元素,并且让每个索引处的值(改元素所在的数组标识符)就是该索引
for(int i=0;i<eleAndGroup.length;i++){
eleAndGroup[i]=i;
}
}
//获取当前并查集中数据有多少个分组
public int count(){
return count;
}
//元素p所在的分组标识符
public int find(int p){
return eleAndGroup[p];
}
//判断并查集中元素p和q是否处于同一个分组中
public boolean connected(int p,int q){
return find(p)==find(q);
}
//把p元素所在的分组和q元素所在的分组合并
public void union(int p,int q){
//判断元素q和p是否已经在同一个分组中
if(connected(p, q)){
return;
}
//找到p所在的分组标识符
int pGroup=find(p);
//找到q所在的分组标识符
int qGroup=find(q);
//合并组:让p所在组的所有元素的组标识符变为q所在组的标识符
for(int i=0;i<eleAndGroup.length;i++){
if(eleAndGroup[i]==pGroup){
eleAndGroup[i]=qGroup;
}
}
//分组个数-1
this.count--;
}
}
4.测试案例:
package UnionFindAsseble;
import java.util.Scanner;
public class UFTest {
public static void main(String[] args) {
//创建并查集对象
UF uf=new UF(5);
System.out.println("默认情况下并查集中有:"+uf.count()+"个组");
//从控制台录入两个要合并的元素,调用union方法合并,观察合并后并查集中的分组是否减少
Scanner sc=new Scanner(System.in);
while(true){
System.out.println("请输入第一个要合并的元素:");
int p=sc.nextInt();
System.out.println("请输入第二个要合并的元素:");
int q=sc.nextInt();
//判断这两个元素是否在同一个组中
if(uf.connected(p, q)){
System.out.println(p+"元素和"+q+"元素已经在同一个组中!");
continue;
}
uf.union(p, q);
System.out.println("当前并查集中还有:"+uf.count()+"个组");
}
}
}
5.测试结果:

6.并查集的应用及优化:


代码实现:
package UnionFindAsseble;
public class UF_Tree {
//记录节点元素和该元素所在的分组标识
private int[] eleAndGroup;
//记录并查集中元素的分组个数
private int count;
//初始化并查集
public UF_Tree(int N) {
// TODO Auto-generated constructor stub
//初始化分组数量,默认情况下有N个数组
this.count=N;
//初始化eleAndGroup数组
this.eleAndGroup=new int[N];
//初始化eleAndGroup中的元素极其所在的数组标识符,让eleAndGroup数组的索引作为并查集的每个节点元素,并且让每个索引处的值存储该元素的父节点索引
for(int i=0;i<eleAndGroup.length;i++){
eleAndGroup[i]=i;
}
}
//获取当前并查集中数据有多少个分组
public int count(){
return count;
}
//找元素p的根节点
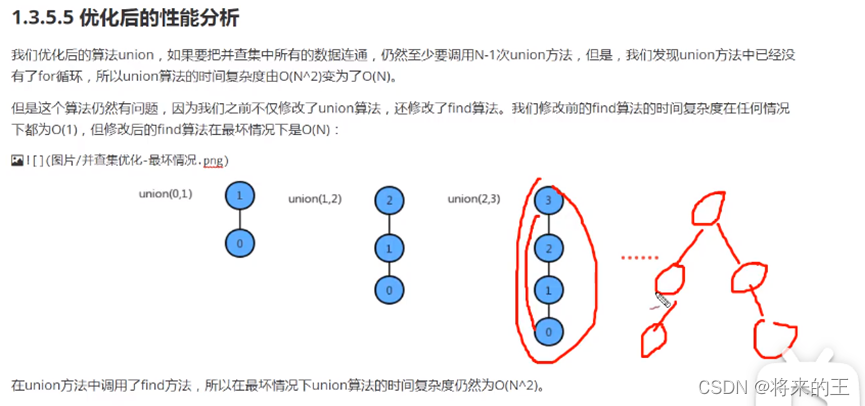
public int find(int p){
//如果一个元素的父节点是它本身,则说名该元素是根节点
while(true){
if(p==eleAndGroup[p]){
return p;
}
else
{
p=eleAndGroup[p];
}
}
}
//判断并查集中元素p和q是否处于同一个分组中
public boolean connected(int p,int q){
return find(p)==find(q);
}
//把p元素所在的分组和q元素所在的分组合并
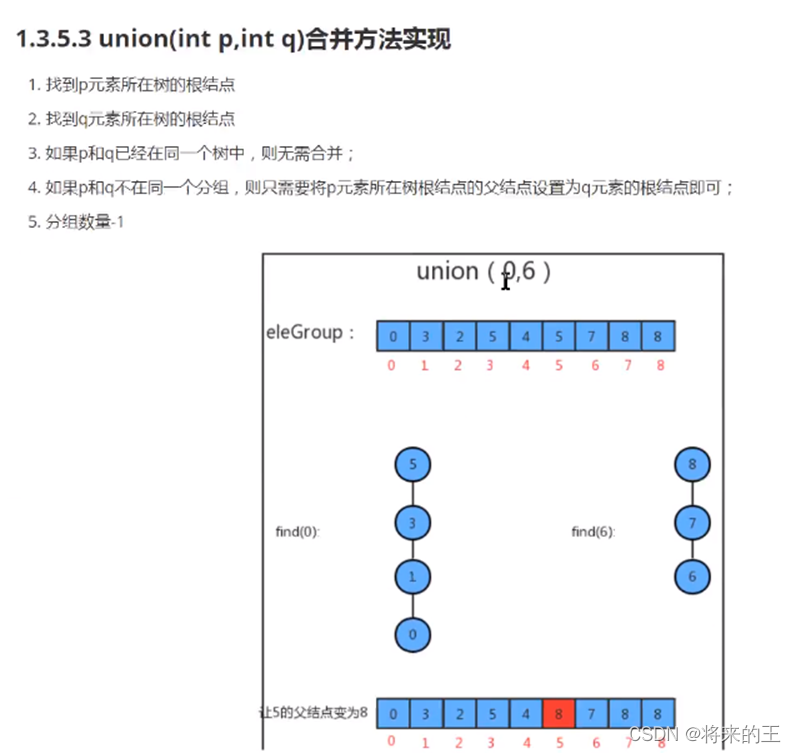
public void union(int p,int q){
//找到p元素和q元素所在组对应树的根节点
int pRoot=find(p);
int qRoot=find(q);
//如果p和q已经在同一个分组中则不需要合并
if(pRoot==qRoot){
return;
}
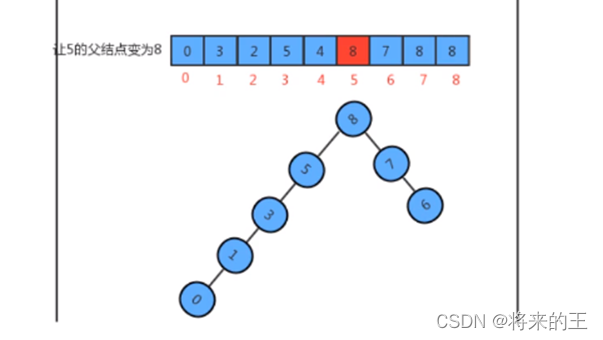
//让p所在树的根节点的父节点为q所在树的根节点即可
eleAndGroup[pRoot]=qRoot;
//组的数量-1
this.count--;
}
}
测试案例:
package UnionFindAsseble;
import java.util.Scanner;
public class UF_TreeTest {
public static void main(String[] args) {
//创建并查集对象
UF_Tree uf=new UF_Tree(5);
System.out.println("默认情况下并查集中有:"+uf.count()+"个组");
//从控制台录入两个要合并的元素,调用union方法合并,观察合并后并查集中的分组是否减少
Scanner sc=new Scanner(System.in);
while(true){
System.out.println("请输入第一个要合并的元素:");
int p=sc.nextInt();
System.out.println("请输入第二个要合并的元素:");
int q=sc.nextInt();
//判断这两个元素是否在同一个组中
if(uf.connected(p, q)){
System.out.println(p+"元素和"+q+"元素已经在同一个组中!");
continue;
}
uf.union(p, q);
System.out.println("当前并查集中还有:"+uf.count()+"个组");
}
}
}
压缩路径实现:

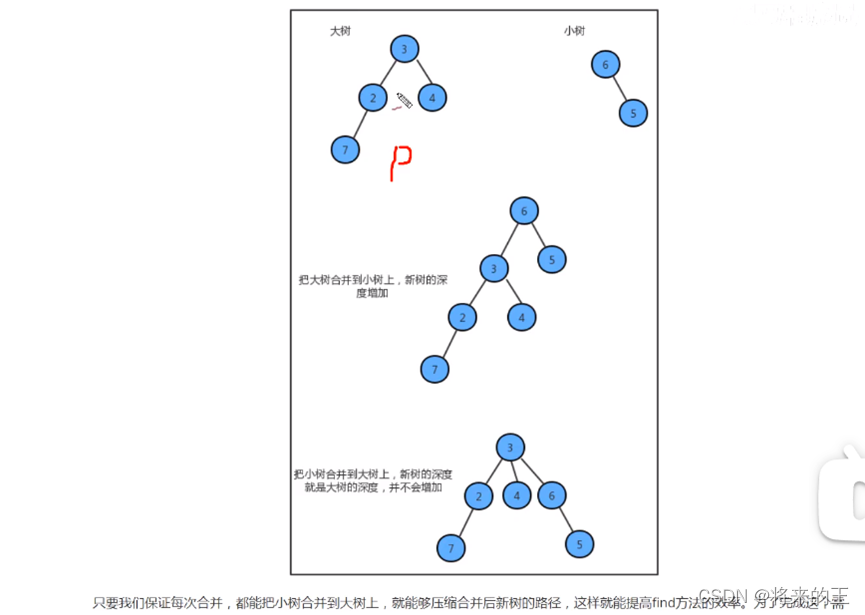

package UnionFindAsseble;
public class UF_Tree_Weighted {
//记录节点元素和该元素所在的分组标识
private int[] eleAndGroup;
//用来记录每一个根节点对应的树中节点的个数
private int[] size;
//记录并查集中元素的分组个数
private int count;
//初始化并查集
public UF_Tree_Weighted(int N) {
// TODO Auto-generated constructor stub
//初始化分组数量,默认情况下有N个数组
this.count=N;
//初始化eleAndGroup数组
this.eleAndGroup=new int[N];
//初始化eleAndGroup中的元素极其所在的数组标识符,让eleAndGroup数组的索引作为并查集的每个节点元素,并且让每个索引处的值存储该元素的父节点索引
for(int i=0;i<eleAndGroup.length;i++){
eleAndGroup[i]=i;
}
this.size=new int[N];
//默认情况下,size中每个索引处的值都是1
for(int i=0;i<size.length;i++){
size[i]=1;
}
}
//获取当前并查集中数据有多少个分组
public int count(){
return count;
}
//找元素p的根节点
public int find(int p){
//如果一个元素的父节点是它本身,则说名该元素是根节点
while(true){
if(p==eleAndGroup[p]){
return p;
}
else
{
p=eleAndGroup[p];
}
}
}
//判断并查集中元素p和q是否处于同一个分组中
public boolean connected(int p,int q){
return find(p)==find(q);
}
//把p元素所在的分组和q元素所在的分组合并
public void union(int p,int q){
//找到p元素和q元素所在组对应树的根节点
int pRoot=find(p);
int qRoot=find(q);
//如果p和q已经在同一个分组中则不需要合并
if(pRoot==qRoot){
return;
}
//判断proot对应的树大还是qroot对应的树大,最终要把较小的树合并到较大的树中去
if(size[pRoot]<size[qRoot]){
eleAndGroup[pRoot]=qRoot;
//让根节点对应的树种的元素个数变为合并后的元素个数
size[qRoot]+=size[pRoot];
}else{
eleAndGroup[qRoot]=pRoot;
//让根节点对应的树种的元素个数变为合并后的元素个数
size[pRoot]+=size[qRoot];
}
//组的数量-1
this.count--;
}
}
测试案例:
package UnionFindAsseble;
import java.util.Scanner;
public class UF_Tree_WeightedTest {
public static void main(String[] args) {
//创建并查集对象
UF_Tree_Weighted uf=new UF_Tree_Weighted(5);
System.out.println("默认情况下并查集中有:"+uf.count()+"个组");
//从控制台录入两个要合并的元素,调用union方法合并,观察合并后并查集中的分组是否减少
Scanner sc=new Scanner(System.in);
while(true){
System.out.println("请输入第一个要合并的元素:");
int p=sc.nextInt();
System.out.println("请输入第二个要合并的元素:");
int q=sc.nextInt();
//判断这两个元素是否在同一个组中
if(uf.connected(p, q)){
System.out.println(p+"元素和"+q+"元素已经在同一个组中!");
continue;
}
uf.union(p, q);
System.out.println("当前并查集中还有:"+uf.count()+"个组");
}
}
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









