



目录
Hierarchical Task Learning(HTL)
概述
GUPNet是一种3D目标检测网络,输入为单目相机图像,输出为检测到的目标的属性集合,支持多种类别如车辆、行人、锥桶等;输出的目标属性包括:1、目标的类别 2、目标的2D框、目标的3D框。
网络架构图
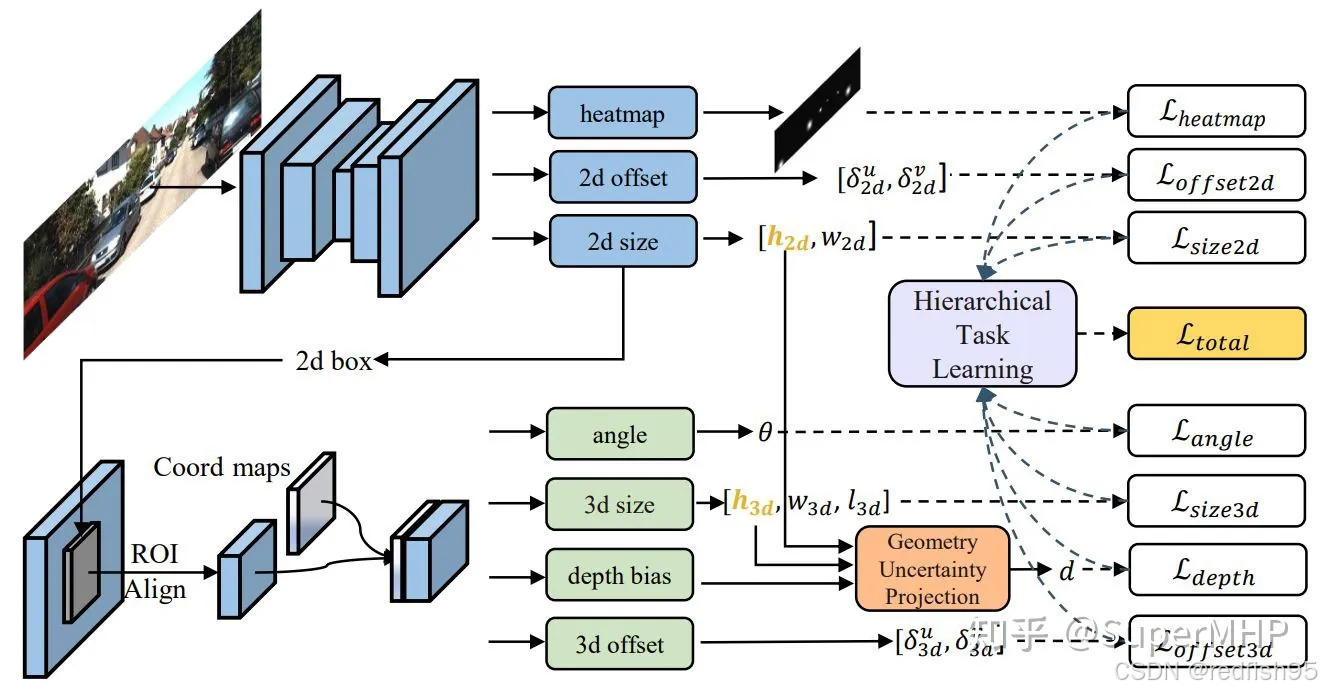
GUPNet是两阶段的目标检测框架,首先,图像数据通过backbone获取特征图,基于得到的特征图,首先会通过3个2D检测头来获取图像中的2D框,将检测到的2D框投影到特征图中,crop出对应的ROI特征,后通过ROI Align模块来得到固定尺寸的特征图,为了弥补抠图带来的位置信息的缺失,会在得到的特征图上拼接一层coord maps得到最终用于3D信息预测的特征图。在该特征图上接4个3D检测头来预测目标的3D信息,在得到的目标3D高度及2D框高后,由小孔成像原理来预测目标的深度信息,最终得到目标的所有预测信息。
基本算法思想
GUPNet的全称是Geometry Uncertainty Projection Network,即几何不确定度投影网络,该网络的特点就是在预测目标的深度时,采用了几何投影的先验知识并引入了不确定度的概念,从而提高了对目标深度的预测精度。网络的2D检测部分同Centernet一致,采用的是anchor-free的思路,即预测结果不预测锚框,通过一个对象框中心点的单个点来表示目标,其他属性,如2D框宽高,中心点偏移则直接通过图像特征回归,如下图所示,3D检测部分是该网络的主要创新点,模型首先估计出除深度外所有的参数,包括3D x和y在图像上相对heatmap的偏移量、3D边界框的尺寸等,然后将2D与3D 框的高度输入到GUP模块中提取出最终的深度。

heatmap部分
heatmap的概念是理解Centernet系列算法的重点,这里做一下解释,模型有一个输出heatmap的head,假设输入图像的尺寸为3x384x512,输出的heatmap尺寸为7x48x64,其中,通道数7代表了预测的目标类别数为7类,48x64表示特征图的大小,这相当于将原图划分成了48x64个区域,每个区域存在一个特征点,如果某个物体的中心落在这个区域,那么就由这个特征点来描述。每一层的特征图的每个特征点都会预测一个数值,通过归一化后,这个数值会被限定在0-1之间,越接近于1,说明这个特征点存在目标物体的概率越大,越接近于0,说明这个特征点是背景的概率越大,可视化示意图如下所示。通过特征图和原图的比例关系,我们可以将最接近于1的特征点映射回原图,这个点就是一个目标的中心点,再加上中心点的offset值,便可以得到最终的中心点坐标。

训练时,需要设置heatmap的真值,目标中心位置的值应该设置为1,而其他位置的值应该设置为0,然而这样设置对于模型的学习难度过大,因为在实际中,中心点的预测有一定的误差也是可以被接受的,想要完全的和目标物的实际中心重合是很难做到的,因此,在实际设置时,目标中心位置的值设置为1,而其周围的值则根据高斯分布逐渐下降到接近0,类似下图。

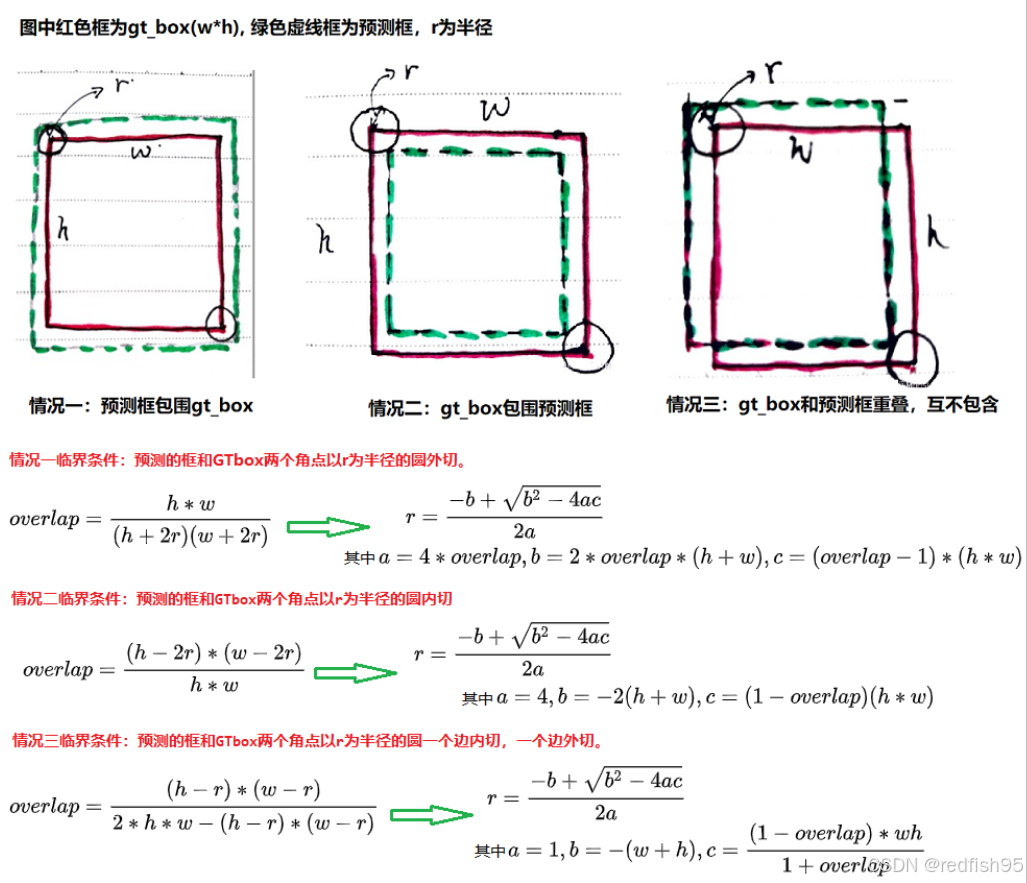
高斯核半径的设置
来源于另外一篇文章cornernet,这篇文章的核心思想是回归2D框的左上和右下的两个角点来得到2D框,其中描述了高斯核半径的算法,而centernet则是直接沿用了该算法,虽然centernet并不是回归角点。具体的算法可参考知乎博文。
简单来说,作者设定了三种临界条件,第一种是预测的框和GT框的两个角点以r为半径的圆外切;第二种是预测的框和GT框的两个角点以r为半径的圆内切;第三种预测的框预测的框和GT框两个角点以r为半径的圆一个边内切,一个边外切。通过设置可以容忍的最小IOU(默认设置0.7),可以计算出三种情况的半径值,选择其中最小的那个作为最终的高斯核半径值。
2D框中心点的offset和2D框的宽高通过模型直接预测;3D框中心点的offset,3D尺寸也是通过模型直接预测。
角度部分
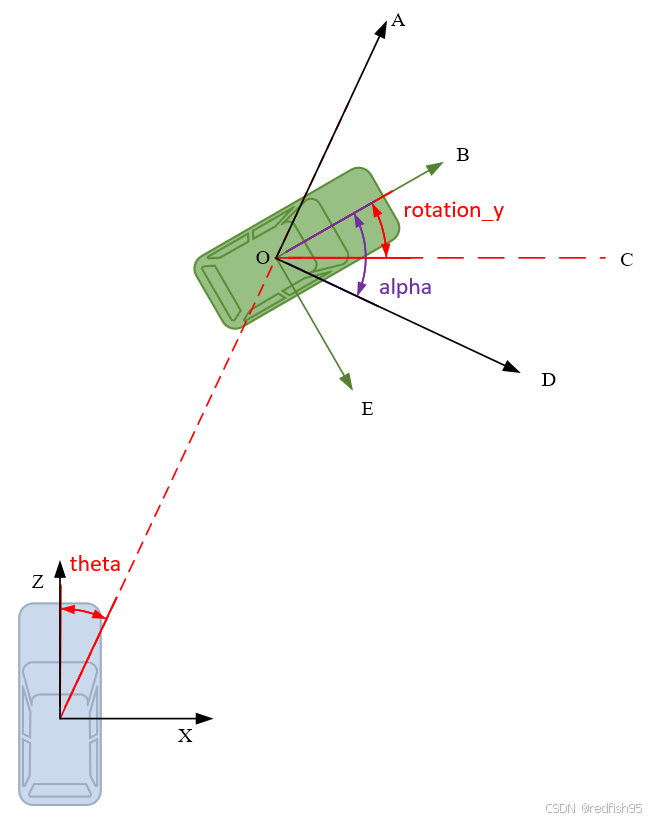
目标的航向角则并不是由模型直接预测的,模型预测的是一个相对角度。直觉的想法是通过模型直接预测一个车辆的航向角,然而,这种做法有一定的问题,如下图所示,小轿车沿着一条直线向前,但是随着位移的变化,从图像的视角来看,车辆好像发生了旋转,这是由于目标车辆和自车相机的相对位置发生了变化,然而目标车辆在世界坐标系下的航向角并没有变化。也就是说,如果我们希望模型直接预测目标车辆在世界坐标系中下的航向角,那么就相当于希望模型通过不同的图像来预测一个不变的角度,这对于模型的学习是不利的。因此我们希望找到一个一对一的映射关系来描述角度。顺着这个思路,我们可以用相机与目标的相对关系来表示车辆的角度。

- 如下图,蓝色为ego vehicle,绿色为目标物体,相机坐标系的z轴向前;
-
方位角theta,定义为自车与目标物体连线偏离自车前进方向的角度;
-
航向角rotation_y,即目标方向和相机X轴正方向的夹角(顺时针方向为正),描述的是目标在现实世界中的朝向。如图∠ B O C 所示。rotaiton_y的取值范围[ − π , π ] ,不随目标位置的变化而变化;
-
观测角alpha, 描述的是目标相对于相机视角的朝向,定义为以相机原点为中心,相机原点到物体中心的连线为半径,将目标旋绕重力轴旋转到目标前进方向与ego vechicle一样时所需的角度,如图∠ B O D 所示。观测角alpha取值范围为[ − π , π ],随目标位置变化而变化。
我们规定模型预测的角度为alpha,由车辆后轴中心可以算得theta角,那么通过公式:alpha = rotation_y − theta 可以得到车辆的航向角。
深度部分
对于深度depth的预测是本文的主要创新点,基本的思路是基于小孔成像原理,通过3d高度h3d和2d框的高度h2d以及焦距f得到深度depth,同时预测深度的偏差以矫正深度值,此外,创造出深度不确定度和高度不确定度加入训练,提高对不确定度的估计。
其理论是,假设投影过程中的
服从拉普拉斯分布,那么预测值是来自于H的一个样本值,这里可以理解为网络的输出位于分布中最高概率的位置,即均值处,但由于分布的方差不一样,该拉普拉斯分布峰值处的概率也不一样,方差高(不确定性高)的分布峰值概率更低。同时,峰值概率也可理解为模型能预测出物体属性(高度)真值的概率。拉普拉斯分布的概率密度公式为
根据拉普拉斯分布的性质,设
,则
,可得
,其中X是归一化的随机变量,对应上式中的Y,因此,
,可以得到深度
的均值为
,其中
是网络预测的3D高度,
是网络预测的2D高度,
为相机焦距,标准差为
为
,即
,其中,
是网络预测得到的3D高度的不确定度,而标准差
的不确定度实际上是
,计算的depth_geo_log_std实际是
,
,计算的depth_net_log_std实际是
,同时模型会预测深度不确定度
,因此可得公式
,这一项就是最终的不确定度,对应公式
。
计算depth_net_out则由两项组成,一项是投影的深度,另一项是深度的修正值,对应公式
,模型最终得到的深度分数为
,而模型最终的预测分数score则为深度分数和2D框分数的乘积。
loss计算
heatmap
heatmap的loss计算(focal loss)公式为:
和
分别是focal loss的超参数,在代码中设置为2和4,N是图像中关键点的个数,
时,表示该点是目标物体的中心点,是正样本点,否则表示该点不是目标物体的中心点,是负样本点。该focal loss针对centernet论文中的loss函数修正而来,和focal loss类似,对应easy example的中心点,适当减少其训练比重也就是loss值。
和
的作用:
限制easy example导致的梯度更新被易区分点所主导的问题。
当
为1时,假如
接近1的话,那么说明这个点是一个比较容易预测的点,那么
当
的作用:
该项是为了平衡正负样本(弱化实际中心点周围的其他负样本的损失比重,加强远离实际中心点周围的负样本的损失比重)
该项和预测的结果没有关系,只和距离中心点的远近有关系,距离中心点越近,真值
对于远离中心点的点,假设
的作用会更加凸显出来,也就是使得离中心点较远的点的损失比重较大,越近的点的损失比重越小,相当于弱化了实际中心点周围的其他负样本的损失比重,加强了远离实际中心点周围的负样本的损失比重。
offset2d/3d和size2d
offset2d/3d 和size2d采用L1loss来计算。
这里以offset2d来进行解释,由于原始图像在经过模型时会进行下采样,这样会造成精度损失,比如对于[512, 512]的图像如果下采样4倍后会变成[128,128]的图像,假设下采样后的中心点坐标为[98.97, 2.36],而由于模型预测出来的热点中心(heatmap)只能是整数,假设预测值为[98,2],那么映射回原图就会存在一定的精度损失,因此为了解决这个问题引入了偏置损失来弥补精度损失。
Depth
深度预测的损失,GUP采用了原创的损失函数:
该损失函数的推导可参考博文https://zhuanlan.zhihu.com/p/545796074,由极大似然估计法推导而来。
size3d
size3d的损失:1/3*depth_loss+2/3*(l_loss+w_loss),也就是说3d的长和宽用L1loss计算,而3d的高用和上面相同的loss函数计算,只不过将深度换成3d的高。
航向角度预测分为两项,一项对heading_bin进行预测,即角度分区,采用cross entropy loss计算损失;一项对heading res进行预测,即角度偏置,采用了l1loss计算损失。
cls_loss(cross_entropy)+regloss(L1loss)(MultiBin loss)
最终将depth loss, offset 3d loss, size3d loss, heading loss加起来组成最终的3d bbox的loss。
Hierarchical Task Learning(HTL)
在GUPNet中,既有2D任务,也有3D任务,因此可以认为这是一个多任务训练,而和普通的多任务训练不同的是,2D任务和3D任务之间并不是互相独立的,而是存在级联关系,或者说是依赖关系,比如前面提到的深度depth的预测就同时依赖于h3d和h2d,如下图所示,因此,如果2D任务或者3D任务训练的不充分,那么会直接影响深度任务的学习。
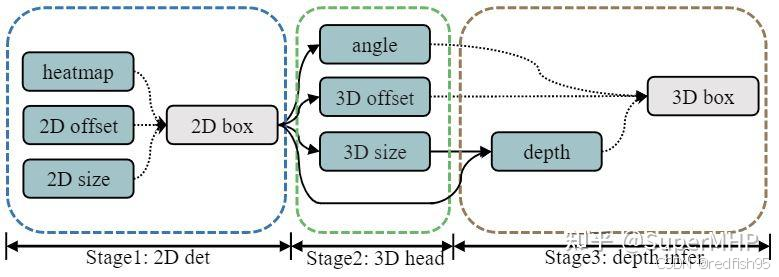
为了解决这个问题,GUPNet设计了HTL,其思路是,一个task的训练要有它的先制任务(pre-task)的训练状态决定,如果先制任务训练完成,则当前任务展开训练。这种做法就类似于学校上课,一年级课程上完了再上二年级一样,所以总得来说,我们需要两个元素实现这件事情:1). 任务学习状态评估:用于评估先制任务的学习状态 2). 当前任务控制器:当先制任务学习达标后,提高当前任务的权重。
pre_task状态评估
对于第j个任务的学习状态的评估,首先计算如下函数:
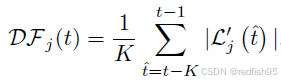
这个函数的本质就是对于一个loss曲线,在t时刻,取一个过去时刻长度为K的滑窗,然后平均每个时刻的变化率(导数),从而获得滑窗内的平均变化率。之后对于该时刻的学习状态评估即为:
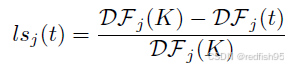
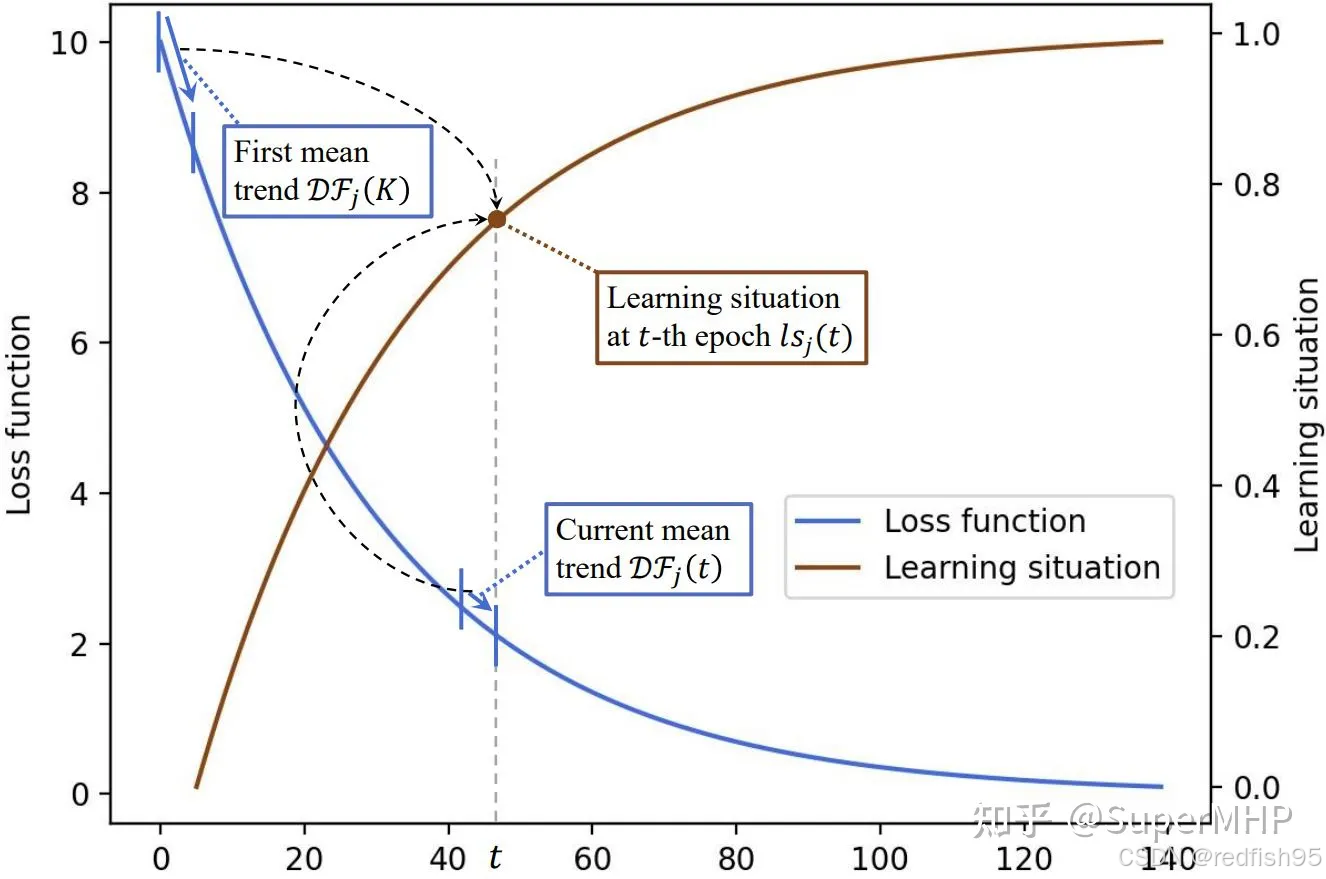
本质上即为比较两个滑窗内变化率的关系,较一致时说明训练不充分,反之则说明训练较为充分。
current_task权重控制
首先计算current_task所有的pre-task的学习状态评估值的乘积,之所以使用该函数是因为形式简单且无需调整超参数
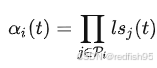
计算current-task权重
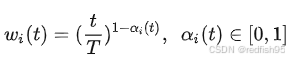
由曲线可以看出,current_task训练权重的增加是平滑的,pre-task训练充分(趋近于1)会加速current_task权重的提升速度
-
-



















 113
113

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









