







 本文提供了一段Python代码,用于单线程下载B站视频。用户输入基础URL和最大视频数量,程序将依次下载所有视频。尽管单线程下载较慢,但代码能确保下载完整。下载完成后,程序会自动删除生成的XML文件。文章强调了多线程下载相比单线程的速度优势。
本文提供了一段Python代码,用于单线程下载B站视频。用户输入基础URL和最大视频数量,程序将依次下载所有视频。尽管单线程下载较慢,但代码能确保下载完整。下载完成后,程序会自动删除生成的XML文件。文章强调了多线程下载相比单线程的速度优势。
背景需求:
最近测试以前的多线程(同时下载5个视频),结果30个视频只下到了3个,所以把“单个下载(单线程下载)”的一个代码加了一个循环遍历数字,实现了下载,但是这种单线程下载非常非常慢。
适用情况:
视频网址前面部分一样,最后的数字逐步增加。
通常这是一套课程、一组动画片等,添加在一个视频列表内

代码演示:
import sys
from you_get import common
'''
视频地址格式为:
https://www.bilibili.com/video/xxxxxxxxxx=1
https://www.bilibili.com/video/xxxxxxxxxx=2
……
https://www.bilibili.com/video//xxxxxxxxxx=28
也就是前面的地址都一样,只有后面的数字不一样(最大数字为28,一共28个视频)
就可以采用以下代码
'''
address=input('网址(无数字)\n')
# 拷贝:“https://www.bilibili.com/video//xxxxxxxxxx?p=”(自己找网址)
sum=int(input('最大数量\n'))
# 28
# name=input(input('名称\n'))
# path = r'D:\test\' # 根据你的物理环境自行设定,不存在的话会自行创建这么一个文件夹
# # 如果savePath不存在,就新建这么一个目录
# if not os.path.exists(path):
# os.makedirs(path)
for i in range (0,sum+1):
#提取信息
def get_i(url):
sys.argv=["you-get","-i",url]
common.main()
#基本下载
def get_o(url,pwd):
sys.argv=["you-get","-o",pwd,url]
common.main()
#指定格式下载
def get_type(url,pwd,type):
sys.argv=["you-get","-F",type,"-o",pwd,url]
common.main()
pwd="D:\\test"
type="dash-flv360"
url="{}{}".format(address,i)
get_o(url,pwd)
# 删除所有XML格式的文件
import glob,os
path =r'D:\test'
for infile in glob.glob(os.path.join(path, '*.xml')):
os.remove(infile)
print(infile+'已删除')
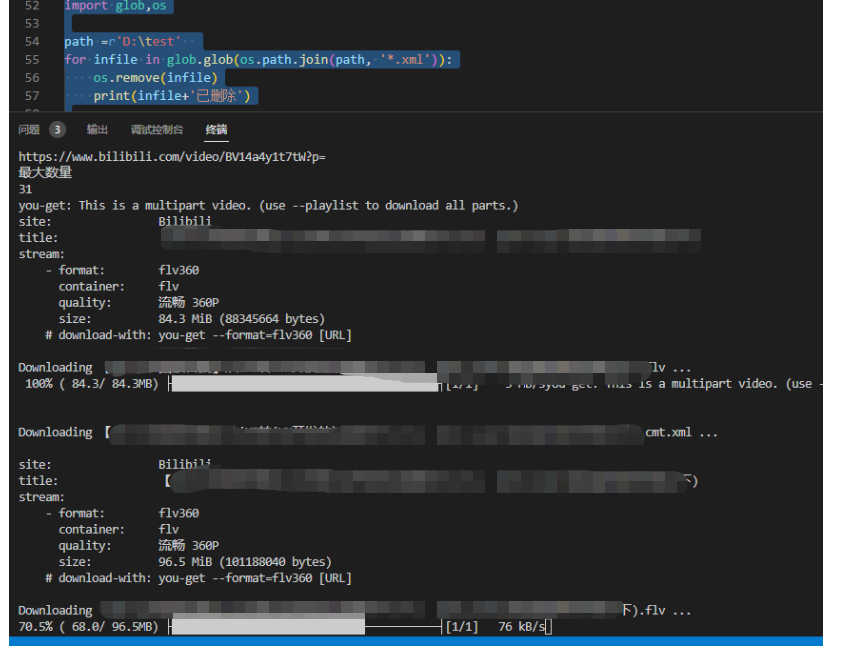
终端展示
:用过多线程下载,再看单线程实在是太慢了,但是能下载已经很不错了!
下载D:/test下
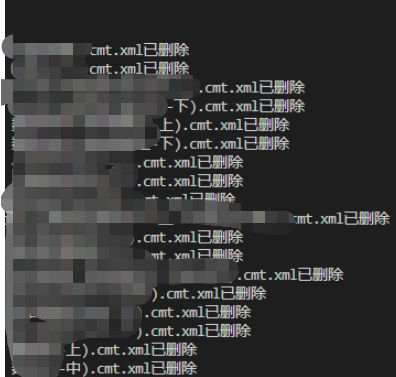
全部下载完成后,程序会删除xml格式文件
用带数字后缀的网址下载视频比较容易。(有一定的规律,遍历数字即可)
 https://blog.youkuaiyun.com/reasonsummer/article/details/129214905?ops_request_misc=&request_id=&biz_id=102&utm_term=%E4%B8%8B%E8%BD%BD%E5%93%94%E5%93%A9%E5%93%94%E5%93%A9%E7%BD%91%E5%9D%80&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-0-129214905.142^v99^pc_search_result_base3&spm=1018.2226.3001.4187
https://blog.youkuaiyun.com/reasonsummer/article/details/129214905?ops_request_misc=&request_id=&biz_id=102&utm_term=%E4%B8%8B%E8%BD%BD%E5%93%94%E5%93%A9%E5%93%94%E5%93%A9%E7%BD%91%E5%9D%80&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-0-129214905.142^v99^pc_search_result_base3&spm=1018.2226.3001.4187



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











