







使用卷积进行文本分类:
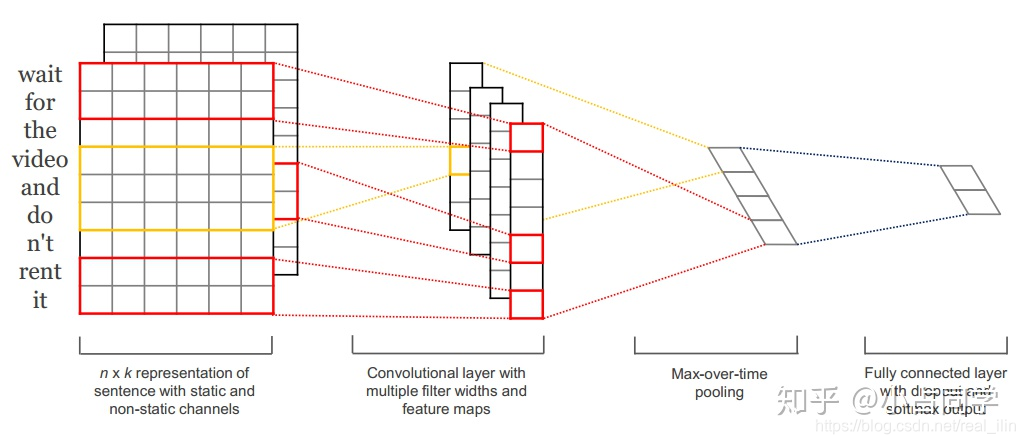
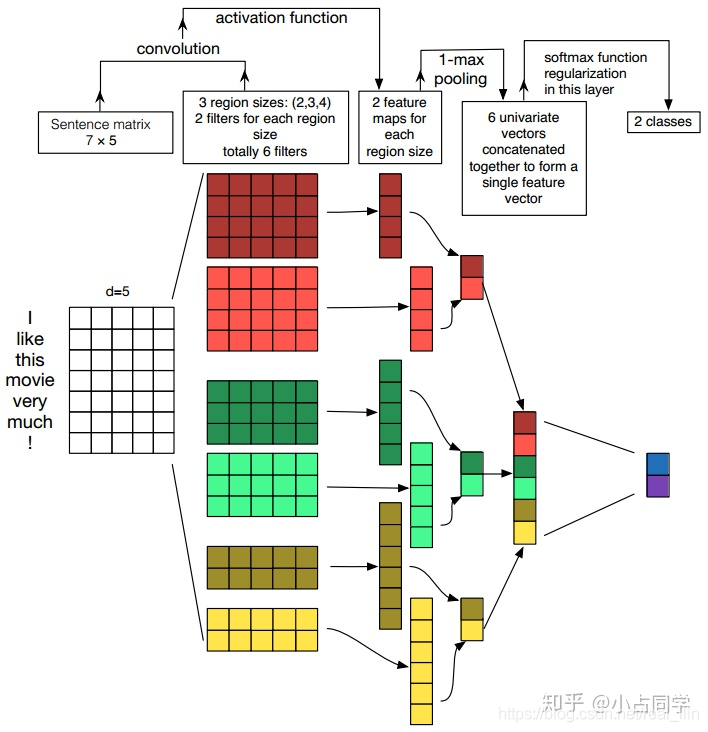
对句子进行Embedding,并进行padding,使得句子长度一致。
网络架构
第一层:Embedding
第一层为输入层。输入层是一个 n ∗ k n *k n∗k 的矩阵,其中 n n n为一个句子中的单词数, k k k是每个词对应的词向量的维度。也就是说,输入层的每一行就是一个单词所对应的 k k k维的词向量。另外,这里为了使向量长度一致对原句子进行了padding操作。我们这里使用 x i x_i xi表示句子中第 i i i 个单词的 k k k维词嵌入。
每个词向量可以是预先在其他语料库中训练好的,也可以作为未知的参数由网络训练得到。这两种方法各有优势,预先训练的词嵌入可以利用其他语料库得到更多的先验知识,而由当前网络训练的词向量能够更好地抓住与当前任务相关联的特征。因此,图中的输入层实际采用了双通道的形式,即有两个 n ∗ k n*k n∗k的输入矩阵,其中一个用预训练好的词嵌入表达,并且在训练过程中不再发生变化;另外一个也由同样的方式初始化,但是会作为参数,随着网络的训练过程发生改变。
第二层 卷积层与池化层


第三层:全连接层 + softmax
得到文本句子的向量表示之后,后面的网络结构就和具体的任务相关了。本例中展示的是一个文本分类的场景,因此最后接入了一个全连接层,并使用Softmax激活函数输出每个类别的概率。
TextCNN中的参数
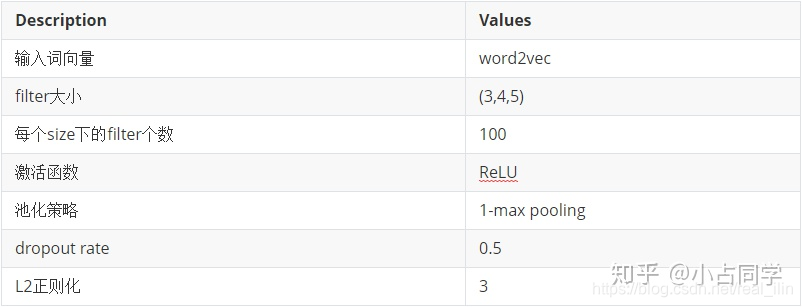
这里将一下调参的问题,主要方法来自论文[2]。在最简单的仅一层卷积的TextCNN结构中,下面的超参数都对模型表现有影响:
- 输入词向量表征:词向量表征的选取(如选word2vec还是GloVe)
- 卷积核大小:一个合理的值范围在1~10。若语料中的句子较长,可以考虑使用更大的卷积核。另外,可以在寻找到了最佳的单个filter的大小后,尝试在该filter的尺寸值附近寻找其他合适值来进行组合。实践证明这样的组合效果往往比单个最佳filter表现更出色
- feature map特征图个数:主要考虑的是当增加特征图个数时,训练时间也会加长,因此需要权衡好。当特征图数量增加到将性能降低时,可以加强正则化效果,如将dropout率提高过0.5
- 激活函数:ReLU和tanh是最佳候选者
- 池化策略:1-max pooling表现最佳
- 正则化项(dropout/L2):相对于其他超参数来说,影响较小点
参考:
https://zhuanlan.zhihu.com/p/77634533
参考论文:
[1] Convolutional Neural Networks for Sentence Classification
[2] A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification

















 1192
1192

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









