




 该博客介绍了如何使用SQL查询从包含开始和结束状态的时间序列数据中计算时间差,特别是如何确保只选取每一对最先出现的开始和结束状态,而不将多个事件合并成一个时间段。
该博客介绍了如何使用SQL查询从包含开始和结束状态的时间序列数据中计算时间差,特别是如何确保只选取每一对最先出现的开始和结束状态,而不将多个事件合并成一个时间段。
【问题】
I have a table structured like this
index date time status
1 2015-01-01 13:00:00 start
2 2015-01-01 13:10:00 continue
3 2015-01-01 13:20:00 continue
4 2015-01-01 13:30:00 end
5 2015-01-01 13:30:00 ready
6 2015-01-01 13:40:00 start
7 2015-01-01 13:50:00 continue
8 2015-01-01 15:00:00 end`and what I would like to do is count the time between start and end (ie. index 1-4 is 30min, 6-8 is 20min), but taking into account only the first start and first end, so that the query doesn’t choose the time difference of index 1-8. Which query is used to calculate time difference between two statues (start-end) and show the result for multiple instances of start-end without them getting batched into one event?
正确答案:
SELECT x.*
, TIMEDIFF(MIN(y.dt),x.dt)diff
FROM my_table x
JOIN my_table y
ON y.dt >= x.dt
WHERE x.status = 'start'
AND y.status = 'end'
GROUP
BY x.id;【回答】
SQL 做这种有序的运算很麻烦,所以可以选用集算器来实现,代码简单易懂:
| A | |
| 1 | $select * from tb1 |
| 2 | =A1.group((#-1)\2) |
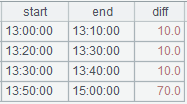
| 3 | =A2.new(~(1).time:start,~(2).time:end,interval@s(start,end)/60:diff) |
A3:计算时间差,生成新序表
集算器提供 JDBC 接口,可以像数据库一样嵌入到应用程序中,用起来很简单,可参考Java 如何调用 SPL 脚本。


















 686
686

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









