




 本文展示了如何使用esProc SPL直接对数据文件进行SQL查询,涵盖过滤、汇总、跨列计算、CASE语句、排序、TOP-N等操作。通过示例解释了如何处理文本文件和Excel文件,包括多个文件的关联查询和复杂计算。
本文展示了如何使用esProc SPL直接对数据文件进行SQL查询,涵盖过滤、汇总、跨列计算、CASE语句、排序、TOP-N等操作。通过示例解释了如何处理文本文件和Excel文件,包括多个文件的关联查询和复杂计算。
在数据分析业务中经常要处理数据文件。我们知道,对于数据库中的数据,使用SQL来查询是非常方便快捷的,所以很容易想到把文件数据先导入到数据库再用SQL来查询。但是文件数据导入数据库本身也是很繁琐的工作,那么有没有直接对数据文件使用SQL查询的办法呢?本文将介绍这样的办法,列举出用 SQL 查询文件数据的各种情况,并提供用 esProc SPL 编写的代码示例。esProc 是专业的数据计算引擎,SPL 中提供了完善的用 SQL 查询文件数据的方法。
本文用文本文件举例,但同时也适用于Excel文件。
1. 过滤
使用SQL从文本文件中筛选满足条件的记录。
示例:从学生成绩表Students_scores.txt中筛选出10班的学生成绩,文件中第一行是列名,第二行开始是数据,如下图所示。

| A | |
|---|---|
| 1 | $select * from E:/txt/Students_scores.txt where class=10 |
2. 汇总
使用SQL对文本文件中的数据进行汇总。
示例:计算学生成绩表中全体学生的语文平均分、数学最高分、英语总分。
| A | |
|---|---|
| 1 | $select avg(Chinese),max(Math),sum(English) from E:/txt/Students_scores.txt |
3. 跨列计算
使用SQL对文本文件中的数据进行跨列计算。
示例:计算学生成绩表中每位学生的总分。
| A | |
|---|---|
| 1 | $select *,English+Chinese+Math as total_score from E:/txt/students_scores.txt |
A1中结果如下,增加了一个新的计算列total_score:

4. CASE语句
在SQL中可以使用CASE语句进行复杂条件计算。
示例:计算学生成绩表中每位同学的英语成绩是否及格。
| A | |
|---|---|
| 1 | $select *, case when English>=60 then 'Pass' else 'Fail' end as English_evaluation from E:/txt/students_scores.txt |
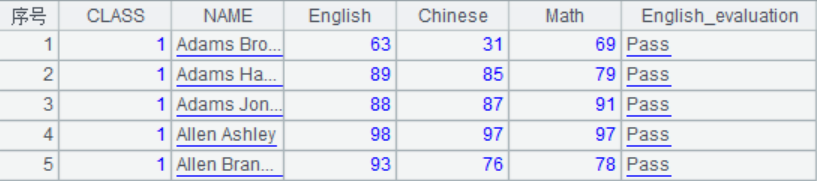
A1中结果如下,增加了一个新的计算列English_evaluation:
5. 排序
使用SQL对文本文件中的数据进行升/降序排序。
示例:将学生成绩表按照班号升序、总分降序的顺序排列。
| A | |
|---|---|
| 1 | $select * from E:/txt/students_scores.txt order by CLASS,English+Chinese+Math desc |
6. TOP-N
使用SQL对文本文件中的数据求TOP-N。
示例:查看英语成绩最高的3个同学成绩。
| A | |
|---|---|
| 1 | $select top 3 * from E:/txt/students_scores.txt order by English desc |
7. 分组汇总
使用SQL对文本文件中的数据进行分组汇总。
示例:查询各班的英语最低分、语文最高分、数学总分。
| A | |
|---|---|
| 1 | $select CLASS,min(English),max(Chinese),sum(Math) from E:/txt/students_scores.txt group by CLASS |
8. 分组后过滤
使用SQL对文本文件中的数据分组汇总后再过滤。
示例:找出英语平均分低于70分的班级。
| A | |
|---|---|
| 1 | $select CLASS,avg(English) as avg_En from E:/txt/students_scores.txt group by CLASS having avg(English)<70 |
A1中查询结果如下:

9. 去重
使用SQL对文本文件中的数据进行去重查询。
示例:查询所有班级编号。
| A | |
|---|---|
| 1 | $select distinct CLASS from E:/txt/students_scores.txt |
10. 去重计数
使用SQL对文本文件中的数据进行去重计数。
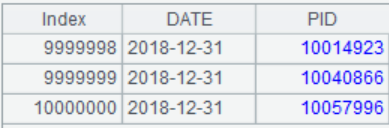
示例:在产品数据文件中,统计共有多少种不同产品。文件部分数据如下所示:
| A | |
|---|---|
| 1 | $select count(distinct PID) from E:/txt/PRODUCT_SALE.txt |
11. 分组去重计数
使用SQL分组对文本文件中的数据分组后进行去重计数。
示例:根据产品销售数据文件,统计每个产品有销售记录的天数。
| A | |
|---|---|
| 1 | $select PID,count(distinct DATE) as no_sdate from E:/txt/PRODUCT_SALE.txt group by PID |
12. 两个文件关联查询
使用SQL对两个文本文件中的数据进行关联查询。
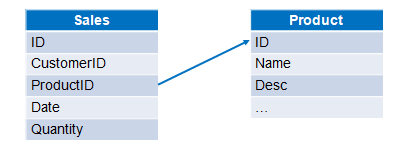
示例:产品信息和销售信息分别存储在两个文本文件中,计算每次销售数量小于10的产品的总销售额。两个文件数据结构如下图:
| A | |
|---|---|
| 1 | $select sum(S.quantity*P.Price) as total from E:/txt/Sales.txt as S join E:/txt/Products.txt as P on S.productid=P.IDwhere S.quantity<=10 |
13. 多个文件关联查询
使用SQL对多个文本文件中的数据进行关联查询。
示例:州信息,部门信息和员工信息分别存储在3个文本文件中,查询California州的HR部门的员工。
| A | |
|---|---|
| 1 | $select e.NAME as NAME from E:/txt/EMPLOYEE_J.txt as e join E:/txt/DEPARTMENT.txt as d on e.DEPTID=d.DEPTID join E:/txt/STATE.txt as s on e.STATEID=s.STATEIDwhere d.NAME='HR' and s.NAME='California' |
14. 多个文件多级关联查询
使用SQL对多个文本文件中的数据进行多级关联查询。
示例:州信息,部门信息和员工信息分别存储在3个文本文件中,查询经理在California州的New York州员工。
| A | |
|---|---|
| 1 | $select e.NAME as ENAME from E:/txt/EMPLOYEE.txt as e join E:/txt/DEPARTMENT.txt as d on e.DEPT=d.NAME join E:/txt/EMPLOYEE.txt as emp on d.MANAGER=emp.EIDwhere e.STATE='New York' and emp.STATE='California' |
15. 嵌套子查询
支持复杂SQL作为子查询。
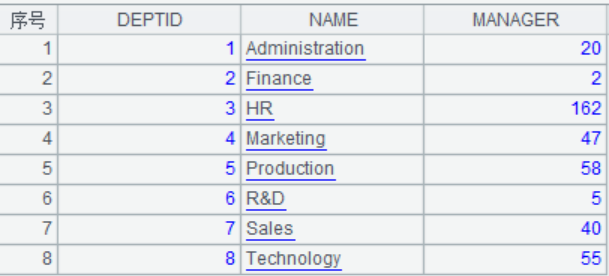
示例:员工信息和部门信息分别存储在2个文本文件中,找出部门经理最年轻的部门。文件部分数据如下图所示:

| A | |
|---|---|
| 1 | $select emp.BIRTHDAY as BIRTHDAY,emp.DEPT as DEPT from E:/txt/DEPARTMENT.txt as dept join E:/txt/EMPLOYEE.txt emp on dept.MANAGER=emp.EIDwhere emp.BIRTHDAY=(select max(BIRTHDAY) from ( select emp1.BIRTHDAY as BIRTHDAY from E:/txt/DEPARTMENT.txt as dept1 join E:/txt/EMPLOYEE.txt as emp1 on dept1.MANAGER=emp1.EID ) ) |
16. 公用表表达式
使用SQL的with子句对文本文件中的数据进行计算。
示例:从部门数据文件中找出指定部门HR、R&D、Sales,再计算这几个部门女员工人数和平均工资。数据文件同上例。
| A | |
|---|---|
| 1 | $with A as (select NAME as DEPT from E:/txt/DEPARTMENT.txtwhere NAME='HR' or NAME='R&D' or NAME='Sales') select A.DEPT DEPT,count(*) NUM,avg(B.SALARY) AVG_SALARY fromA left join E:/txt/EMPLOYEE.txt Bon A.DEPT=B.DEPTwhere B.GENDER='F' group by A.DEPT |


















 686
686

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









