




 本文详细介绍了SPL如何读写文本文件和Excel文件,包括读写结构化文本、字符串序列、Excel表格,以及处理多sheet、文件目录操作等。示例中展示了SPL在排序、追加数据等方面的强大功能。
本文详细介绍了SPL如何读写文本文件和Excel文件,包括读写结构化文本、字符串序列、Excel表格,以及处理多sheet、文件目录操作等。示例中展示了SPL在排序、追加数据等方面的强大功能。
本文介绍SPL读写文本文件和Excel文件的基本方法,包括简单的文件目录操作。
文本文件
读写结构化文本
结构化文本的格式比较规范,即每行一条记录,列之间用分隔符区分。SPL可用import/export函数读写结构化文本。
比如:ordersNT.txt存储订单记录,列之间用制表符tab分隔,业务意义依次为:订单ID、客户编号、销售ID、订单金额、订单日期。部分数据如下:
| 26 TAS 1 2142.4 2009-08-0533 DSGC 1 613.2 2009-08-1484 GC 1 88.5 2009-10-16133 HU 1 1419.8 2010-12-1232 JFS 3 468.0 2009-08-1339 NR 3 3016.0 2010-08-2143 KT 3 2169.0 2009-08-27… |
将该表按客户编号的字母顺序从小到大的排序,相同的客户编号再按订单金额从大到小排序,最后保持原格式存入新文件。部分结果应当如下:
| 136 ARO 25 899.0 2009-12-1616 BDR 27 2464.8 2009-07-2381 BDR 29 1168.0 2010-10-14108 BDR 12 480.0 2010-11-15139 BDR 30 166.0 2010-12-1893 BON 6 2564.4 2010-10-29106 BSF 27 10741.6 2009-11-13… |
要计算出上述结果,可用如下SPL脚本:
| A | |
|---|---|
| 1 | =file("D:/data/ordersNT.txt").import() |
| 2 | =A1.sort(_2,-_4) |
| 3 | =file("D:/data/ordersNT_sort.txt").export(A2) |
A1、A3:读入、写出结构化文本文件。
A2:函数sort进行排序,_2和_4分别代表第2列和第4列,默认按顺序排序,负号代表逆序。
SPL也可以处理带列名(标题)的文本文件。比如orders.txt的第1行为列名,部分数据如下:
| OrderID Client SellerId Amount OrderDate26 TAS 1 2142.4 2009-08-0533 DSGC 1 613.2 2009-08-1484 GC 1 88.5 2009-10-16133 HU 1 1419.8 2010-12-1232 JFS 3 468.0 2009-08-1339 NR 3 3016.0 2010-08-2143 KT 3 2169.0 2009-08-27… |
同样对该文件进行排序,结果带列名写入新文件,可用如下SPL脚本:
| A | |
|---|---|
| 1 | =file("D:/data/orders.txt").import@t() |
| 2 | =A1.sort(Client,-Amount) |
| 3 | =file("D:/data/orders_sort.txt").export@t(A2) |
A1、A3:选项@t表示带列名读入、写出文本文件。
A2:用列名而不是序号进行排序。
函数import/export默认的分隔符是tab,选项@c表示以逗号为分隔符(常用于csv文件)。如果遇到其他特殊分隔符,SPL同样可以处理。比如orders_semi.txt以||为分隔符,可用如下SPL脚本:
| A | |
|---|---|
| 1 | =file("D:/data/orders_semi.txt").import@t(;,"||") |
| 2 | =A1.select(Amount>=1000 && Amount<2010) |
| 3 | =file(""D:/data/orders_semi_select.txt").export@t(A2;"||") |
函数export默认的功能是将数据写入新文件,或覆盖同名文件,但有时候我们需要在原文件后面追加结构相同的新数据,这种情况使用@a选项:
| =file(""D:/data/orders_semi_select.txt").export@at(A2;"||") |
读写字符串序列
有些文本的格式不规范,不能直接进行结构化计算,但可以读为字符串序列。这样的半结构化数据格式繁多,下面用多行记录举例,说明SPL读写字符串序列的一般方法。
文件3lines.txt中每3行的前2行对应一条记录,第3行无用,部分数据如下:
| 26 TAS 1 2142.42009-08-05some comment33 DSGC 1 613.22009-08-14some comment27 TAS 1 2142.42009-08-05some comment |
去掉文件中的无用行,结果写入新文件,可用如下SPL脚本:
| A | |
|---|---|
| 1 | =file("D:/data/3lines.txt").read@n() |
| 2 | =A1.step(3,1,2) |
| 3 | =file("D:/3lines_reuslt.txt").write(A5) |
A1:读入文本文件。@n表示按行读成序列,序列的每个成员对应一行。
A2:对序列A1每隔3个成员取第1个成员和第2个成员。
A3:将序列写入文本文件,序列的每个成员对应一行。
Excel文件
读写结构化表格
结构化的Excel表格比较规范, SPL可用xlsimport/xlsexport函数进行读写。
比如:ordersNT.xlsx中第1个sheet的各列的业务意义依次是订单ID、客户编号、销售ID、订单金额、订单日期。部分数据如下:
| A | B | C | D | E | |
| 1 | 26 | TAS | 1 | 2142.4 | 2009/8/5 |
| 2 | 33 | DSGC | 1 | 613.2 | 2009/8/14 |
| 3 | 84 | GC | 1 | 88.5 | 2009/10/16 |
| 4 | 133 | HU | 1 | 1419.8 | 2010/12/12 |
| 5 | 32 | JFS | 3 | 468 | 2009/8/13 |
| 6 | 39 | NR | 3 | 3016 | 2010/8/21 |
| 7 | 43 | KT | 3 | 2169 | 2009/8/27 |
将该表按客户编号的字母顺序从小到大的排序,相同的客户编号再按订单金额从大到小排序,最后保持原格式存入新Excel。
要计算出上述结果,可用如下SPL脚本:
| A | |
|---|---|
| 1 | =file("D:/data/ordersNT.xlsx").xlsimport() |
| 2 | =A1.sort(_2,-_4) |
| 3 | =file("D:/data/ordersNT_sort.xlsx").xlsexport(A2) |
A1、A3:读写excel的第1个sheet。如果要读入指定sheet,可用xlsimport(;sheet序号或sheet名),如果要写入指定的sheet,可用xlsexport(A2; sheet序号或sheet名)
SPL也可以处理带列名(标题)的结构化表格,方法与文本文件类似。比如orders.xlsx部分数据如下:
| A | B | C | D | E | |
| 1 | OrderID | Client | SellerId | Amount | OrderDate |
| 2 | 26 | TAS | 1 | 2142.4 | 2009/8/5 |
| 3 | 33 | DSGC | 1 | 613.2 | 2009/8/14 |
| 4 | 84 | GC | 1 | 88.5 | 2009/10/16 |
| 5 | 133 | HU | 1 | 1419.8 | 2010/12/12 |
| 6 | 32 | JFS | 3 | 468 | 2009/8/13 |
| 7 | 39 | NR | 3 | 3016 | 2010/8/21 |
| 8 | 43 | KT | 3 | 2169 | 2009/8/27 |
对该文件进行排序,结果带列名写入新文件,可用如下SPL脚本:
| A | |
|---|---|
| 1 | =file("D:/data/orders.xlsx").xlsimport@t() |
| 2 | =A1.sort(Client,-Amount) |
| 3 | =file("D:/data/orders_sort.xlsx").xlsexport@t(A2) |
有时候表格的前几行无用需要跳过,比如下面的数据:
| A | B | C | D | E | |
| 1 | orders from 2009 to 2010 | ||||
| 2 | |||||
| 3 | |||||
| 4 | OrderID | Client | SellerId | Amount | OrderDate |
| 5 | 26 | TAS | 1 | 2142.4 | 2009/8/5 |
| 6 | 33 | DSGC | 1 | 613.2 | 2009/8/14 |
| 7 | 84 | GC | 1 | 88.5 | 2009/10/16 |
| 8 | 133 | HU | 1 | 1419.8 | 2010/12/12 |
| 9 | 32 | JFS | 3 | 468 | 2009/8/13 |
可用下面的SPL脚本,从第4行开始读取:
| =file("D:/data/ orders.xlsx").xlsimport@t(;,4) |
有时候我们需要在原表格后面追加结构相同的新数据,这种情况下只需使用@a选项,形如:
| =file(""D:/data/orders_sort.xlsx").xlsexport@at(A2) |
如果原表格的最后一个有内容的行设置了外观属性,则追加的数据会继承该行的风格。比如原表格D列风格为#,##0.00,E列风格为mmm-dd-yyyy。如下表:
| A | B | C | D | E | |
| 1 | OrderID | Client | SellerId | Amount | OrderDate |
| 2 | 26 | TAS | 1 | 2,142.40 | Aug-05-2009 |
| 3 | 33 | DSGC | 1 | 613.20 | Aug-14-2009 |
| 4 | 84 | GC | 1 | 88.50 | Oct-16-2009 |
则追加数据后,结果如下表:
| A | B | C | D | E | |
| 1 | OrderID | Client | SellerId | Amount | OrderDate |
| 2 | 26 | TAS | 1 | 2,142.40 | Aug-05-2009 |
| 3 | 33 | DSGC | 1 | 613.20 | Aug-14-2009 |
| 4 | 84 | GC | 1 | 88.50 | Oct-16-2009 |
| 5 | 133 | HU | 1 | 1,419.80 | Dec-12-2010 |
| 6 | 32 | JFS | 3 | 468.00 | Aug-13-2009 |
如果原表格最后一个有内容的行之后的第一个空行设置了风格属性,则追加的数据会继承该行的风格属性。利用这个特点,我们可以实现按指定格式从无到有的输出数据。比如先建立空白Excel,设置第2行的D列风格为#,##0.00,E列风格为mmm-dd-yyyy。
| A | B | C | D | E | |
| 1 | OrderID | Client | SellerId | Amount | OrderDate |
| 2 |
再向该空白表格追加数据,结果如下:
| A | B | C | D | E | |
| 1 | OrderID | Client | SellerId | Amount | OrderDate |
| 2 | 133 | HU | 1 | 1,419.80 | Dec-12-2010 |
| 3 | 32 | JFS | 3 | 468.00 | Aug-13-2009 |
读写二维字符串序列
有些Excel的格式不够规范,没有明确的列属性,这种情况下可当作二维字符串序列来处理。
比如下面的key-value数据:
| A | B | C | D | E | |
| 1 | A=123 | B=456 | C=789 | ||
| 2 | A=678 | B=783 | A=900 | U=89 | |
| 3 | A=330 | Y=67 | B=890 | C=311 | F=19 |
现在要将上述数据按key和value拆分为2列,并按key和value排序,最后写入新的Excel。结果如下:
| A | B | |
| 1 | A | 123 |
| 2 | A | 330 |
| 3 | A | 678 |
| 4 | A | 900 |
| 5 | B | 456 |
| 6 | B | 783 |
| 7 | B | 890 |
| 8 | C | 311 |
| 9 | C | 789 |
| 10 | F | 19 |
| 11 | U | 89 |
| 12 | Y | 67 |
要计算出上述结果,可用如下SPL脚本:
| A | |
|---|---|
| 1 | =file("D:/data/keyvalue.xlsx").xlsimport@w() |
| 2 | =A1.conj().select(~) |
| 3 | =A2.(~.split("=")) |
| 4 | =A3.sort(~(1),~(2)) |
| 5 | =file("D:/data/keyvalue_result.xlsx").xlsexport@w(A4) |
A1:读入Excel,@w表示读为二维字符串序列,整体是大序列,每行既是大序列的成员,同时也是个小序列;行内每格是小序列的成员。
A2:将二维序列合并为一维序列,并去除可能的空白格,比如A1、B1、E2。
A3:将字符串序列拆分为key和value。
A4:按key、value排序。
A5:将结果写入新Excel,@w表示写入序列的序列。
读写单元格
前面的内容都是以表格或序列为单位读写Excel,有时候我们也会以精细的单元格为单位读写Excel。
比如:下面的表格在第1行有编辑者和编辑日期。
| A | B | C | D | E | |
| 1 | editor:emily | date:Dec-30-2011 | |||
| 2 | OrderID | Client | SellerId | Amount | OrderDate |
| 3 | 26 | TAS | 1 | 2,142.40 | Aug-05-2009 |
| 4 | 33 | DSGC | 1 | 613.20 | Aug-14-2009 |
| 5 | 84 | GC | 1 | 88.50 | Oct-16-2009 |
| 6 | |||||
| 7 |
现在要将编辑者和编辑日期复制到第7行对应的位置上,结果应当如下:
| A | B | C | D | E | |
| 1 | editor:emily | date:Dec-30-2011 | |||
| 2 | OrderID | Client | SellerId | Amount | OrderDate |
| 3 | 26 | TAS | 1 | 2,142.40 | Aug-05-2009 |
| 4 | 33 | DSGC | 1 | 613.20 | Aug-14-2009 |
| 5 | 84 | GC | 1 | 88.50 | Oct-16-2009 |
| 6 | |||||
| 7 | editor:emily | date:Dec-30-2011 |
要计算出上述结果,可用如下SPL脚本:
| A | B | |
|---|---|---|
| 1 | =file("D:/data/cell.xlsx") | |
| 2 | =A1.xlsopen() | |
| 3 | =str=A2.xlscell("A1") | =A2.xlscell("A7";str) |
| 4 | =str=A2.xlscell("E1") | =A2.xlscell("E7";str) |
| 5 | =A1.xlswrite(A2) |
A2:以对象方式打开Excel文件。
A3:读Excel对象的A1格,赋予变量str。默认从第1个sheet读,如果想读取指定sheet里的A1单元格,可用A2.xlscell("A1",sheet序号或sheet名)
B3:将A1格内容写入A7格。类似地,如果想在指定sheet里写入A7单元格,可用A2.xlscell("A7",sheet序号或sheet名;str)
A4-B4:读E1格内容,并写入E7格
A5:将Excel对象写入Excel文件。
上面例子中,需要读入的A1-E1是连续单元格,需要写入的A7-E7也是连续单元格,对于这种连续单元格的读写,SPL可以用更简化的代码来实现。比如上例的代码可以改成:
| A | |
|---|---|
| 1 | =file("cell.xlsx") |
| 2 | =A1.xlsopen() |
| 3 | =arry=A2.xlscell@w("A1":"E1") |
| 4 | =A2.xlscell("A7":"E7";arry) |
| 5 | =A1.xlswrite(A2) |
A3:以序列的格式读入连续单元格
A4:向连续单元格写入序列,序列的每个成员对应一个单元格。既可以用序列向连续单元格写入数据,也可以用\t或\r分隔的字符串,其中\t表示横向分隔,\r表示纵向(跨行)分隔。
多sheet处理
使用Excel对象,不仅可用读写单元格,也可以处理多个sheet,下面举例说明。
某Excel用多个sheet存储订单表格,每个sheet的格式相同,但数量和名称不定。现在要将这些订单整理到新Excel中,每个sheet存一年的数据。
要计算出上述结果,可用如下SPL脚本:
| A | |
|---|---|
| 1 | =file("orders_sheet.xlsx").xlsopen() |
| 2 | =A1.(stname).(A1.xlsimport@t(;~)).conj() |
| 3 | =A2.group(string(year(OrderDate)):name;~:content) |
| 4 | =file("orders_result.xlsx").xlsopen@w() |
| 5 | =A3.(A4.xlsexport@t(~.content;string(~.name))) |
| 6 | =A4.xlsclose() |
A1:以对象方式打开源Excel文件。
A2:遍历每个sheet,读取每个sheet的订单,再合并所有订单。A1.(stname)表示从Excel对象A1中取出所有的sheet名。
A3:将订单按年份分组。
A4:以对象方式打开目标Excel文件。@w表示写模式,文件不存在时将新建文件。
A5:遍历A3的每组(每年)订单,依次写入到A4的新sheet中。
A6:@w模式打开的Excel对象必须用函数xlsclose关闭。
文件和目录
解析文件名
函数filename可解析出文件名的不同部分:
| A | B | |
|---|---|---|
| 1 | =filename("D://file/test.dfx") | 输出带扩展名的文件名:test.dfx |
| 2 | =filename@e("D://file/test.dfx") | 输出扩展名:dfx |
| 3 | =filename@n("D://file/test.dfx") | 输出无扩展名的文件名:test |
| 4 | =filename@d("D://file/test.dfx") | 输出路径:D://file |
已知文件名的各部分,可用concat函数拼出全路径。比如:
| A | B | |
|---|---|---|
| 1 | =concat("D://file/","test",".dfx") | 输出全路径: D://file/test.dfx |
遍历文件
某目录下有一批Excel文件,这些文件的第1个sheet存储着订单数据,且结构相同。现在要将这些订单合并到新的Excel中。
要计算出上述结果,可用如下SPL脚本:
| A | |
|---|---|
| 1 | =direcotory@p("d:/data/*.xlsx") |
| 2 | =A1.conj(file(~).xlsimport@t()) |
| 3 | =file("d:/result.xlsx").xlsexport@t(A2) |
A1:搜索目录下所有扩展名为xlsx的文件名,@p表示返回全路径。
A2:按文件名循环读入Excel,再合并数据。
函数direcotory还有更多功能,比如用@s选项递归搜索子目录,用@d选项列出子目录,用@r删除目录,用@m创建目录。
系统目录
前面的例子中,我们使用全路径来访问数据文件,如果配置了系统目录中的main path,则可以将main path当作根目录,用相对路径来访问数据文件。具体的配置界面参见下图:
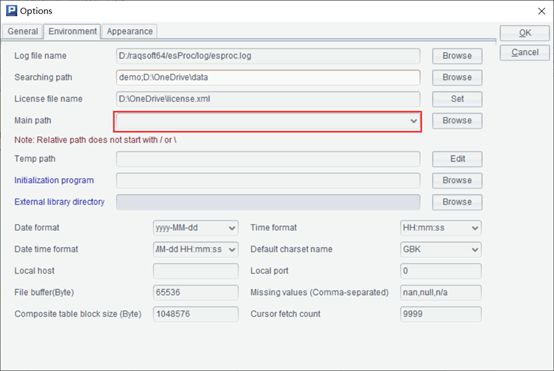
比如,未配置main path时,脚本为:file("d:/data/p/orders.xlsx").xlsimport()
配置main path=d:\data,则脚本可写作:file("p/orders.xlsx").xlsimport()
如果没有配置main path而直接用相对路径,则实际的main path是启动集算器的目录,直接启动集算器时(或通过快捷方式启动),该目录是[集算器安装目录\bin],双击dfx文件间接启动集算器时,该目录是dfx文件所在的目录。使用下面的脚本可验证main path:filename@p("")
除了main path之外,集算器还有其他较为重要的系统目录。
temp:计算引擎存放临时文件的目录,如果没有设置,则默认使用操作系统临时目录。
searching path:脚本文件的根目录,包括了main path,可以设置多个目录,目录之间用分号分隔。


















 686
686

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









