




【摘要】
银行数据查询业务中,经常会碰到数据量很大的清单报表。由于用户输入的查询条件可能很宽泛,因此会从数据库中查出几百上千万甚至过亿行的记录,比如银行流水记录;为了避免内存溢出,一般都会使用关系型数据库的分页机制来做,但结果往往也不尽人意;有些情况下甚至底层采用了非关系型数据库,这更会加剧了问题的复杂度。针对这类场景,集算器能够给你一份满意的答卷!银行业大数据量清单报表案例

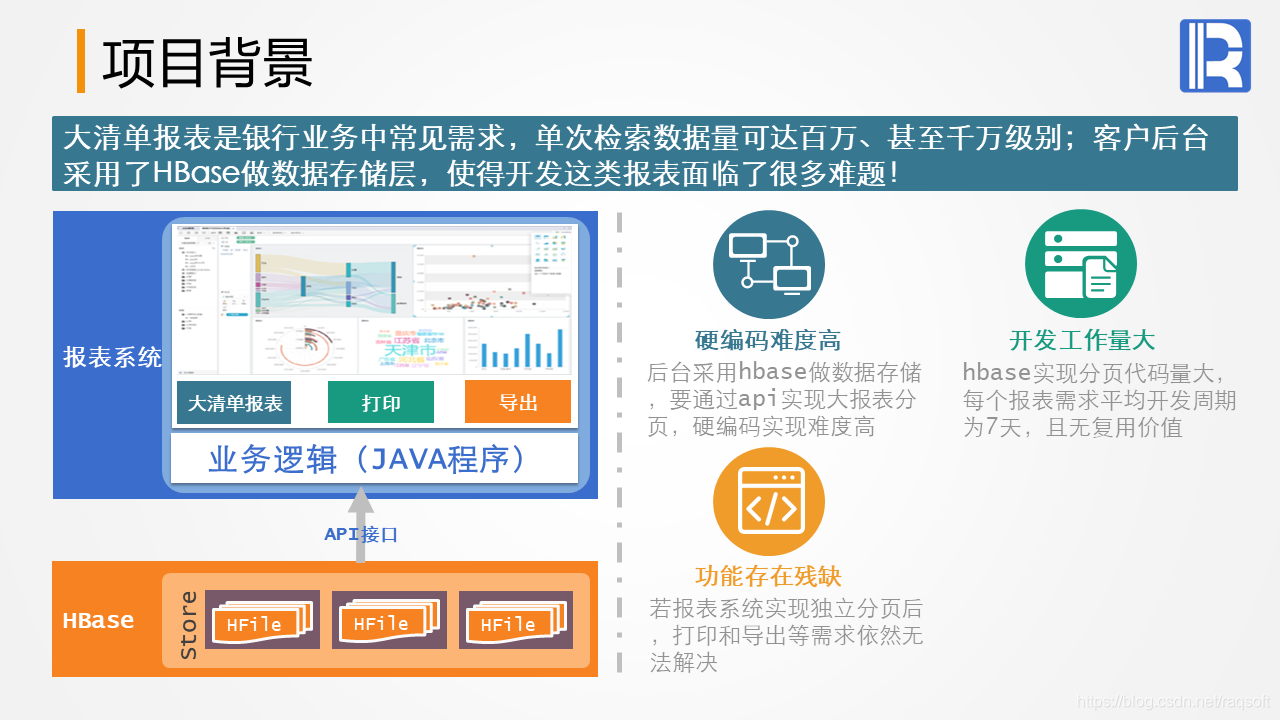
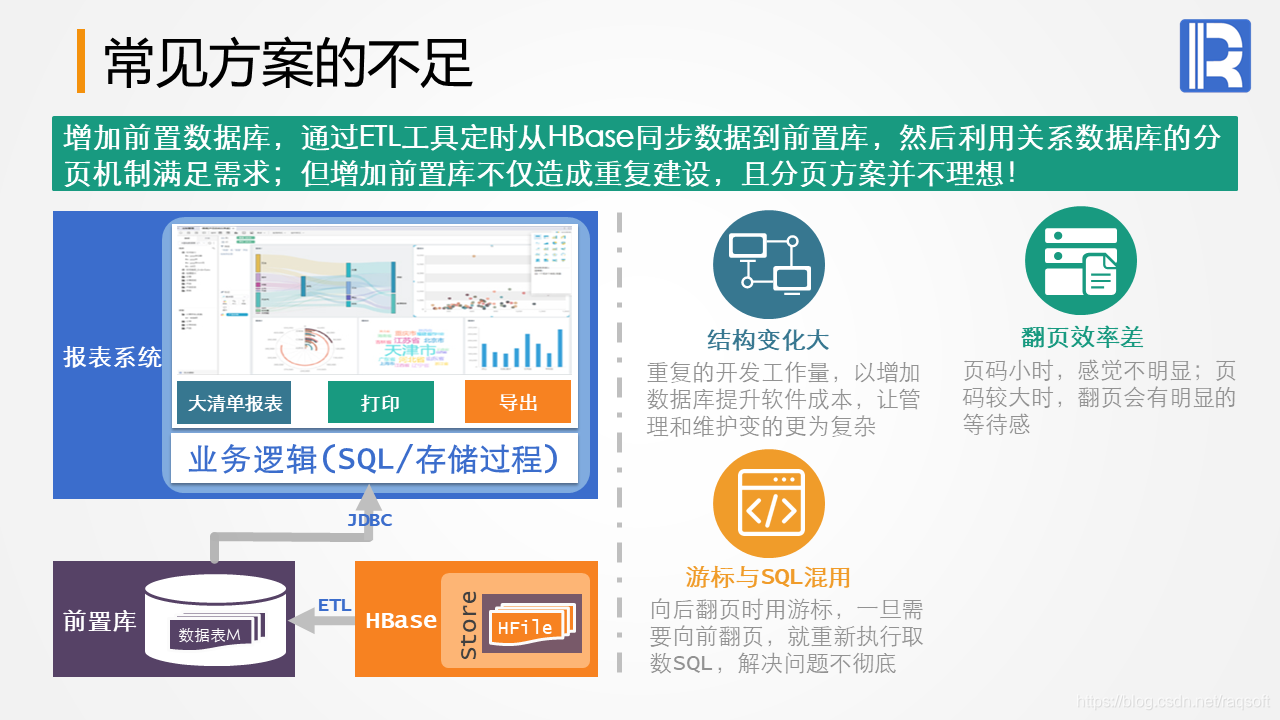
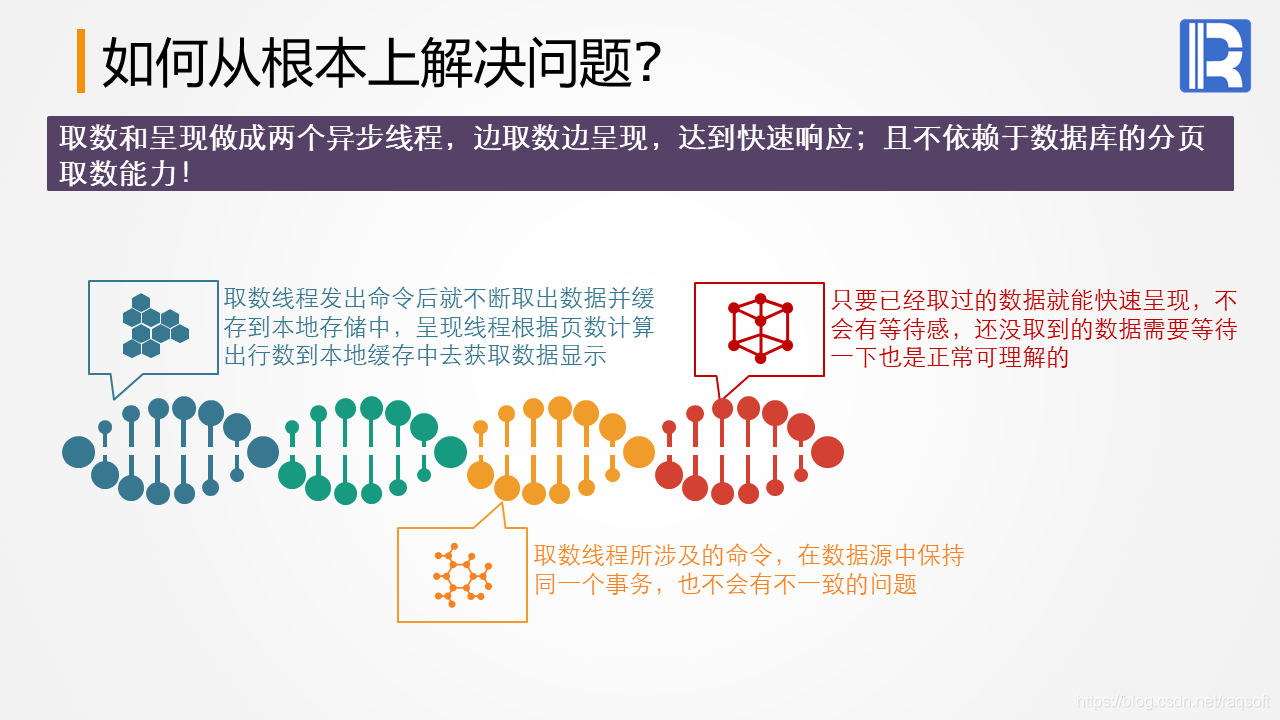
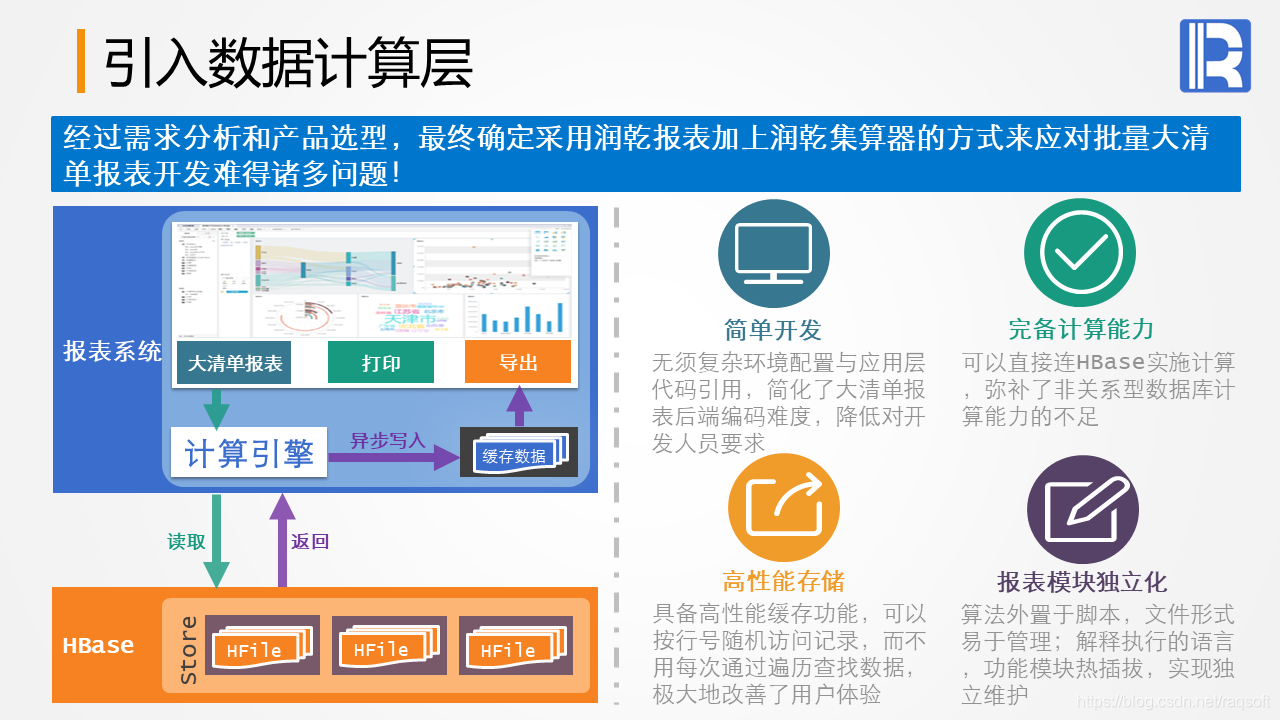
 银行数据查询经常遇到海量清单报表问题,用户广泛查询可能导致数千万到亿级记录。关系型数据库的分页机制效果有限,非关系型数据库更增加复杂性。集算器为这种场景提供高效解决方案。
银行数据查询经常遇到海量清单报表问题,用户广泛查询可能导致数千万到亿级记录。关系型数据库的分页机制效果有限,非关系型数据库更增加复杂性。集算器为这种场景提供高效解决方案。
【摘要】
银行数据查询业务中,经常会碰到数据量很大的清单报表。由于用户输入的查询条件可能很宽泛,因此会从数据库中查出几百上千万甚至过亿行的记录,比如银行流水记录;为了避免内存溢出,一般都会使用关系型数据库的分页机制来做,但结果往往也不尽人意;有些情况下甚至底层采用了非关系型数据库,这更会加剧了问题的复杂度。针对这类场景,集算器能够给你一份满意的答卷!银行业大数据量清单报表案例

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 687
687





