




寻找国内源
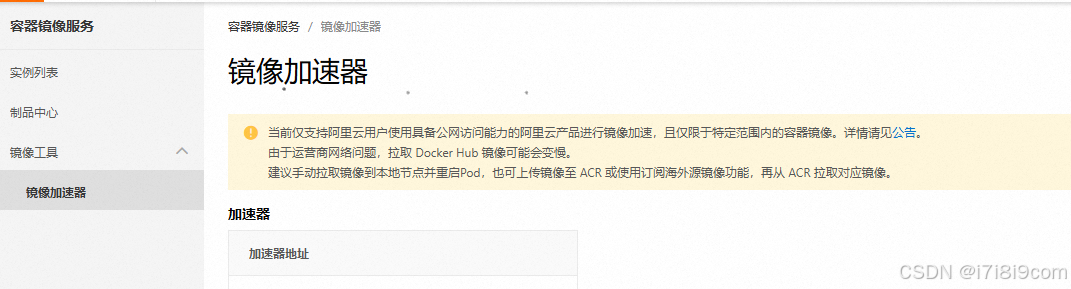
用上面的地址替换下文红色的部分
vi /etc/containers/registries.conf
# 自定义搜索器
unqualified-search-registries = ["docker.io"]
[[registry]]
prefix = "docker.io"
location = "520xxxxx.mirror.aliyuncs.com"
比较难找,可以复制如下文件,只是需要修改上图中的红色部分
# For more infor`mation on this configuration file, see containers-registries.conf(5).
#
# There are multiple versions of the configuration syntax available, where the
# second iteration is backwards compatible to the first one. Mixing up both
# formats will result in an runtime error.
#
# The initial configuration format looks like this:
#
# NOTE: RISK OF USING UNQUALIFIED IMAGE NAMES
# Red Hat recommends always using fully qualified image names including the registry server (full dns name),
# namespace, image name, and tag (ex. registry.redhat.io/ubi8/ubu:latest). When using short names, there is
# always an inherent risk that the image being pulled could be spoofed. For example, a user wants to.
#  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3572
3572

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











