






目录
(九)、可迭代对象(Iterable)和迭代器(Iterator)关系
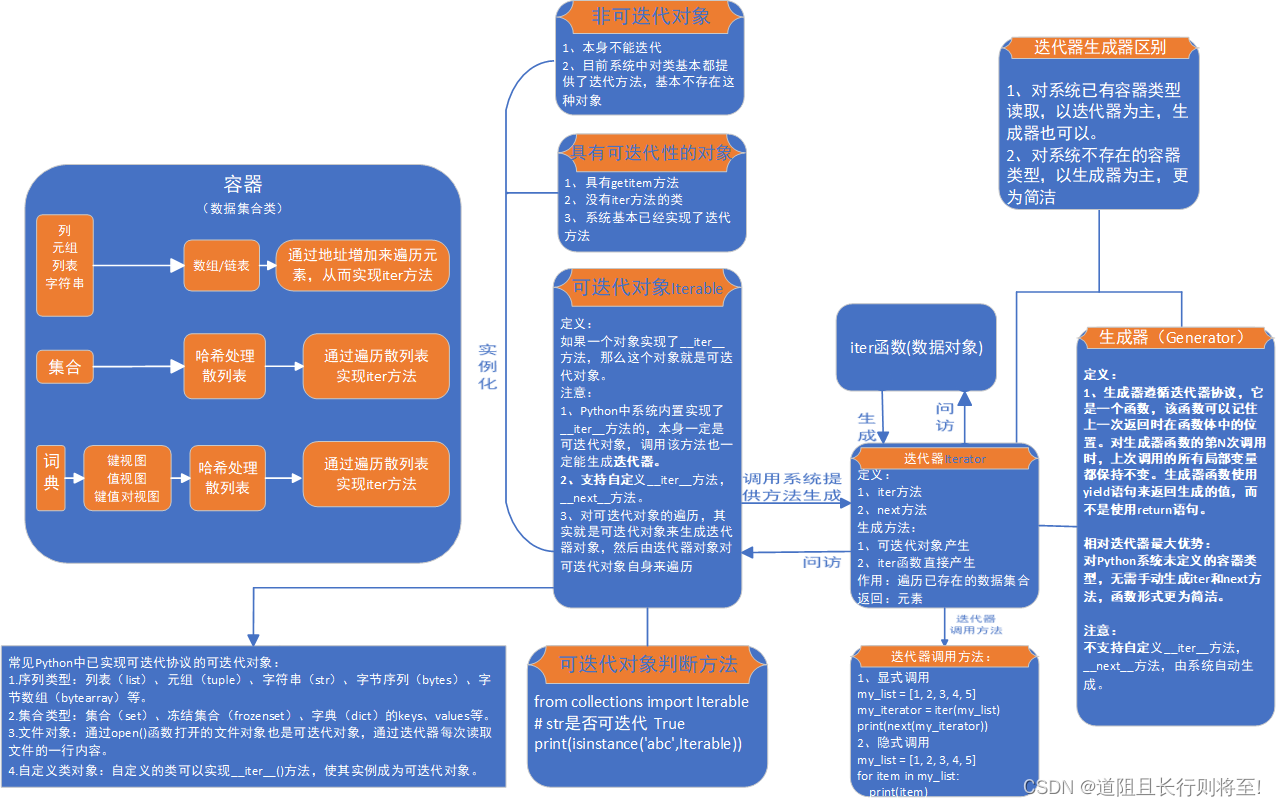
一、容器
(一)、容器定义
容器是一种把多个元素组织在一起的数据结构。容器是包含其他对象的对象,本质是也类。具体的容器就是类的实例化。Python容器类在系统中提供了不同的方法来操作它们所包含的数据,比如添加、删除,查询等。它们都继承自Python的基类,实现了特定的协议(如迭代协议),从而可以进行遍历、索引等操作。
(二)、查看容器对象有哪些方法?(列表为例)
my_list = []
print(dir(my_list))
['__add__', '__class__', '__class_getitem__', '__contains__',
'__delattr__', '__dir__', '__doc__', '__eq__', '__format__',
'__ge__', '__getattribute__', '__getitem__', '__getnewargs__',
'__getstate__', '__gt__', '__hash__', '__init__',
'__init_subclass__', '__iter__', '__le__', '__len__', '__lt__',
'__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__',
'__repr__', '__rmul__', '__setattr__', '__sizeof__', '__str__',
'__subclasshook__', 'count', 'index'](三)、查看对象某个方法功能(列表为例)
my_list = []
#print(dir(my_list))
help(my_list.__class__.clear)
Help on method_descriptor:
clear(self, /)
Remove all items from list.二、迭代
(一)、什么是迭代
迭代是通过重复执行的代码处理相似的数据集的过程,并且本次迭代的处理数据要依赖上一次的结果继续往下做,上一次产生的结果为下一次产生结果的初始状态,如果中途有任何停顿,都不能算是迭代。例如:
1) 非迭代例子
loop = 0
while loop < 3:
print("Hello world!")
loop += 1
2) 迭代例子
loop = 0
while loop < 3:
print(loop)
loop += 1(二)、什么是迭代协议:
Python中的迭代器协议是一种用于定义对象的迭代行为的规范。根据迭代器协议,一个可迭代对象需要实现两个方法:__iter__()方法和__next__()方法。
1、__iter__()方法:
该方法返回一个迭代器对象,用于执行实际的迭代操作。通常在可迭代对象的__iter__()方法中直接返回self即可。
2、__next__()方法:
该方法返回可迭代对象中的下一个元素。当所有元素都被迭代完毕时,抛出StopIteration异常。在每次调用__next__()方法时,迭代器应该更新内部状态以指向下一个元素。
通过实现迭代器协议,可以让对象支持迭代操作,例如在for循环中使用该对象。常见的可迭代对象包括列表、元组、字典等。Python内置的一些数据结构和函数也实现了迭代器协议,例如range()、enumerate()等。
(三)、什么是迭代器
遵循迭代器协议的对象,即是迭代器。
即一个具有中有__iter__方法和__next__方法的对象。
(四)、什么是“对象的可迭代性”
只要具有迭代方式遍历自身成员的方法(比如iter方法、getitem方法)的对象都具有可迭代性。
(五)、什么是“可迭代对象”
具有__iter__()方法的类所生成的对象。
也就是能产生迭代器的类生成的对象。
也就是具有能产生一个迭代读取自己对象数据方法的类产生的对象。
以上本质是一种意思不同角度对迭代对象的表述。
注意:只具有getitem方法生成的对象不是可迭代对象,只能说有可迭代性,可迭代对象必须具体iter方法。
(六)、Python中可迭代容器
可迭代容器:包含由其他对象的地址组成的对象,在python中,又叫序列,包含字符串,列表,元组,用连续地址存贮,直接通过地址增加就可以直接找到下一个元素,因此容易实现迭代功能。
不可迭代容器:比如字典,由散列表实现,散列表本身不能直接实现迭代。但对字典做键值对视图(.items方法),实现字典键值存贮和地址之间映射后来实现迭代功能。
在Python中,对上述容器,系统都已经在容器类中实现了迭代器方法,只要直接用即可。
(七)、Python中常见可迭代对象
1、常见Python系统中已实现可迭代协议的可迭代对象:
1)序列类型:
列表(list)、元组(tuple)、字符串(str)、字节序列(bytes)、字节数组(bytearray)等。
2)集合类型:
集合(set)、字典(键值视图)等。
3)文件对象:
通过open()函数打开的文件对象也是可迭代对象,通过迭代器每次读取文件的一行内容。
2、自定义类对象
自定义的类可以实现__iter__()方法,使其实例成为可迭代对象。比如:
#from collections import Iterable
from collections.abc import Iterable
class testA(object):
def __init__(self, data):
self.data = data
def __iter__(self):
return MyListIterator(self.data)
class MyListIterator(object):
def __init__(self, data):
self.data = data # 上边界
self.now = 0 # 当前迭代值,初始为0
def __iter__(self):
return self # 返回该对象的迭代器类的实例;因为自己就是迭代器,所以返回self
def __next__(self):
if self.now < self.data:
self.now += 1
return self.now
else:
raise StopIteration # 抛出异常StopIteration
# 如果没有抛出异常,则无限循环下去,因为没有返回值
# return None(八)、如何产生迭代器?
1、调用系统方法
调用系统已实现可迭代协议的那些可迭代对象的__iter__方法,生成一个可迭代器协议
注意可迭代对象实例化后并不是迭代器,必须通过调用内置的iter()函数将其转换为迭代器。
2、自己编写一个迭代器
首先写一个可迭代对象类,实现__iter__方法,在iter方法中调用自定义迭代器类
在自定义迭代器类中实现__iter__方法和__next__方法
实例化自编写的可迭代对象类,在可迭代对象中调用iter方法,产生一个迭代器
具体见上述第二节第七条第二目中代码例子
(九)、可迭代对象(Iterable)和迭代器(Iterator)关系
在Python中,可迭代对象是定义了__iter__方法的对象,可迭代对象调用__iter__方法生成迭代对象。同时迭代对象也有__iter__方法,也是一个可迭代对象。
(十)、迭代器的调用方法:
1、显示调用
my_list = [1, 2, 3, 4, 5]
my_iterator = iter(my_list) #返回一个迭代器
print(next(my_iterator)) # 输出 1
print(next(my_iterator)) # 输出 2
print(next(my_iterator)) # 输出 32、隐式调用
Python中,迭代是通过for … in来完成的。凡是可迭代对象都可以直接用for… in…循环访问,这个语句其实做了两件事:第一件事是调用__iter__()获得一个可迭代器,第二件事是循环调用
__next__()。
my_list = [1, 2, 3, 4, 5]
for item in my_list:
print(item)(十一)、迭代器在Python中的必要性
Python中,不用迭代器,所有迭代器功能也能实现,为什么要用迭代器?
比如访问容器数据,可以直接指针;
比如读取大文件,不用加载全部文件,可以一行一行来读取;
我觉得最主要原因,是面向对象设计思想。
1、符合OPP编程思想:
不直接接访问数据,而是提供接口方法访问数据。
2、编程的通用性:
所有元素可以用同一种方法来访问,而不必深入了解每一种数据结构。
3、代码简洁:
包括生成器在内,通过迭代形式代码的包装,使得编程代码更简洁了
至于说有迭代器可以不必一次性的载入数据,可以节省内存,我认为这些说法是错误的。没有迭代器同样无需一次性载入数据。
三、生成器
(一)、什么是生成器?
生成器本质上是一种特殊的迭代器,它自动实现了迭代器协议(python系统实现的,不支持自己重写这两种方法),这意味着它隐式地包含了__iter__和next方法(在Python 3中,next方法实际上应该称为__next__以符合Python的命名规范)。具体来说:
1、生成器__iter__方法:
所有生成器都自动实现(注意:是python系统自动实现)了__iter__方法,当调用一个生成器函数或使用iter()函数作用于生成器时,会返回生成器本身作为一个迭代器对象。因此,生成器可以直接用于任何需要迭代器的上下文中,比如for循环。
2、生成器__next__方法:
生成器通过yield语句来暂停和恢复执行,每次调用生成器的__next__方法(注意:是python系统自动实现的,通常我们直接使用next()函数或者在for循环中隐式调用),会从上次暂停的地方继续执行,直到遇到下一个yield语句,此时yield后的值会被作为__next__方法的返回值。当生成器执行完毕没有更多的yield时,再次调用next()会抛出StopIteration异常,表明迭代完成。
(二)、生成器中yield理解
具有yield关键字的函数都是生成器,yield可以理解为return,返回后面的值给调用者。不同的是return返回后,函数会释放,而生成器则不会。在直接调用next方法或用for语句进行下一次迭代时,生成器会从yield下一句开始执行,直至遇到下一个yield。
(三)、为什么命名为生成器
生成器通过函数yield生成出来,函数暂停,感觉是yield生出来的,而不是return返回的,而且函数状态将会保存起来,所以称为“生成器”
(四)、有了迭代器为什么需要生成器
1、系统已有容器类结构,两者相差不大
很多例子说读大文件时,生成器比迭代器更有优势,其实我觉得没有多大区别。为了处理一个巨大文件并计算每行的长度,而不需要一次性将整个文件加载到内存中,我们可以使用Python的文件对象,因为文件对象本身就是一个迭代器,可以逐行读取文件。下面是一个简单的示例代码,分别用迭代器和生成器展示了如何使用文件对象来完成这个任务:
def compute_line_lengths(filename):
with open(filename, 'r') as file:
for line in file: # 逐行迭代文件
length = len(line) def line_lengths_generator(filename):
2 with open(filename, 'r') as file:
3 for line in file:
4 yield len(line)无论从代码量还是代码简洁性来说,本质没有多大区别,而且都是分步载入,涉及内存容量也没有差别。
2、系统中不存在的容器类,生成器有优势
1)生成器实现前10个斐波那契数
def fibonacci(n):
a, b = 0, 1
while n > 0:
yield a
a, b = b, a + b
n -= 1
# 使用生成器迭代前10个斐波那契数
for num in fibonacci(10):
print(num)2)迭代器实现前10个斐波那契数
class FibonacciIterable:
def __init__(self, n):
self.n = n
self.current = 0
self.next = 1
self.counter = 0
def __iter__(self):
return self
def __next__(self):
if self.counter >= self.n:
raise StopIteration
self.current, self.next = self.next, self.current + self.next
self.counter += 1
return self.current
# 使用迭代器打印前10个斐波那契数
fibonacci = FibonacciIterable(10)
for num in fibonacci:
print(num)由此可见,对于Python中存在的容器类(数据结构),用迭代器和生成器没有多大区别。
对于系统中不存在的数据结构,系统并没有提供iter和next方法,如果用迭代器就要自己实现iter和Next方法。而用生成器则无需自己实现这两个方法,更为简洁。
同时由于生成器是函数,更为灵活,无需去重写一个类。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









