




KNN整理
- KNN(K-Nearest Neighbors)的原理
通过样本之间的距离或者相似度来确定分类。
K值的选择不同,也会引起分类结果的不同,
K = 1:
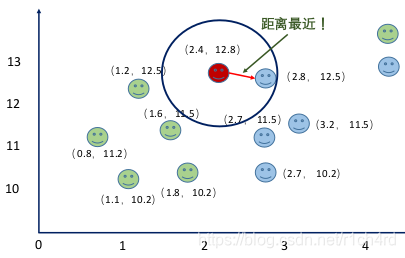
K = 3:

- 距离计算
要度量空间中点距离的话,有好几种度量方式,比如常见的曼哈顿距离计算,欧式距离计算等等。不过通常KNN算法中使用的是欧式距离,这里只是简单说一下,以二维平面为例,二维空间两个点的欧式距离计算公式如下:
d
(
x
,
y
)
=
x
2
+
y
2
d(x,y) = \sqrt{x^2 + y^2}
d(x,y)=x2+y2
拓展到多维空间,公式为:
d
(
X
,
Y
)
=
∑
i
=
1
n
(
x
i
−
y
i
)
2
d(X, Y) = \sqrt{\sum_{i = 1}^{n}{(x_i-y_i)^2}}
d(X,Y)=i=1∑n(xi−yi)2
-
决策边界
决策边界是问题空间的区域,分类器的输出标签是模糊的。如果决策表面是超平面,那么分类问题是线性的,并且类是线性可分的。
KNN中,随着K的增加,决策边界变得更加平滑(smooth) -
K值的选择
方法是用交叉验证(Cross Validation)来确定。
CV方法是:将要训练的数据集分为训练集(training data)、验证集(Validation data)
K-fold交叉验证:
把训练集和验证集分五次划分。其中验证集的采样是随机的,例如三七分(VD30%,TD70%),第一折的数据划分跟第二折不同。

计算后的error取均值,判断K值的取向。 -
特征缩放的方法
1、线性归一化
X n e w = X − X m i n X m a x − X m i n X_{new}=\frac{X-X_{min}}{X_{max}-X_{min}} Xnew=Xmax−XminX−Xmin
2、标准差标准化
X n e w = X − m e a n ( X ) s t d ( X ) X_{new} = \frac{X-mean(X)}{std(X)} Xnew=std(X)X−mean(X)
s t d ( X ) std(X) std(X)为标准差 -
KNN的优缺点(来自知乎作者:终日而思一 )
KNN是一种非参的,惰性的算法模型。什么是非参,什么是惰性呢?
非参的意思并不是说这个算法不需要参数,而是意味着这个模型不会对数据做出任何的假设,与之相对的是线性回归(我们总会假设线性回归是一条直线)。也就是说KNN建立的模型结构是根据数据来决定的,这也比较符合现实的情况,毕竟在现实中的情况往往与理论上的假设是不相符的。
惰性又是什么意思呢?想想看,同样是分类算法,逻辑回归需要先对数据进行大量训练(tranning),最后才会得到一个算法模型。而KNN算法却不需要,它没有明确的训练数据的过程,或者说这个过程很快。 -
KNN算法优点
- 简单易用,相比其他算法,KNN算是比较简洁明了的算法。即使没有很高的数学基础也能搞清楚它的原理。
- 模型训练时间快,上面说到KNN算法是惰性的,这里也就不再过多讲述。
- 预测效果好。对异常值不敏感
- KNN算法缺点
- 对内存要求较高,因为该算法存储了所有训练数据
- 预测阶段可能很慢
- 对不相关的功能和数据规模敏感
- 如何处理大数据
- KD树:适用于低维问题 O ( l o g N ) O(logN) O(logN)
- 利用类似哈希算法 – Locality Sensitivity Hashing (LSH)
牺牲准确率,不求解准确解
核心思想:把样本分在不同的bucket, 使得距离比较近的样本较大概率在同一个bucket里
-
如何处理特征之间的相关性?
曼哈顿距离计算(如果样本特征之间不是相互独立)
Large Margin Loss -
怎么处理样本的重要性?
-
能不能利用Kernel Trick?
从SVM中衍生出的方法
代码实现
def euc_dis(instance1, instance2):
"""
计算两个样本instance1和instance2之间的欧式距离
instance1: 第一个样本, array型
instance2: 第二个样本, array型
"""
# TODO
dist = np.sqrt(sum((instance1 - instance2)**2))
return dist
def knn_classify(X, y, testInstance, k):
"""
给定一个测试数据testInstance, 通过KNN算法来预测它的标签。
X: 训练数据的特征
y: 训练数据的标签
testInstance: 测试数据,这里假定一个测试数据 array型
k: 选择多少个neighbors?
"""
# TODO 返回testInstance的预测标签 = {0,1,2}
distances = [euc_dis(x, testInstance) for x in X]
kneighbors = np.argsort(distances)[:k]
count = Counter(y[kneighbors])
return count.most_common()[0][0]
总结
- KNN是一个非常简单的算法
- 比较适合应用在低维空间
- 预测时候的复杂度高,对于大数据需要一定的处理

















 272
272

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









